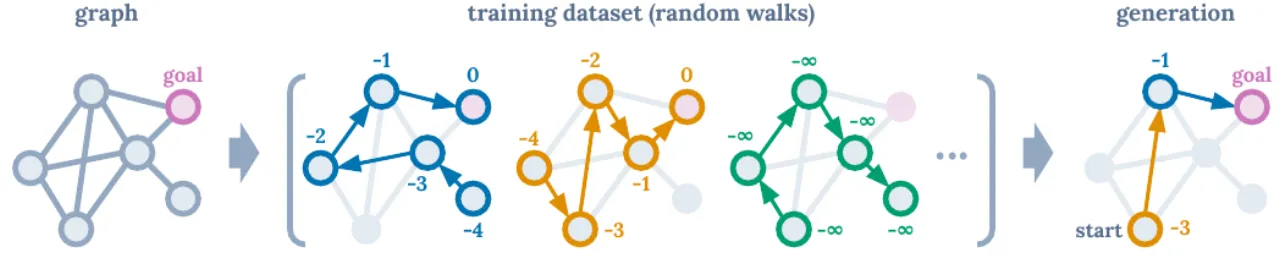
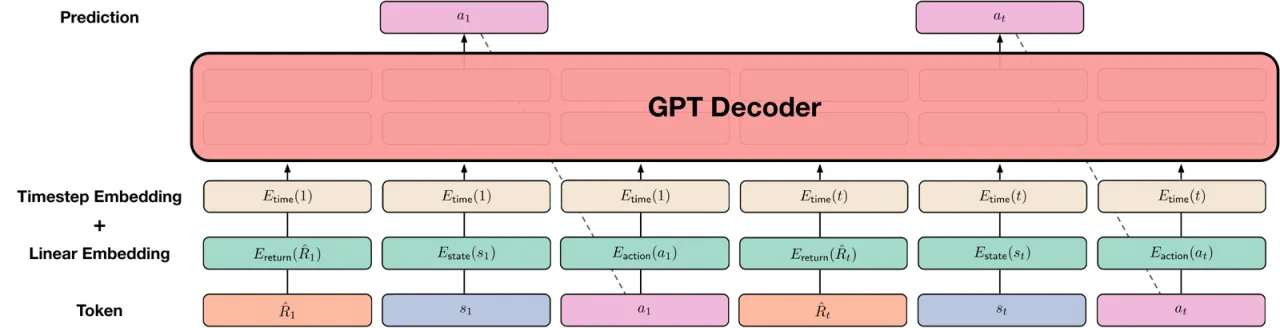
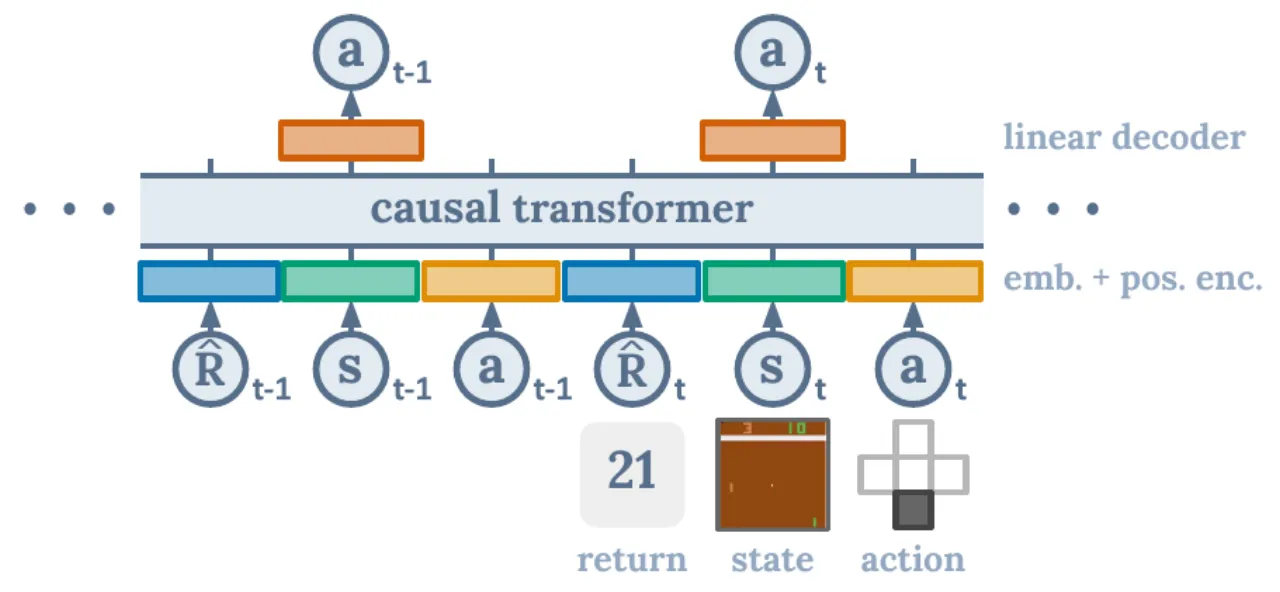
"Instead of training a policy through conventional RL algorithms like temporal difference (TD) learning, we will train transformer models on collected experience using a sequence modeling objective. This will allow us to bypass the need for bootstrapping for long term credit assignment — thereby avoiding one of the 'deadly triad' known to destabilize RL."
