01 动机
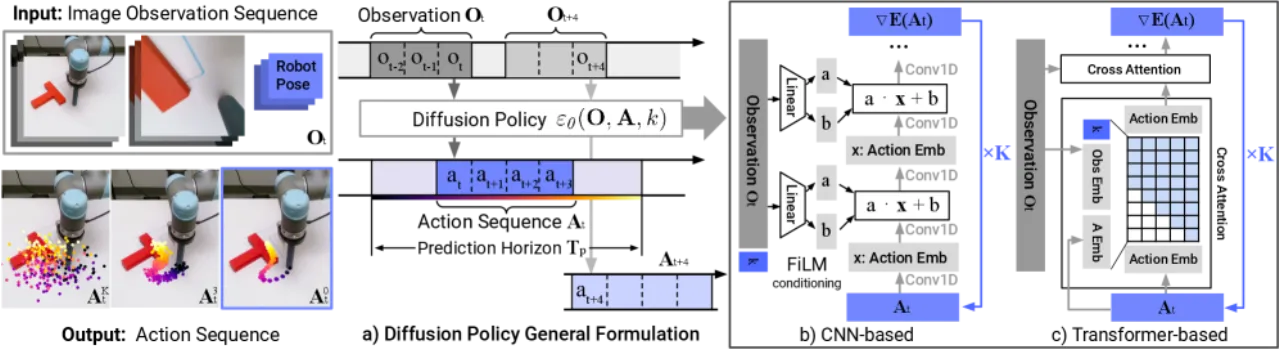
机器人 visuomotor 策略学习面临三大核心挑战:多模态动作分布(同一状态存在多种合理行为)、 高维动作序列的时序相关性以及高精度控制要求。 现有方法(显式策略、IBC 隐式策略、BET 序列模型)各有缺陷,均难以同时满足这三点。
"This work presents Diffusion Policy, a new way of generating robot behavior by representing a robot's visuomotor policy as a conditional denoising diffusion process on robot action space."
+46.9%平均超越现有 SOTA
(15 个任务)
(15 个任务)
95%真实 Push-T 任务
成功率(E2E Trans)
成功率(E2E Trans)
