01 动机(Motivation)
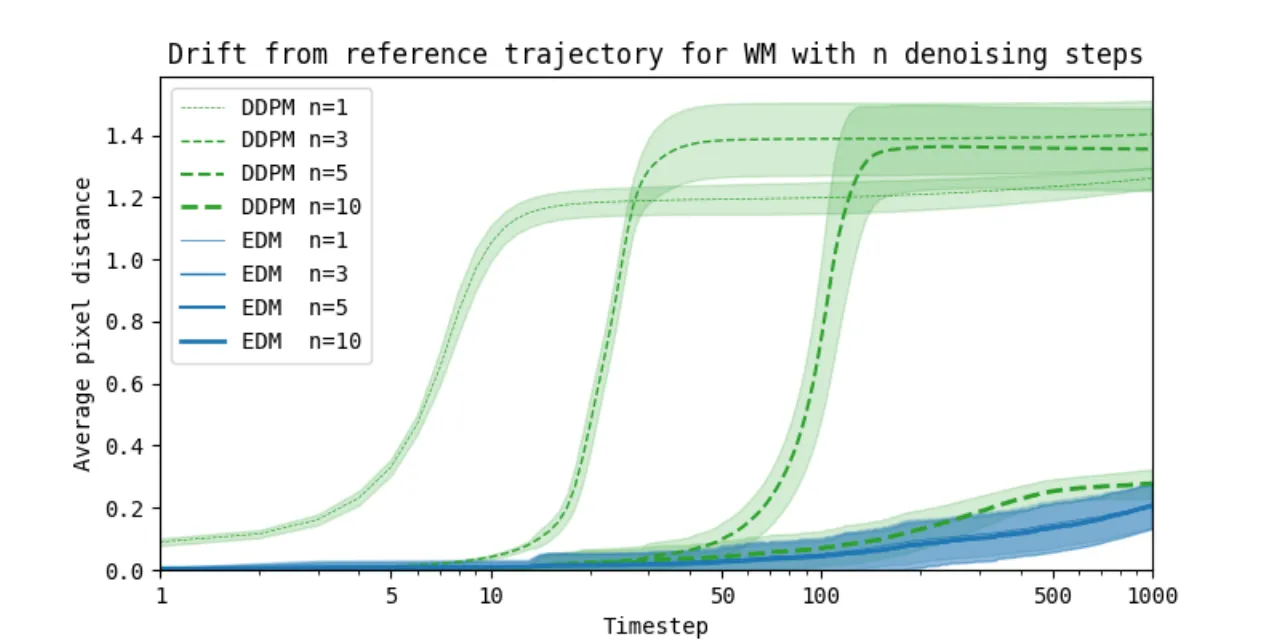
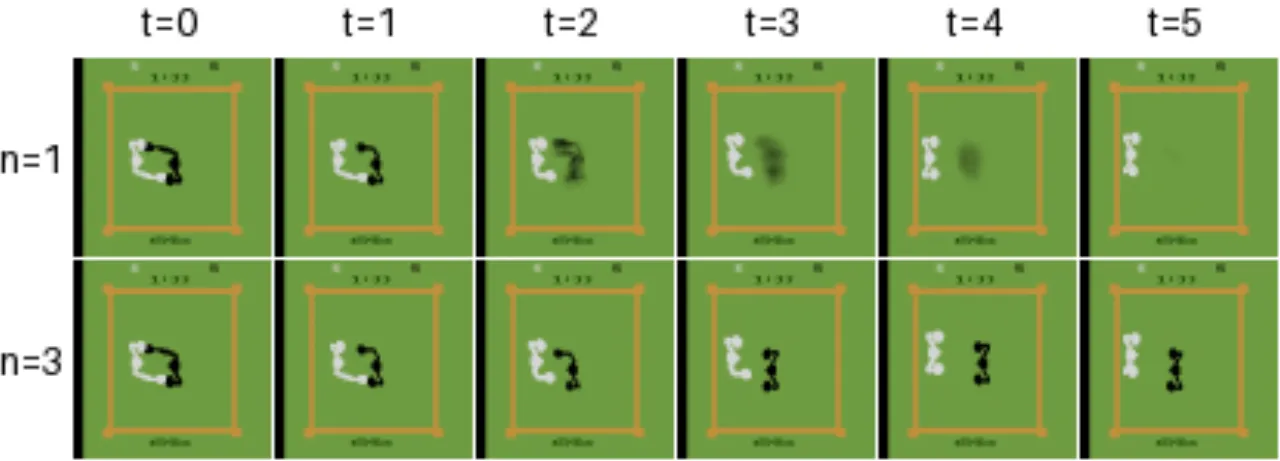
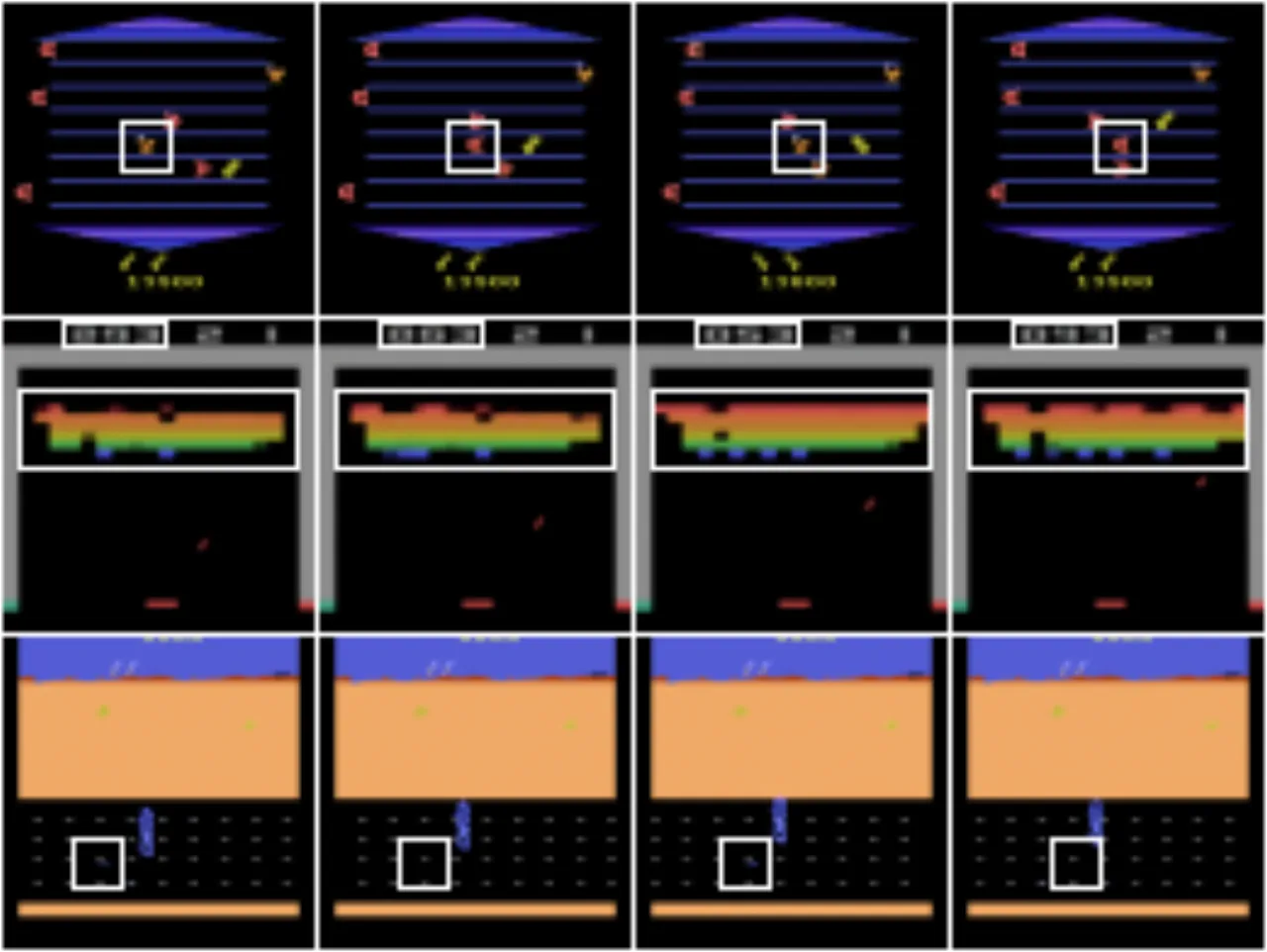
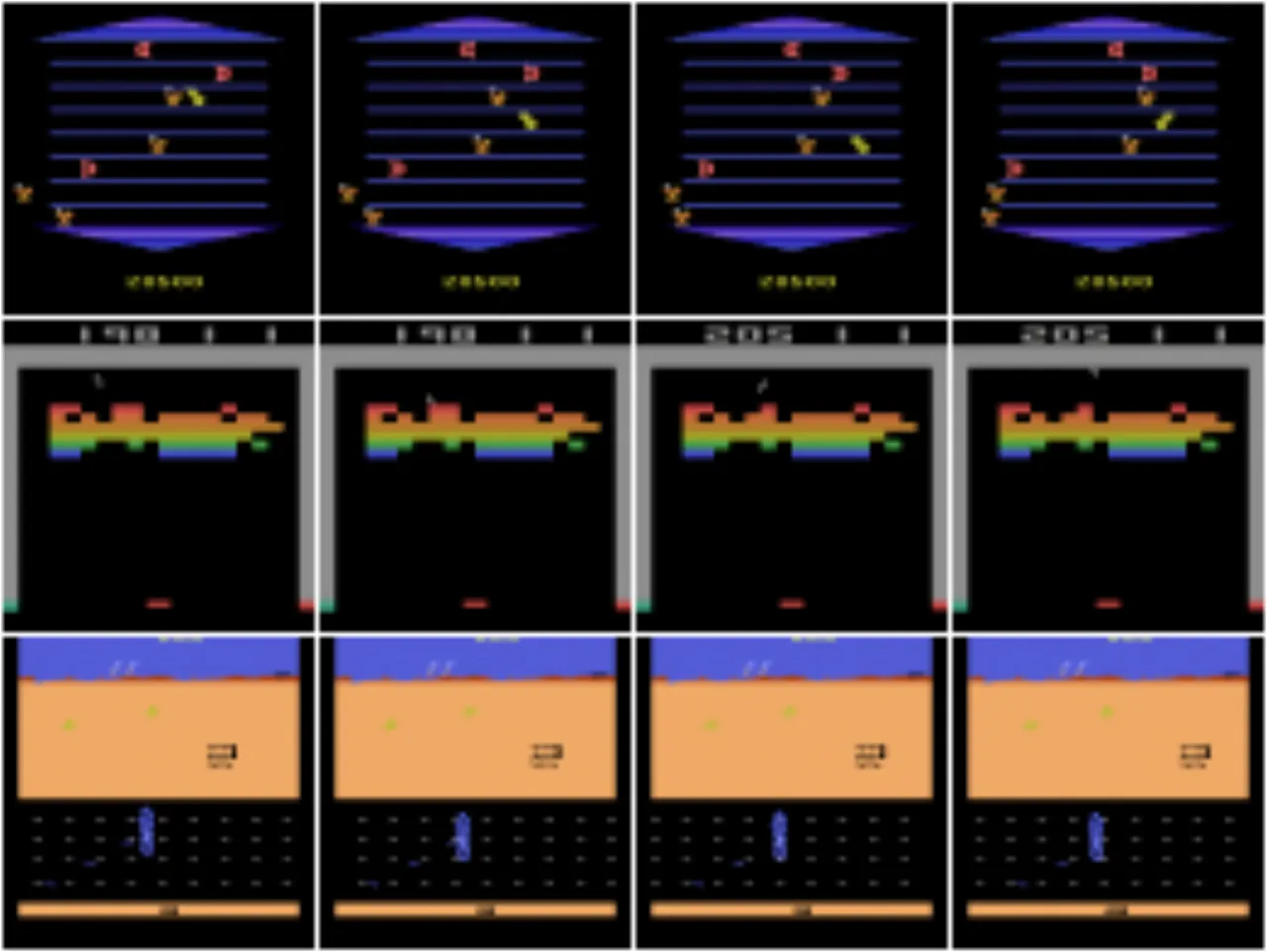