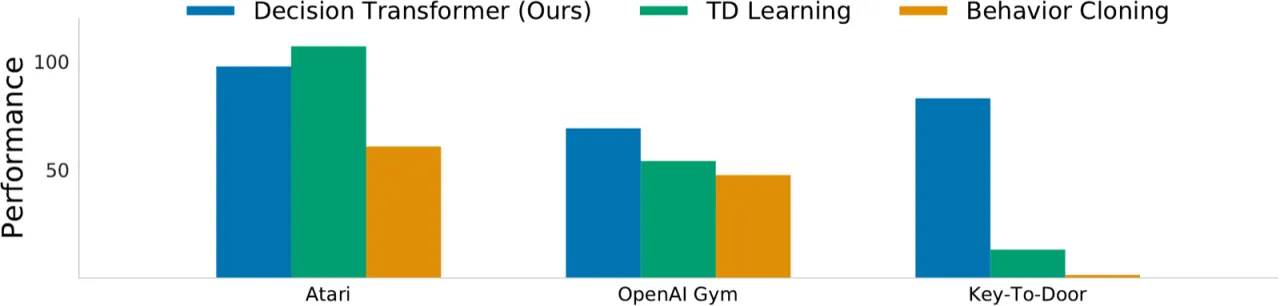
Figure 3(归一化得分汇总):跨 Atari、OpenAI Gym 和 Minigrid 的平均归一化 episode return。
"On a diverse set of tasks, Decision Transformer performs comparably or better than traditional approaches."
"Methods using hindsight (Decision Transformer, %BC) can learn successful policies, while TD learning struggles to perform credit assignment."(Table 4)
Ablation — 上下文长度(Context Length K)的重要性
对比 K=1(无历史)与标准 K(K=30 或 K=50)。实验表明长上下文对性能至关重要,尤其在 Breakout(267.5 vs 73.9)和 Pong(106.1 vs 2.5)上差异显著。
论文假设:在建模策略分布时,上下文帮助 Transformer 识别轨迹来自哪类策略,从而实现更好的学习与生成。
测试时需要指定合理的目标 return-to-go 初始值。若目标设置过高(超出数据分布)或不合理,
模型可能生成低质量动作。论文提到"conditioning on return distributions to model stochastic settings
instead of deterministic returns"是未来值得研究的方向。
局限于离线 RL,在线探索未研究(stated)
本文仅研究了离线 RL 场景,未扩展至在线 RL。论文指出"Decision Transformer can meaningfully improve
online RL methods by serving as a strong model for behavior generation",但这仅为展望而非实验验证。
无法显式进行策略改进(inferred)
Decision Transformer 本质是监督学习:它能复现数据集中高回报轨迹对应的行为,但无法通过优化学到的价值函数
来发现超出数据集的更优策略(Qbert 上明显落后于 CQL,104.2 vs 15.4,印证了这一点)。
TD 方法在数据质量高、状态覆盖好的任务上仍有优势。
论文明确提出:"reward design by nefarious actors can potentially generate unintended behaviors as our model
generates behaviors by conditioning on desired returns."
训练数据的来源与质量直接决定生成行为的安全性,存在被恶意设计的数据或奖励函数所利用的风险。