01 动机 Motivation
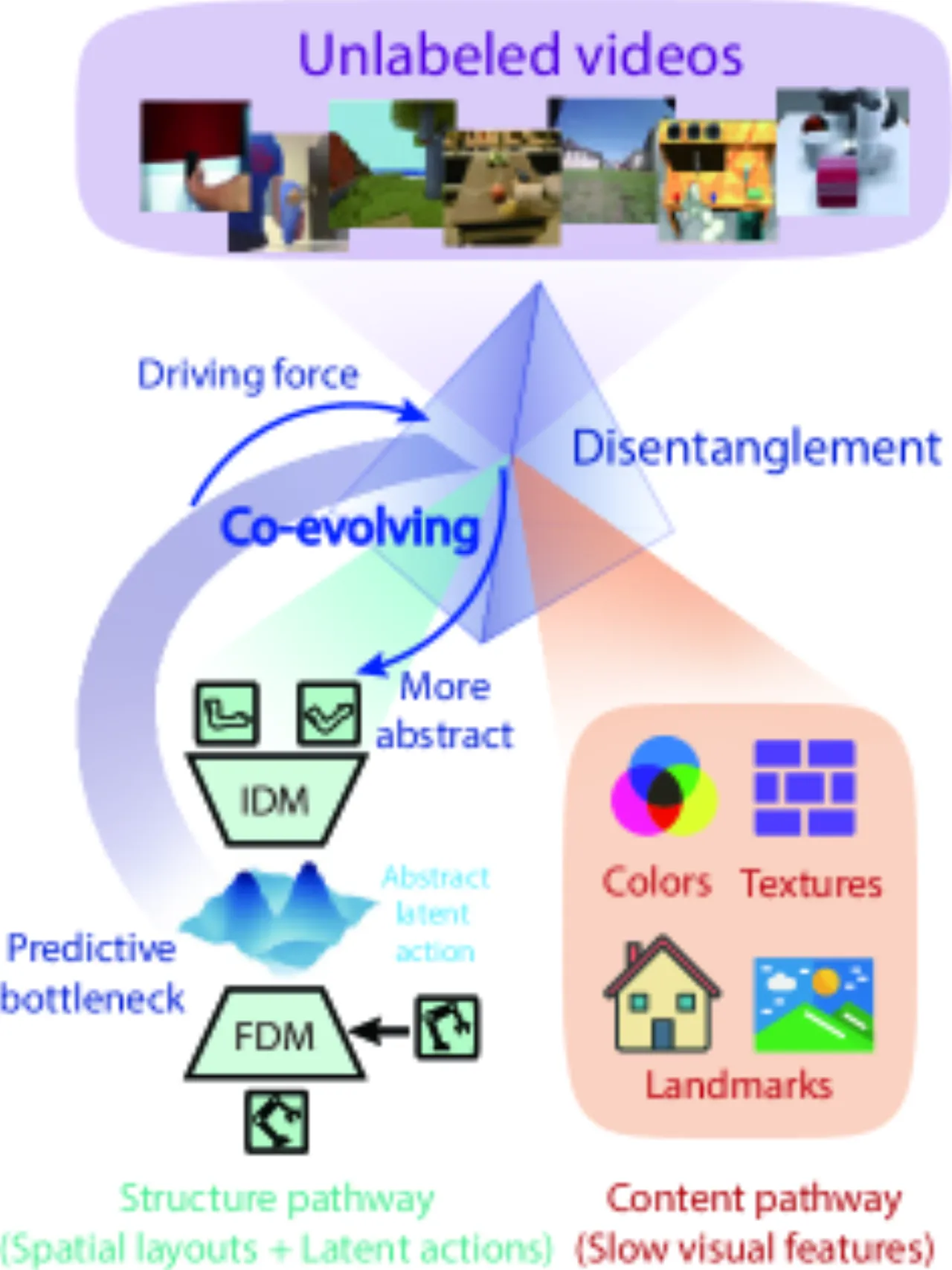
Latent Action Models (LAMs) 是一类以无监督方式从视频中提取潜在动作表示的世界模型。然而,已有方法在动作抽象和生成保真度之间存在难以调和的权衡:通过 Vector Quantization 或 VAE 强化瓶颈可以提升动作抽象质量,却以牺牲视频帧的视觉细节为代价;而保留视觉细节又会导致结构化动作表示退化。
"The predictive bottleneck inherent in latent action learning serves as a driving force for disentanglement."
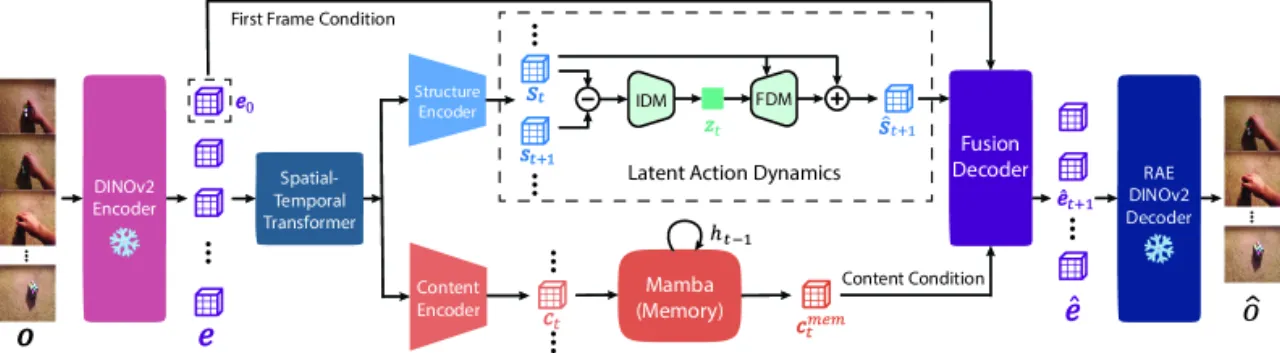
作者将这一现象称为 "LAM Trade-off",并提出核心洞察:仅需预测帧间差异的结构变化即可完成视频预测,这天然驱动了内容与结构的解耦。通过显式地将两条路径分离——结构通道(dynamics)和内容通道(appearance)——DiLA 绕开了这一权衡。
41.44%VP² 视觉规划聚合成功率(vs. AdaWorld 21.54%)
0.774RT-1 SSIM↑(视频生成质量最优)
0.206RT-1 LPIPS↓(感知质量最优)
0.009Push-T Linear Probing MSE↓(动作解码最优)