02 方法Diffuser 以整条轨迹 τ = (s₀, a₀, s₁, a₁, …, sₜ, aₜ) 作为建模单元,用扩散模型学习轨迹的数据分布 p(τ),然后在推理时通过 classifier-guided sampling 或 inpainting 将规划条件(奖励、目标状态)注入采样过程,从而直接输出高质量的未来行动序列。
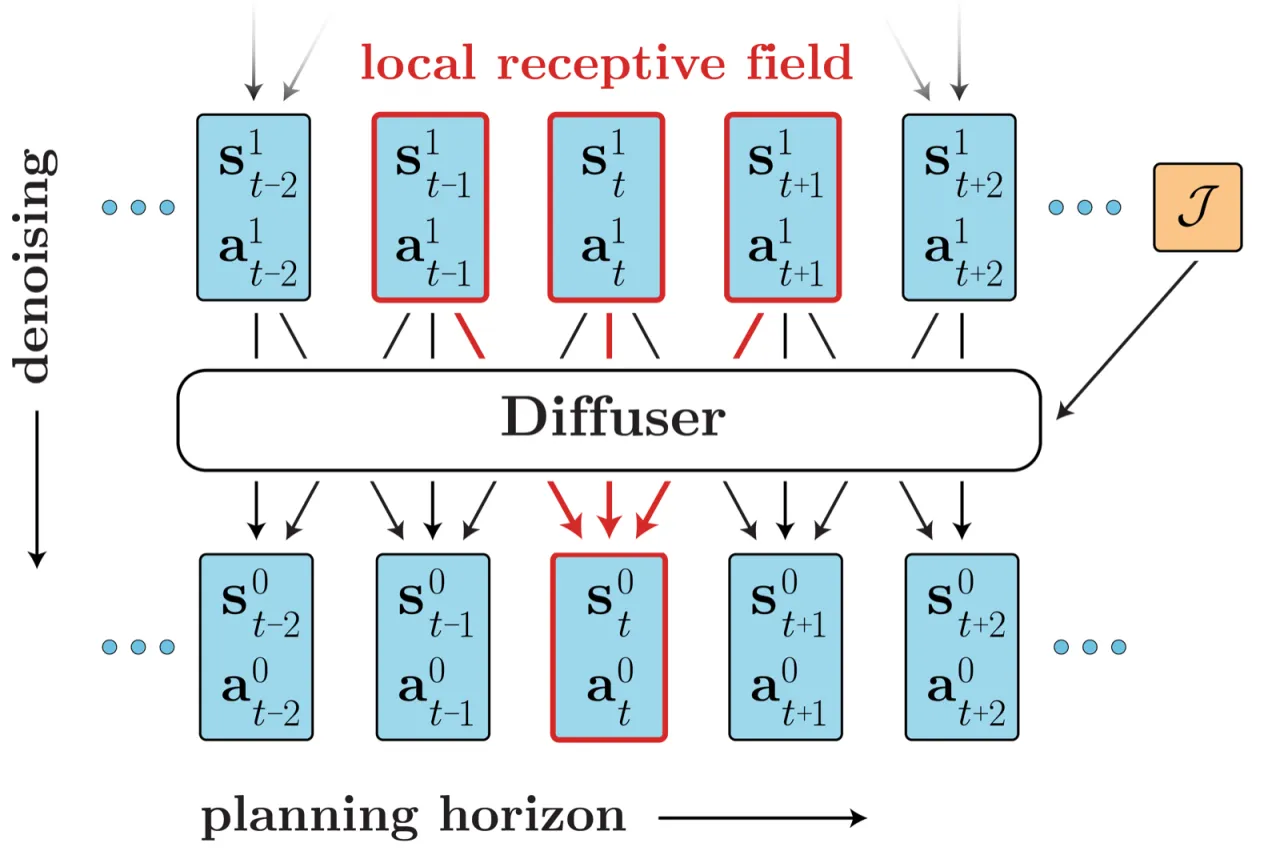
Figure 2. Diffuser 架构示意图。模型以整段轨迹为输入,在 planning horizon 维度展开,采用 local receptive field(时域卷积)在相邻时步间传递信息。去噪过程从上往下迭代,逐步精化噪声轨迹;可选的目标函数 J 通过梯度引导采样方向。
轨迹表示(Trajectory Representation)
Diffuser 将轨迹表示为二维数组 τ ∈ ℝT×(|s|+|a|) ,行为时间步,列为拼接的 state-action 向量。这一表示使 state 与 action 完全对等,模型对二者联合去噪,而非像传统动力学模型那样只预测 state。规划时先采样整条轨迹,再执行第一个 action——类似于 model-predictive control(MPC)的 receding-horizon 执行。
扩散模型(Diffusion Probabilistic Model)
前向过程(forward process)逐步向轨迹加高斯噪声,参数化为 q(τi | τi-1 ) = N(τi ; √(1-β_i) τi-1 , β_i I)。反向过程(reverse process)由参数 θ 优化,学习去噪转移 p_θ(τi-1 | τi )。网络 ε_θ(τi , i) 预测每步残差噪声,损失为:L = E_{i,τ⁰,ε} [‖ε - ε_θ(τi , i)‖²]。网络骨干借鉴 U-Net 思路,使用全时域卷积(temporal convolutions)处理轨迹序列,local receptive field 在相邻时步间共享信息而不依赖全局 attention,保证推理效率。
