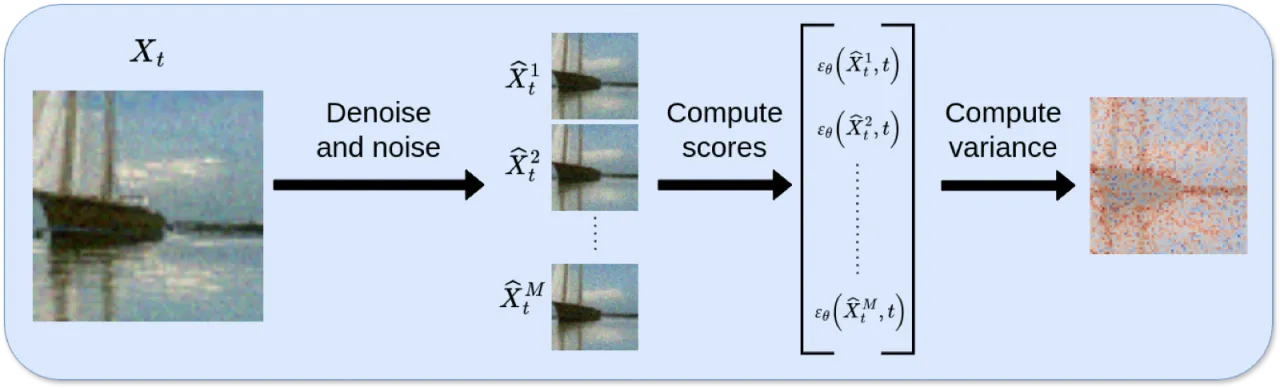
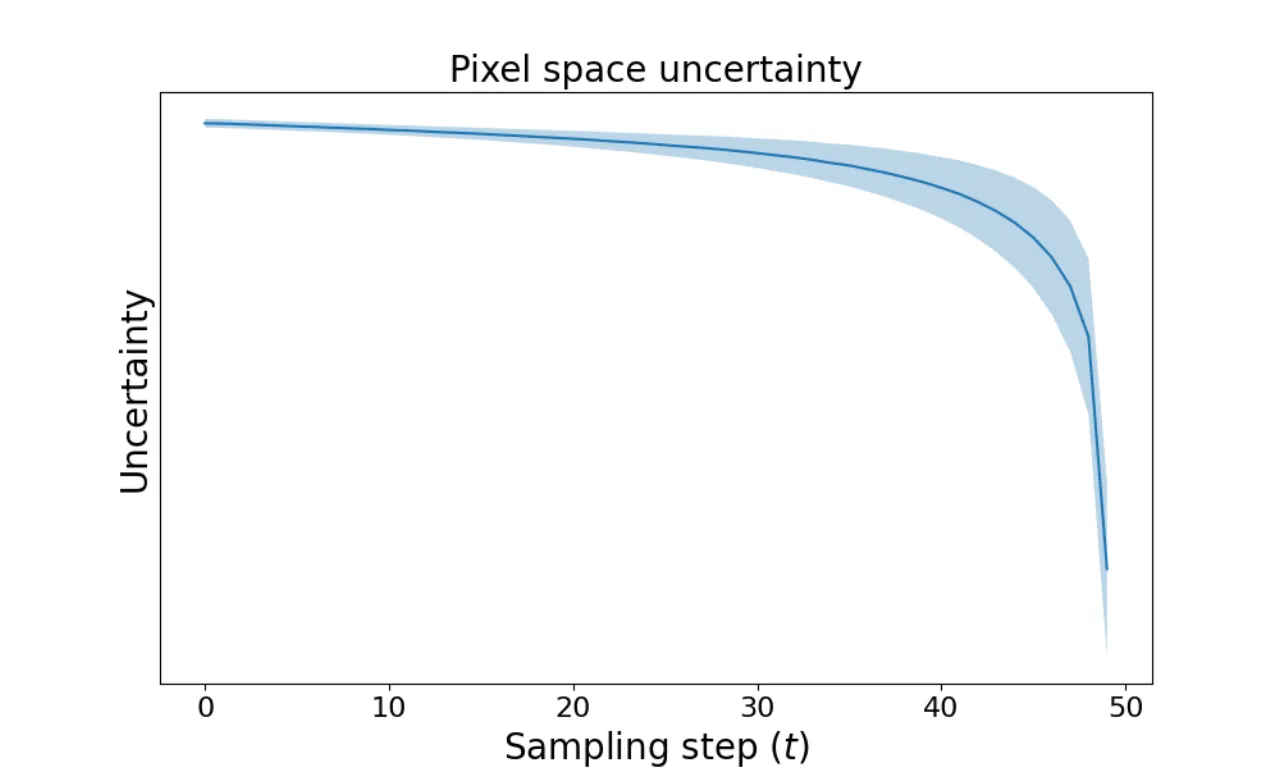
03 实验 Experiments
在 ImageNet(64×64、128×128、256×256、512×512)和 CIFAR-10 上评估,
使用模型:ADM(ImageNet64/128)、U-ViT(ImageNet256/512)、DDPM(CIFAR-10)。
评估指标:FID(图像质量)、AUSE(不确定性校准,越低越好)、AURG(越高越好)。
不确定性过滤(Uncertainty Filtering,Table 1)
从 60,000 张生成图像中按不确定性排序,过滤高不确定性样本后重新计算 FID。
| 模型 | 数据集 | Random(基线) | Ours | BayesDiff | MC-Dropout |
|---|
| ADM | ImageNet64 | 3.289 | 3.254 | — | 3.268 |
| ADM | ImageNet128 | 8.21 | 7.88 | 8.45 | — |
| ADM w/2-DPM | ImageNet128 | 8.50 | 8.48 | 9.67 | — |
| U-ViT | ImageNet256 | 7.88 | 7.80 | 6.81 | — |
| U-ViT | ImageNet512 | 16.47 | 16.37 | 16.87 | — |
| DDPM | CIFAR-10 | 13.494 | 13.416 | — | 13.435 |
注: 在 ImageNet256 上 BayesDiff 取得了更好的 FID(6.81 vs 7.80),本文方法略逊一筹,
但本文方法仅需 20 NFEs,而 BayesDiff 需要 130 NFEs(高出约 6.5×)。
不确定性引导采样(Uncertainty Guided Sampling,Table 3)
在标准采样流程中插入不确定性引导更新,生成 10,000 张图像后比较 FID。
