01 动机
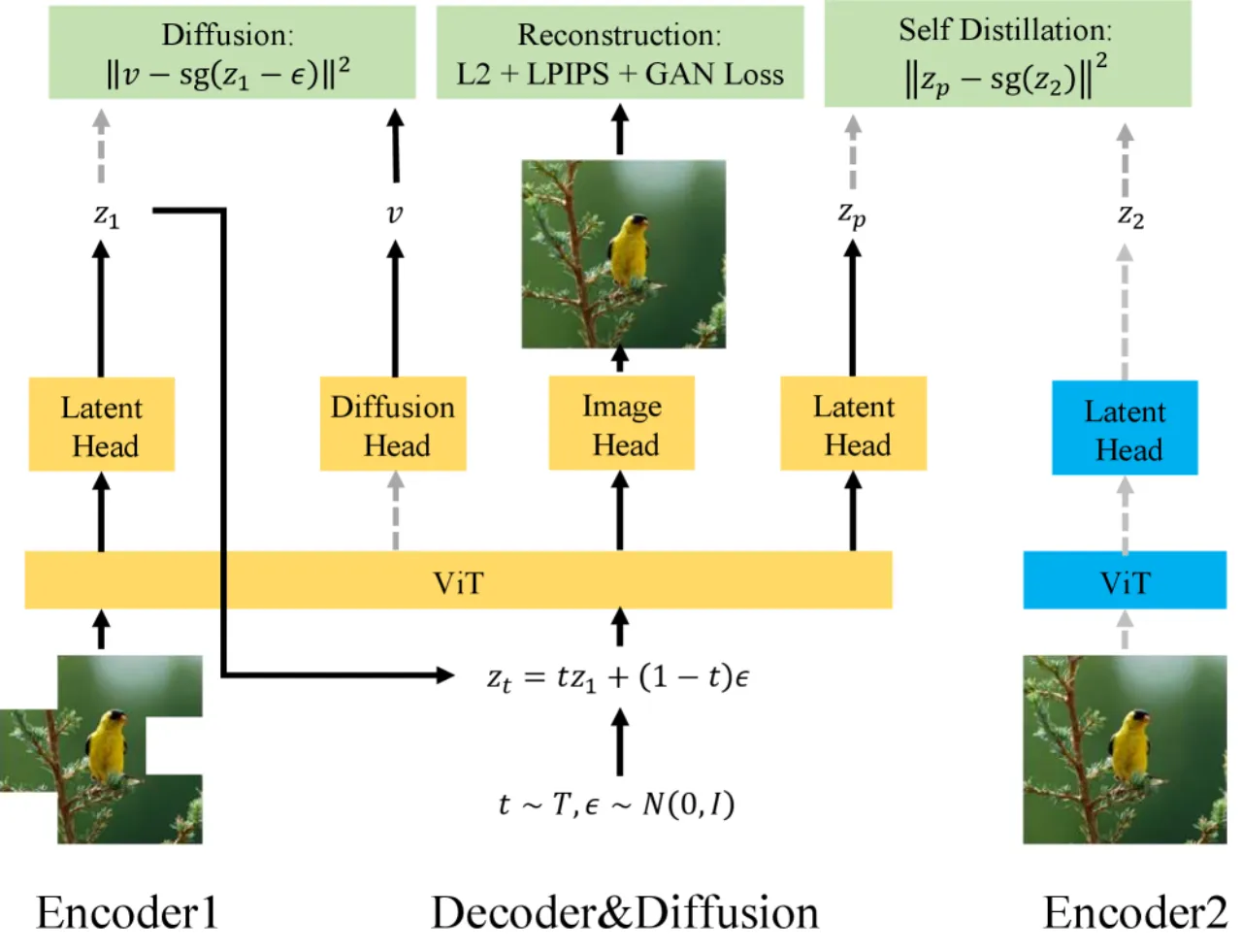
当前主流 Latent Diffusion Model(如 Stable Diffusion、DiT)均依赖"三件套"架构:独立的 VAE 编码器、VAE 解码器与扩散网络,三者依次独立训练。 这一设计带来三大痛点:无法统一到现代视觉基础模型(Vision Foundation Model)、多阶段优化导致次优性能、VAE 组件占用约 20% 参数量并增加推理延迟。 本文将此问题重新定义为一个无监督表征学习挑战,并借鉴 Self-Distillation 方法(如 DINO、SimSiam)避免表征坍塌的机制,提出端到端联合训练方案。
"We unify these three components into a single trainable network, enabling end-to-end optimization and integration with modern vision foundation models."
