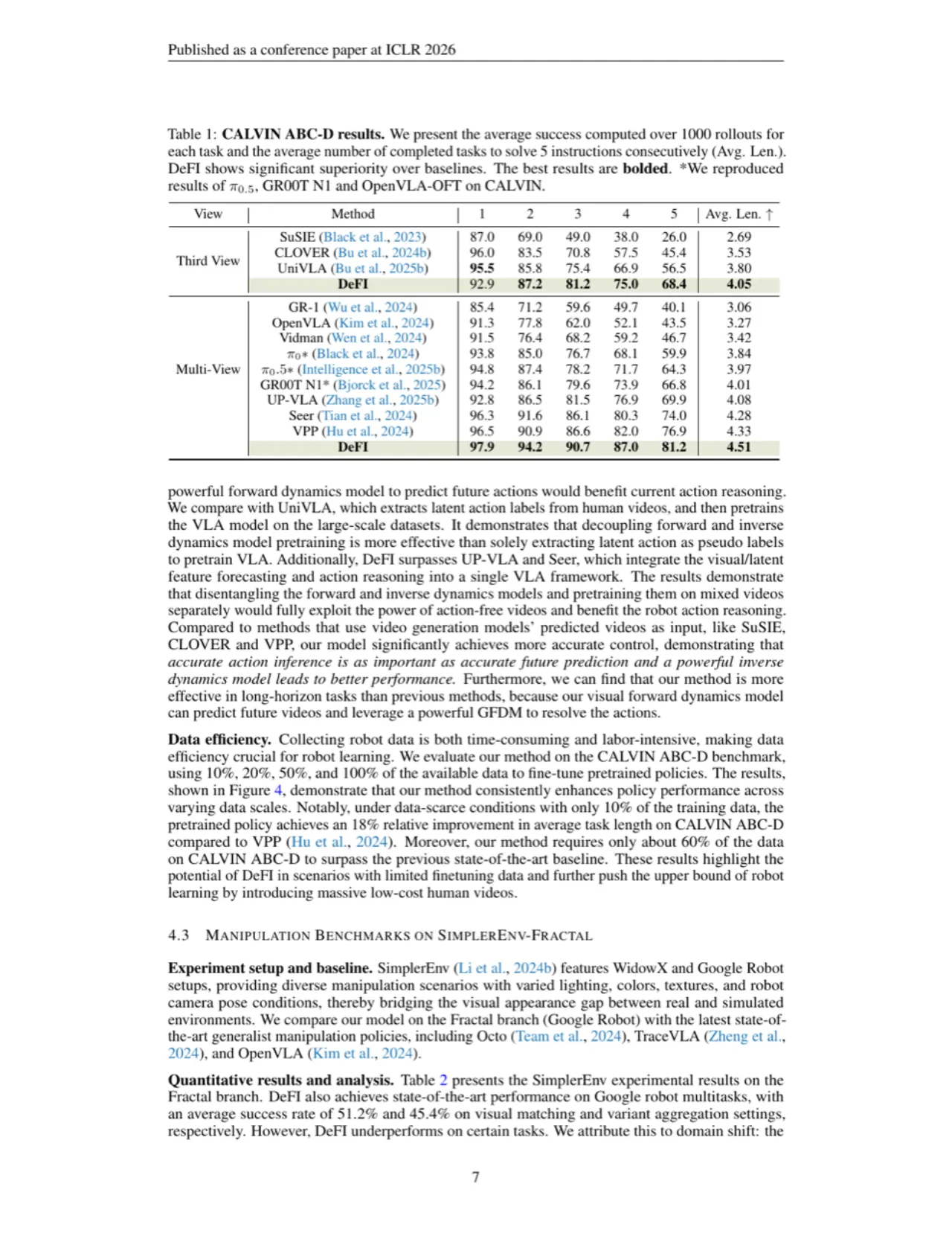
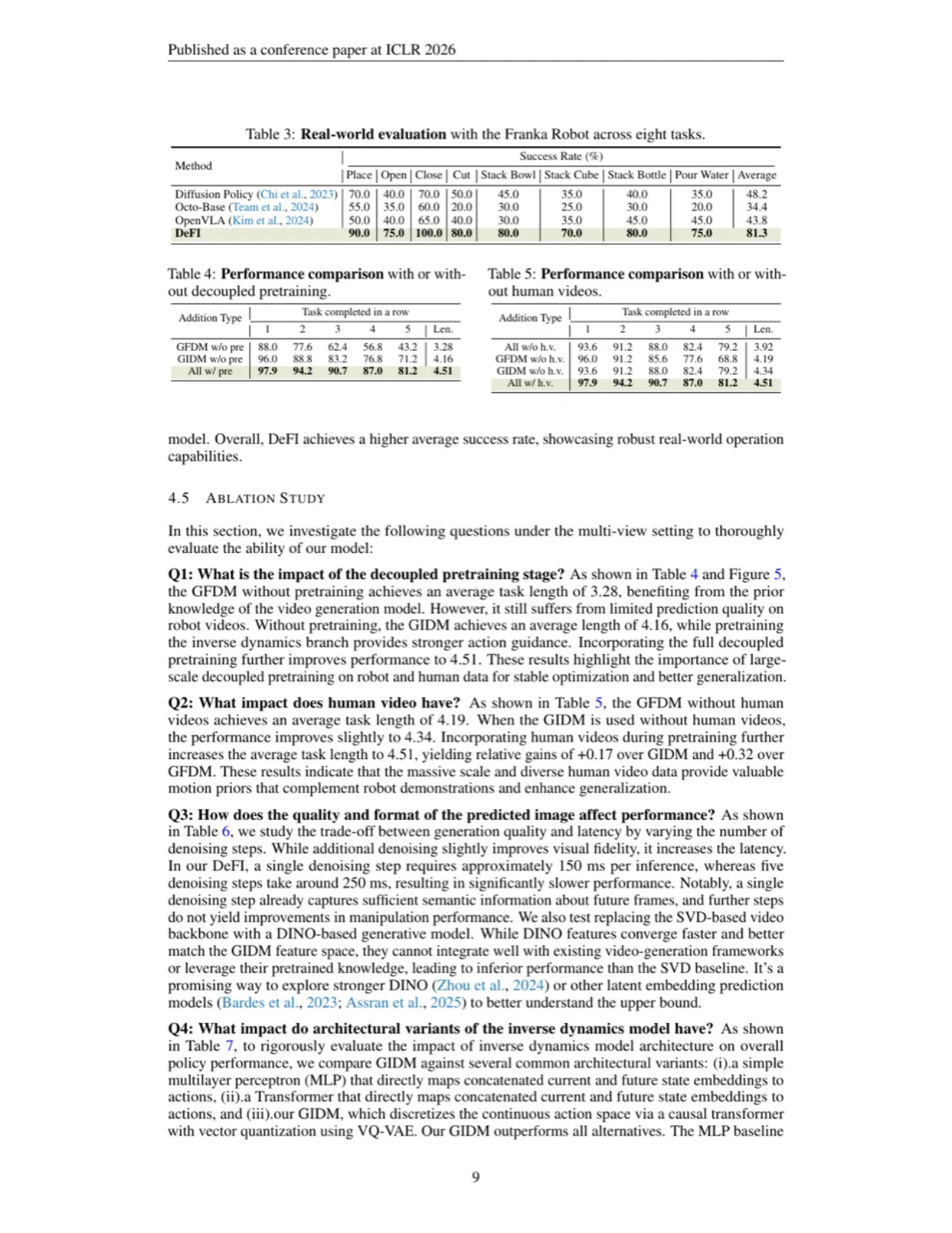
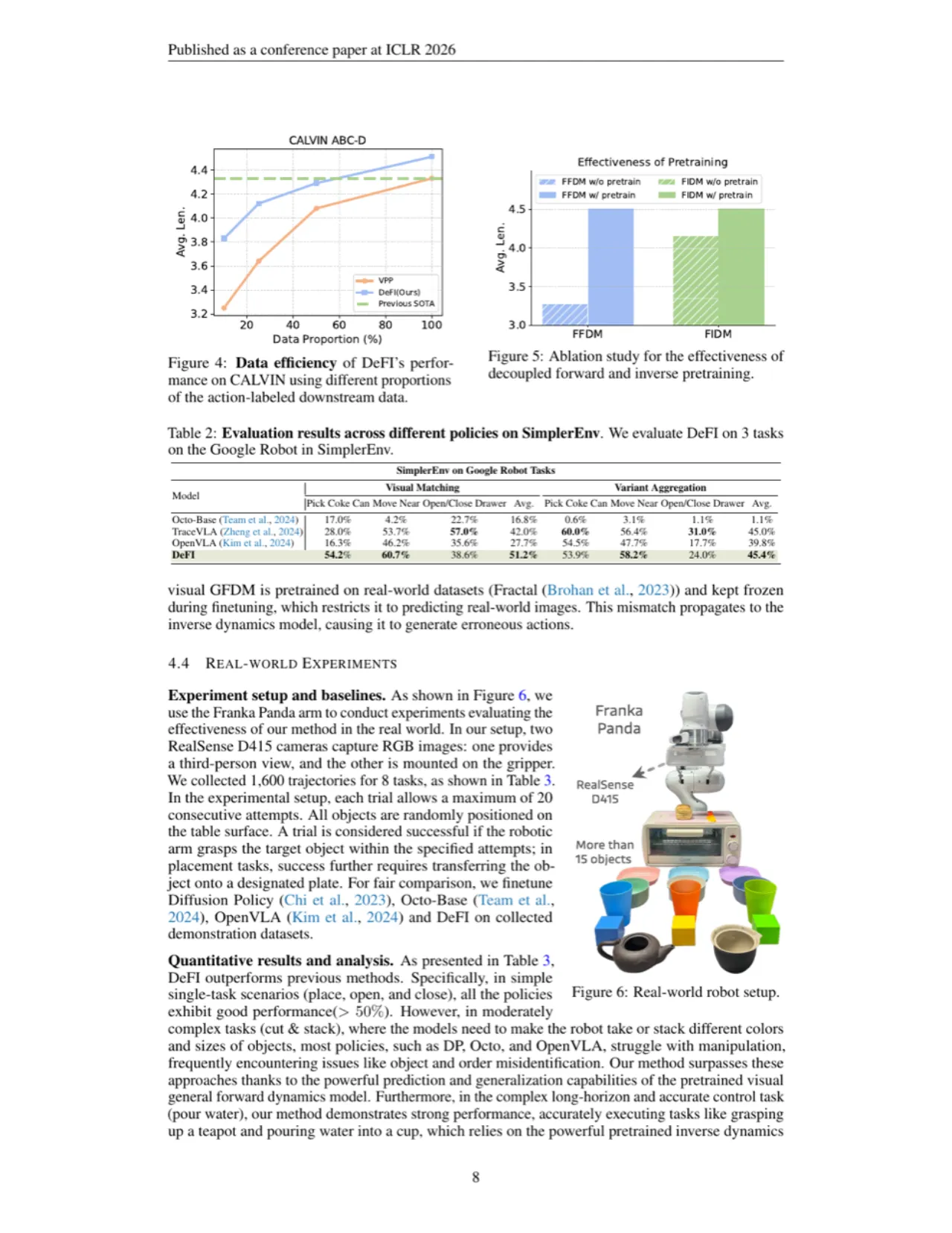
现有 VLA 模型将视觉生成与动作预测捆绑训练,存在两大根本矛盾:其一,2D 图像空间的未来帧预测目标与 3D 空间的精细动作预测目标本质不对齐;其二,这种耦合训练方式使模型无法充分利用互联网上海量的、仅有视觉内容的无动作标注视频数据。
"VLA models have shown great potential in building generalist robots, but still face a dilemma — misalignment of 2D image forecasting and 3D action prediction. Besides, such a vision-action entangled training manner limits model learning from large-scale, action-free web video data."