| 模型 | 数据集 | Normal 采样 | Uncertainty-Guided | ΔFID |
|---|
| ADM | ImageNet64 | 24.16 | 23.21 | −0.95 |
| ADM | ImageNet128 | 45.10 | 44.02 | −1.08 |
| DDPM | CIFAR-10 | 27.39 | 26.45 | −0.94 |
| U-ViT | ImageNet256 | 51.45 | 50.34 | −1.11 |
| U-ViT | ImageNet512 | 60.72 | 59.81 | −0.91 |
不确定性校准质量(Table 2,图像重建任务)
| 数据集 | 指标 | Our Method | MC-Dropout |
|---|
| ImageNet64 | AUSE ↓ / AURG ↑ | 74.48 / 5.05 | 84.94 / −4.85 |
| CIFAR-10 | AUSE ↓ / AURG ↑ | 0.01 / 18.48 | 1.27 / 16.19 |
 图4:逐像素不确定性图示例(推断噪声方案)。
高不确定性区域(亮色)集中在图像的边缘、纹理复杂区域,与感知质量问题高度吻合。
图4:逐像素不确定性图示例(推断噪声方案)。
高不确定性区域(亮色)集中在图像的边缘、纹理复杂区域,与感知质量问题高度吻合。
消融实验
作者对分位阈值 p(percentile)和引导强度 λ 进行了超参数扫描。
结果表明:p 在 75–90 分位附近、λ 在较小范围内时效果最稳定。
M(扰动次数)的选择在计算效率与校准精度之间存在权衡:
更大的 M 在 CIFAR-10 和 ImageNet64 上带来边际收益,但增加了计算开销。
 图5:百分位阈值 p 的消融结果。
不同数据集上随着 p 的变化,FID 呈现先下降后上升的趋势,
说明只聚焦于最高不确定性的少数像素时效果最好。
图5:百分位阈值 p 的消融结果。
不同数据集上随着 p 的变化,FID 呈现先下降后上升的趋势,
说明只聚焦于最高不确定性的少数像素时效果最好。