01 动机(Motivation)
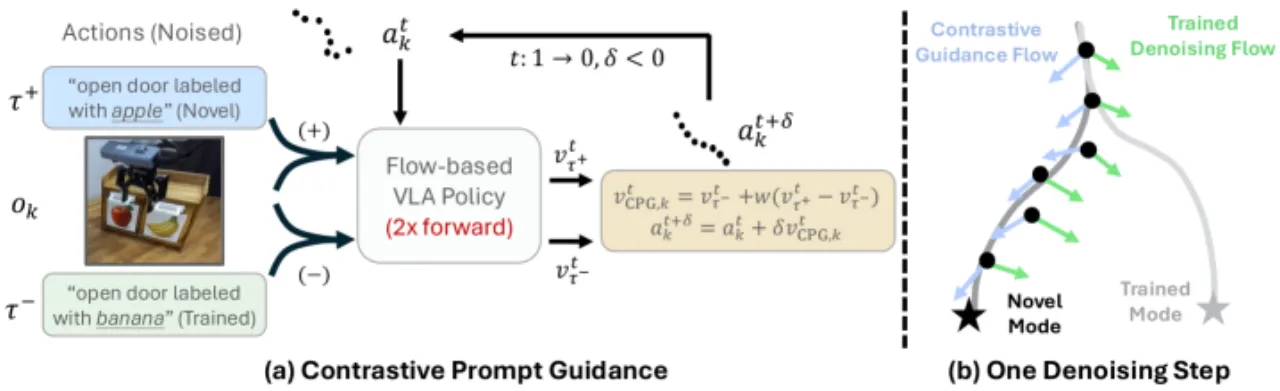
将一个预训练的通用 VLA 策略在少量演示上做 supervised fine-tuning(SFT),往往会使它 "过拟合" 到训练数据的行为分布,无法正确响应在 post-training 阶段未出现过的新指令。
"Have you ever post-trained a generalist vision-language-action (VLA) policy on a small demonstration dataset, only to find that it stops responding to new instructions and is limited to behaviors observed during post-training?"
作者把这一失效模式命名为 lock-in(锁死),并区分出两种表现形式:
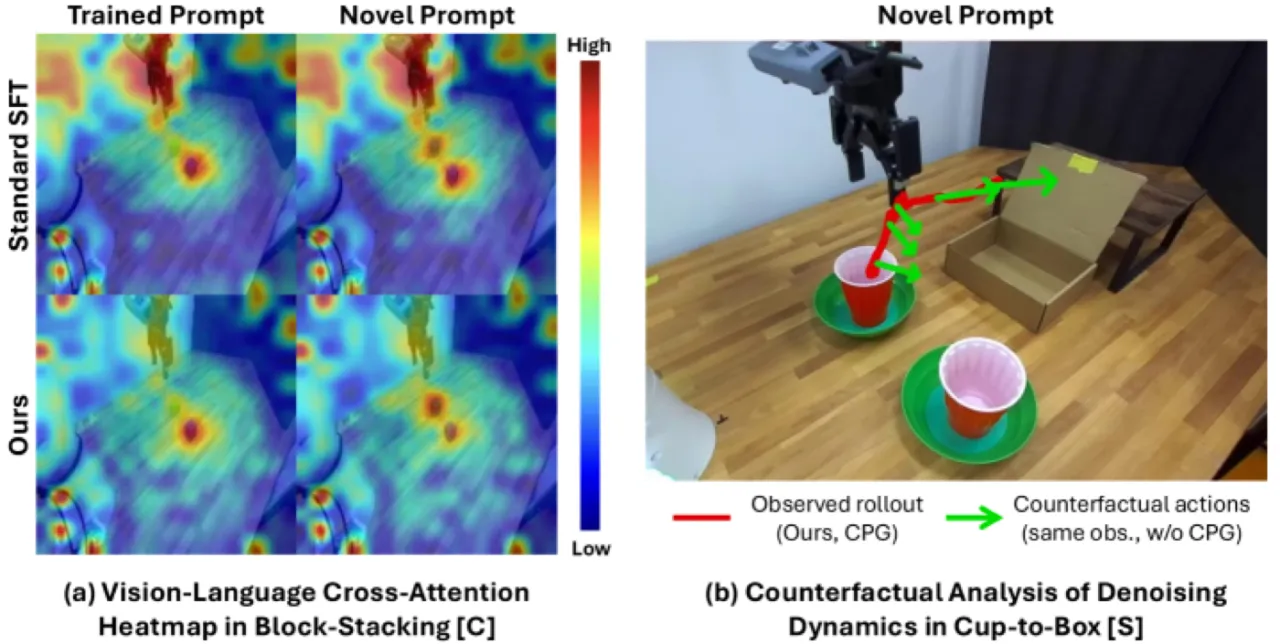
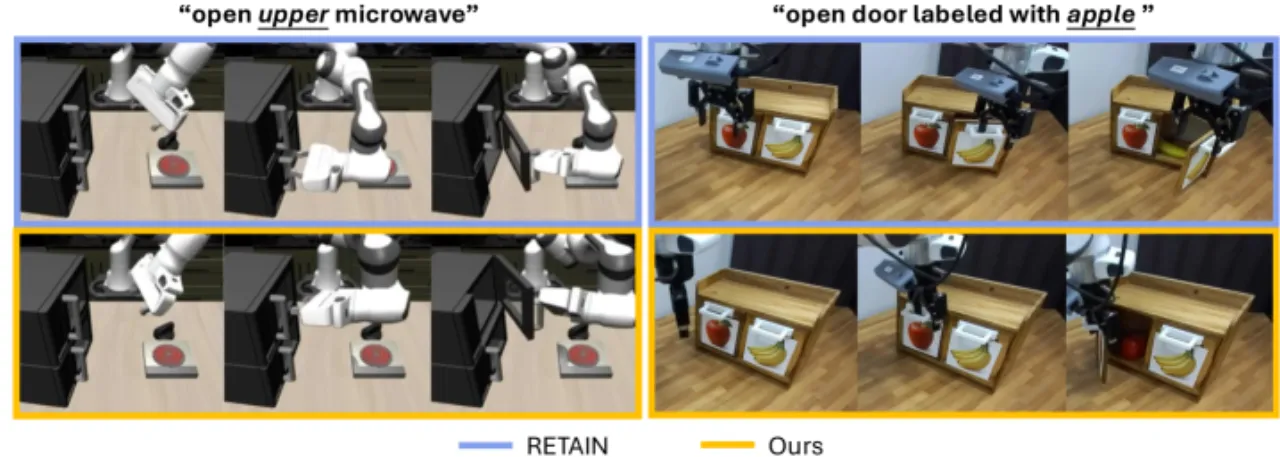
- Concept lock-in:策略执行时只关注 post-training 中出现过的特定物体或属性,忽视指令中描述的新目标(如颜色、类别替换)。
- Spatial lock-in:策略固执于 post-training 中见过的空间位置,无法被引导到指令所指向的新位置。
现有的补救手段通常需要额外的监督信号(如来自大型基础模型的奖励、辅助目标),或依赖扩增数据集。但作者指出,预训练 VLA 本身已具备足够的内部知识,无需额外数据即可克服 lock-in。

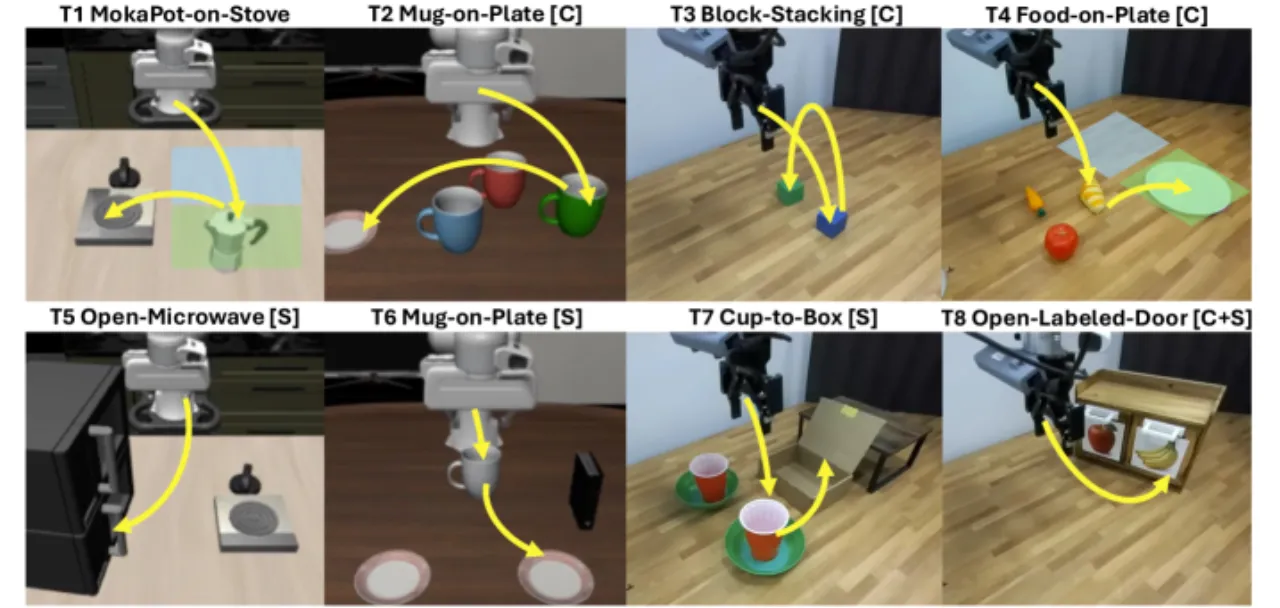
8仿真 + 真实世界评测任务数
80–100每任务演示条数(低数据 regime)
2lock-in 类型:concept + spatial
0额外监督信号需求(仅用预训练知识)