规划策略 1:Classifier-Guided Sampling(奖励引导)
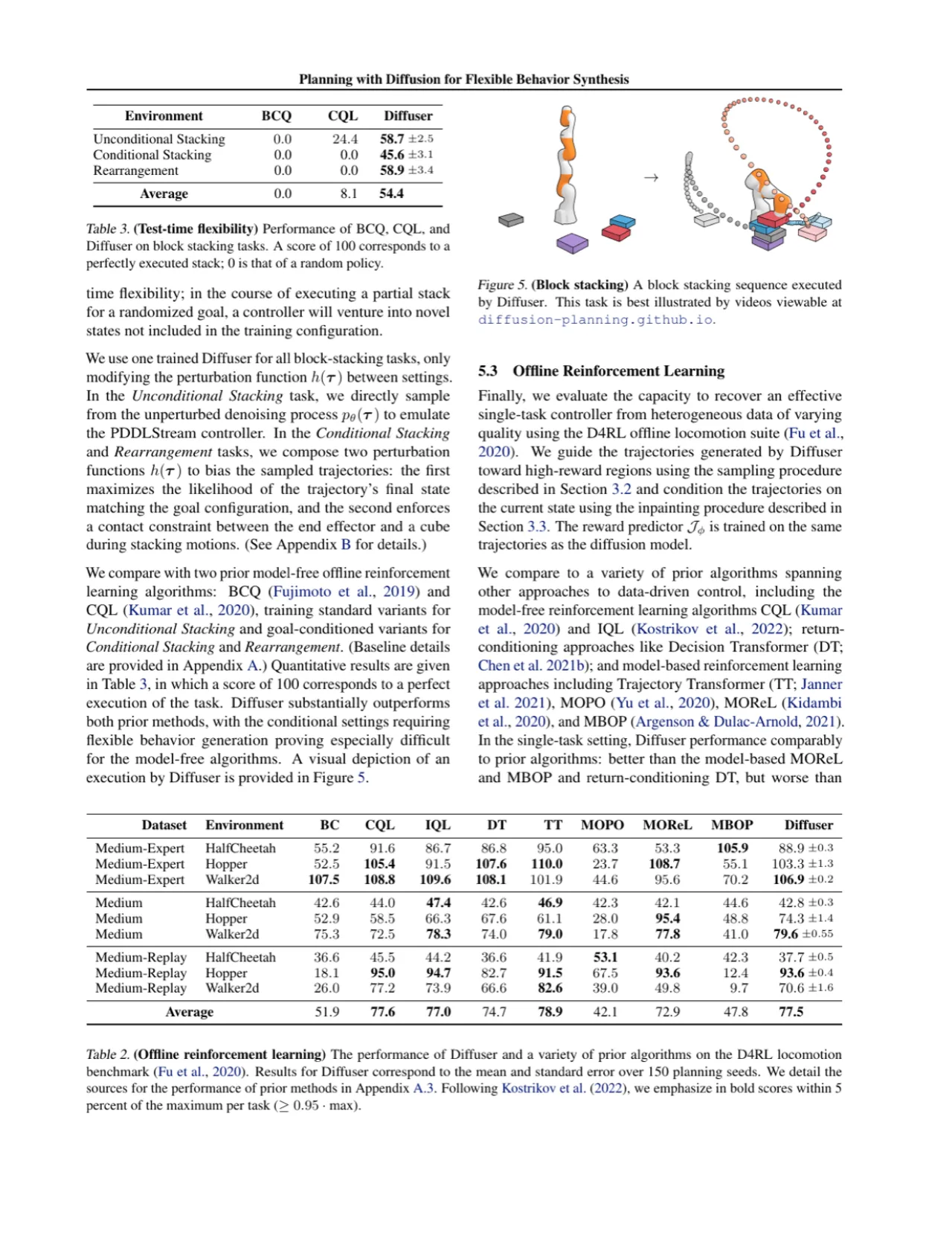
在每步去噪时,用奖励函数 J(τ) 的梯度修正均值:μ̃ = μ + Σ∇_τ J(τ)。奖励函数可以是测试时临时定义的任意可微函数——无需重新训练模型。具体实现中,论文另外训练一个小型奖励回归网络作为 J,其梯度用于引导采样向高奖励轨迹偏移。
规划策略 2:Goal-Conditioned Inpainting(目标约束)
将目标状态视为"已知像素",在每步去噪后强制覆盖目标时步的状态值:δ(τ) = 1 若 s_t 已知(如起点/终点/约束),0 否则。Inpainting 操作为 τi ← δ ⊙ (s_cond + σ_i ε) + (1-δ) ⊙ τi ,将已知约束直接"锚定"在对应位置。论文指出,该方法源自图像修复技术,无需额外训练条件模型即可灵活指定任意时步的约束。
Figure 2(论文). Diffuser 的采样示意:轨迹以二维噪声数组初始化,经 N 步去噪后得到连贯轨迹。整个过程等价于隐式的轨迹优化,不依赖显式的动力学模型展开。
四大关键特性
Long-horizon planning
模型在整条轨迹上去噪,自然支持多步规划,不像单步策略那样在长视野下误差积累。
Variable-length plans
在规划时通过调整噪声初始化张量的时间维度,即可动态改变规划窗口长度,无需重新训练。
Task compositionality
多个奖励函数的梯度可直接求和,实现多目标的即兴组合,例如同时满足 reaching + avoiding。
Effective non-greedy planning
扩散训练过程本身就是对整条轨迹建模,学到的规划器能规避 Markovian 模型固有的短视偏差。