现有世界模型普遍依赖离散隐变量进行压缩,这种有损压缩会丢弃对策略决策至关重要的视觉信息。作者认为,小的视觉细节——例如远处的行人或交通灯——可能直接改变智能体的行为,而离散编码无法忠实还原这些细节。
"Discrete latent representations involve lossy compression that may discard visual information crucial for learning. Small details in the visual input, such as a traffic light or a pedestrian in the distance, may change the policy of an agent."
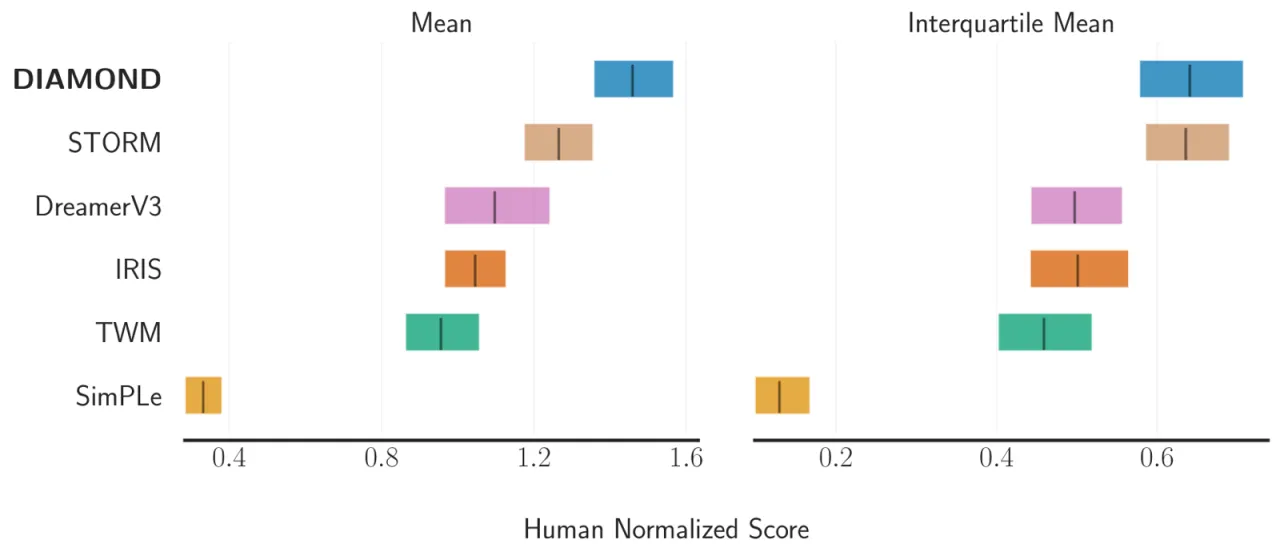
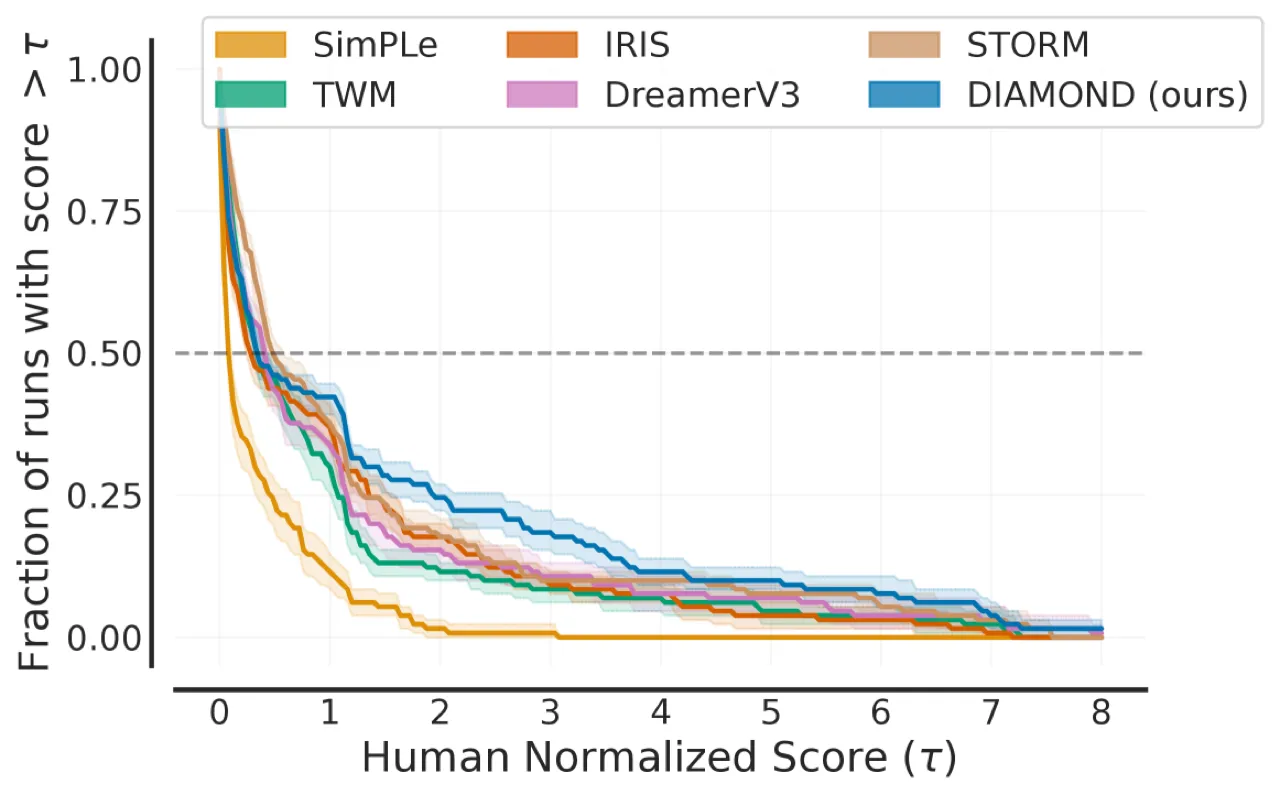
1.46Mean HNS(Atari 100k)
世界模型训练智能体最优
世界模型训练智能体最优
0.64IQM 得分
超越 STORM (0.636)
超越 STORM (0.636)
11/26超越人类水平的游戏数量
3 NFE每帧去噪步数
vs. IRIS 的 16 NFE
vs. IRIS 的 16 NFE
扩散模型天然具备在连续空间建模、灵活捕捉多模态分布、无模式崩塌等优势。核心问题在于:能否将扩散模型高效、稳定地用于在线强化学习的世界模型,从而让智能体在高质量的想象轨迹中学习?