0.80真实 Push-T 的 IoU
(人类示范 0.84)
(人类示范 0.84)
12测试任务总数
(含双臂操作)
(含双臂操作)
为什么现有方法不够用?
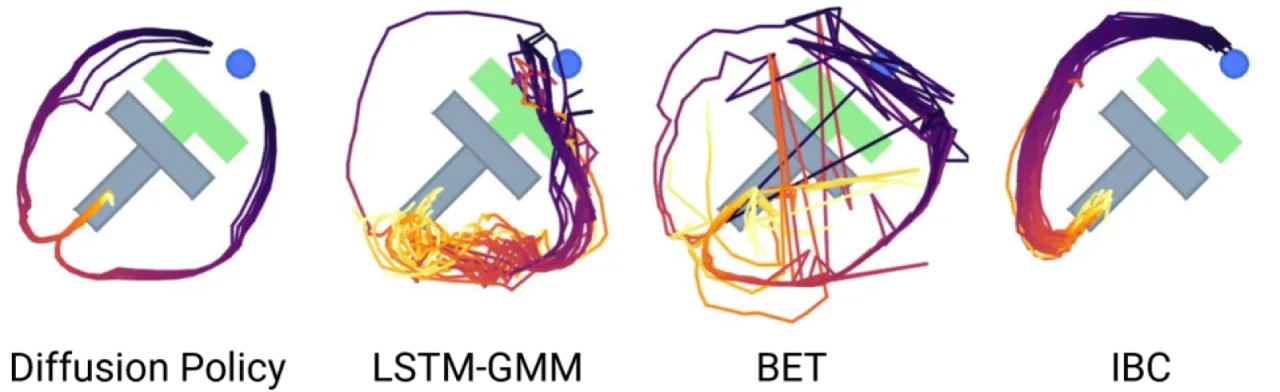
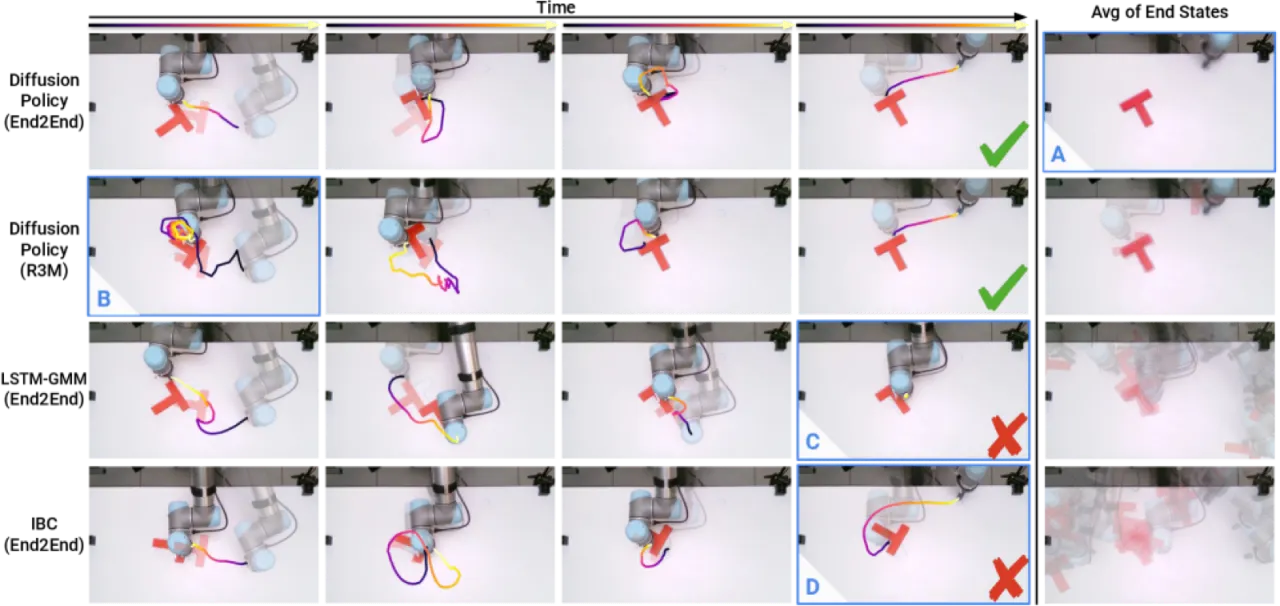
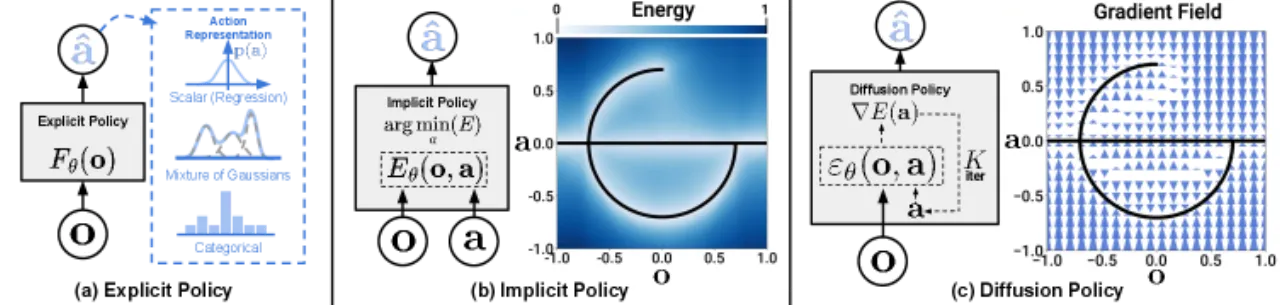
显式策略(BC / LSTM-GMM / BET)
- GMM 等混合模型建模能力有限,难以捕捉复杂多峰分布
- BET(Behavior Transformer)在精细操作任务中准确率显著下降
- 高精度任务(如 Square、ToolHang)成功率偏低
隐式策略(IBC)
- 训练极不稳定:训练 loss 下降,但策略成功率剧烈震荡,难以选择 checkpoint
- 推理时需要优化能量函数,计算开销大且容易陷入局部极小
- 在仿真多个任务上成功率接近 0%