4.25DSD-B FID(无 CFG)
ImageNet 256×256
ImageNet 256×256
3.35DSD-B FID(有 CFG)
50 epochs
50 epochs
205MDSD-B 全部参数
(含 encoder+decoder+diffusion)
(含 encoder+decoder+diffusion)
50训练 epochs
vs. 基线 800–1400 epochs
vs. 基线 800–1400 epochs
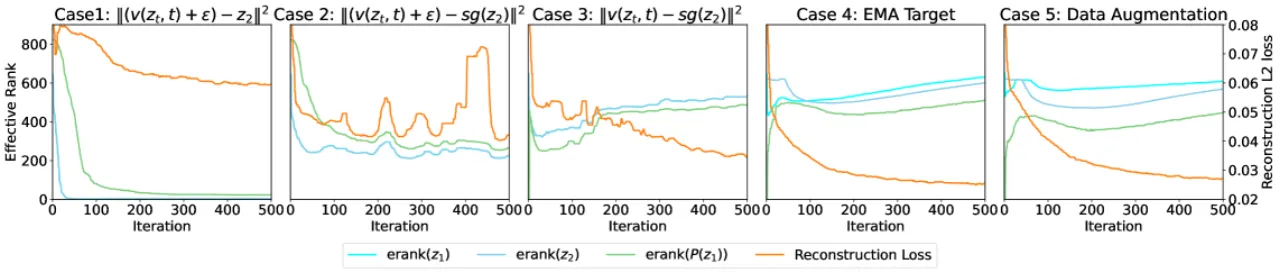
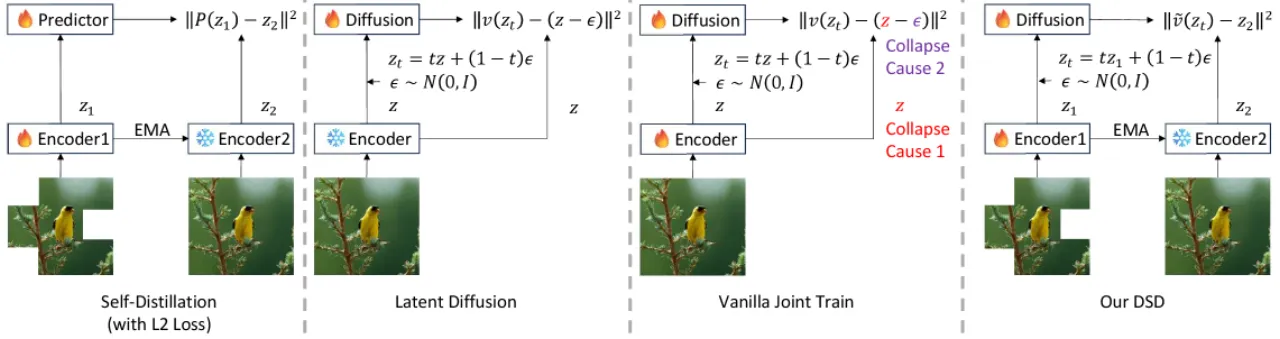
为什么朴素联合训练会失败?
直接将 VAE 与扩散网络进行端到端联合训练会导致 Latent Collapse——潜变量的有效秩(effective rank)骤降至接近 1,表征退化,生成质量崩溃。 论文识别出两个根本原因:
原因一:潜变量方差压制
L2 扩散损失隐式包含方差惩罚项,迫使编码器将所有潜变量压缩至均值附近,导致表征空间坍塌。
原因二:秩差异条件违反
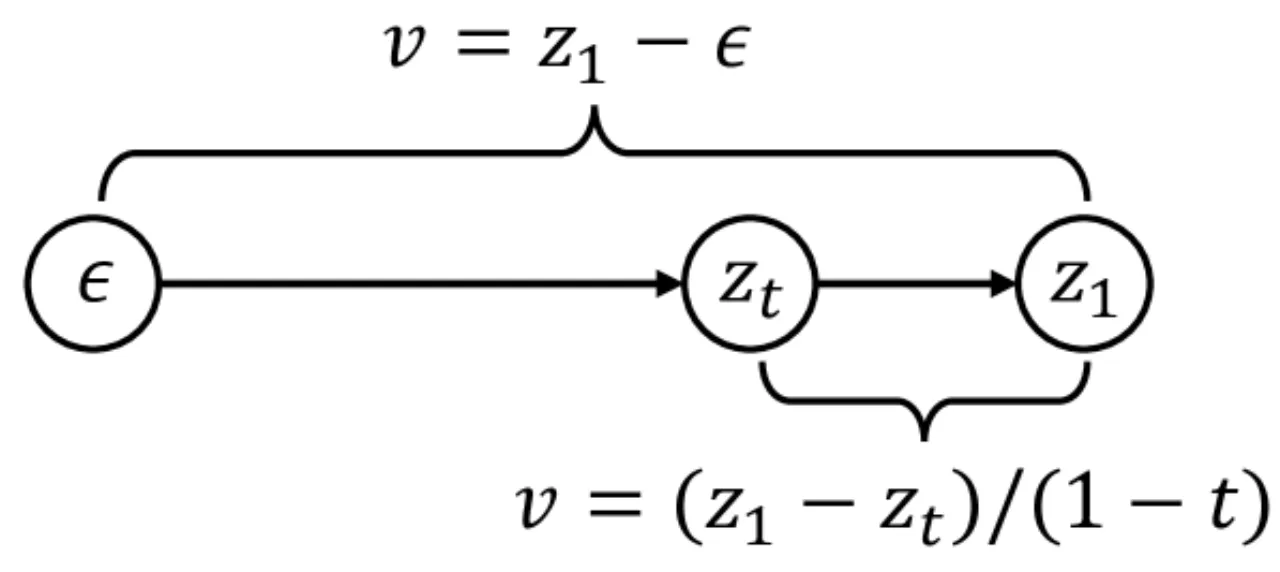
Self-Distillation 理论要求 erank(z₂) > erank(P(z₁,t,ε))。标准速度预测(velocity prediction)输出全秩噪声,打破此条件,稳定机制失效。