在 TAPVid-3D(「三个真实世界、富有挑战的子集」)上评测。对局部坐标系 3D 跟踪,报告 APD₃D、遮挡精度 OA 与 3D Average Jaccard(AJ),「D4RT 达到 SOTA……无论是否给定真值内参」。对世界坐标系 3D 跟踪——它「也衡量模型隐式切换参考系的能力」——「我们的模型在这项任务上同样出色,各项指标都有强力提升」。在效率上,「我们的模型比前作快 18–300×」。
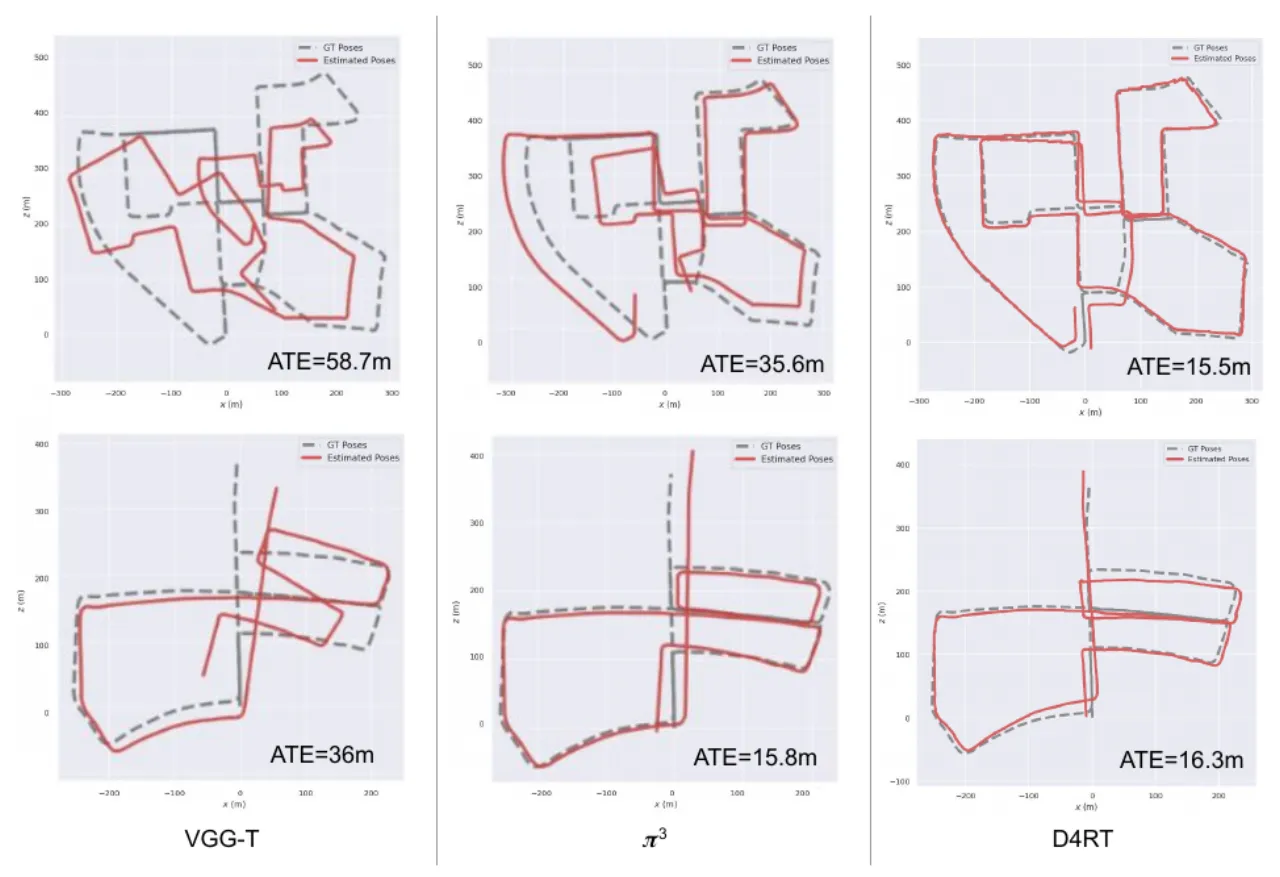
效率 vs 精度(相机位姿)。「为公平起见,我们去掉了基线中与相机估计无关的解码头,使它们更快。即便如此,我们发现 D4RT 在精度与效率上都超越所有现有方法,吞吐量比 MegaSaM 高出两个数量级。」
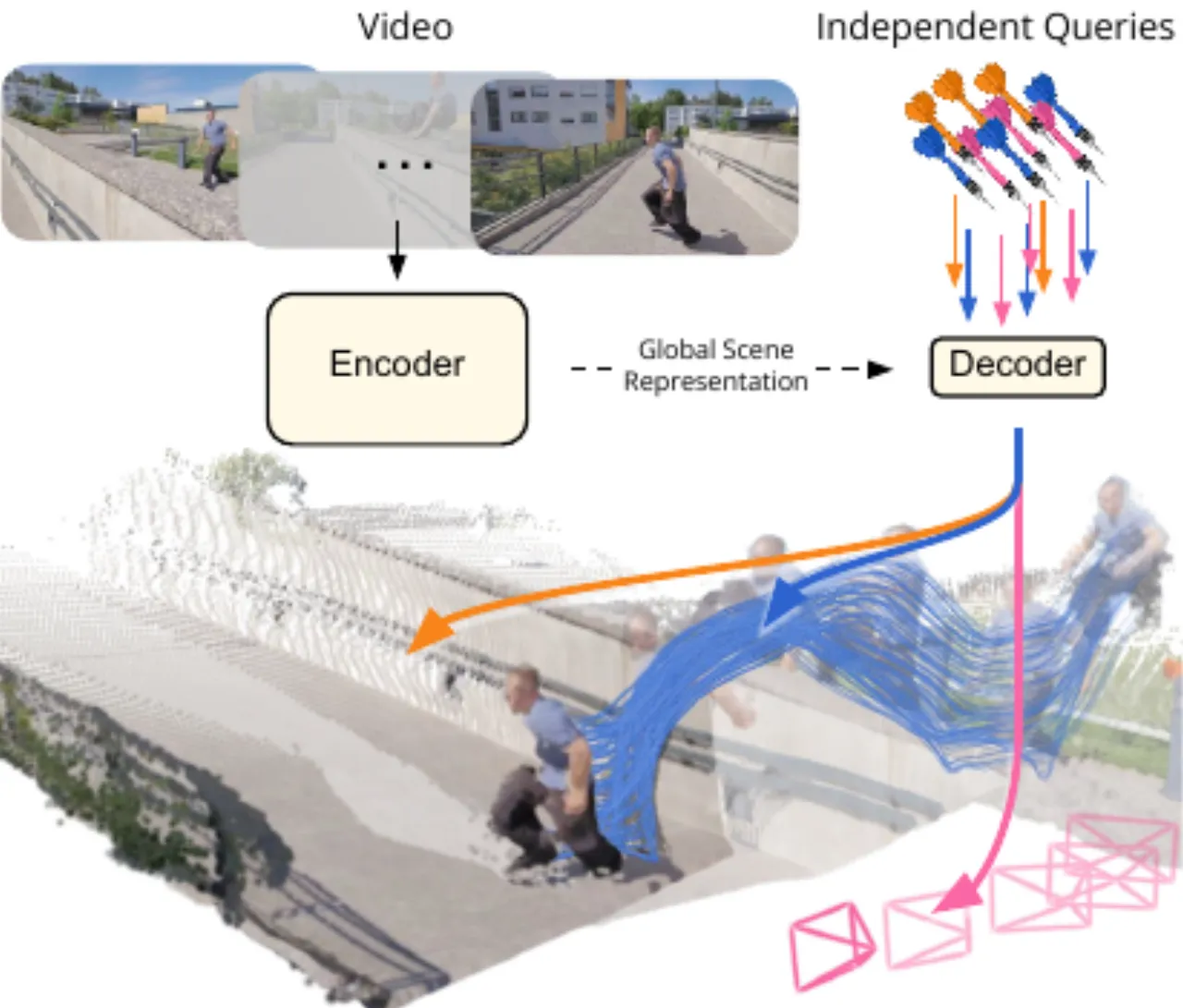
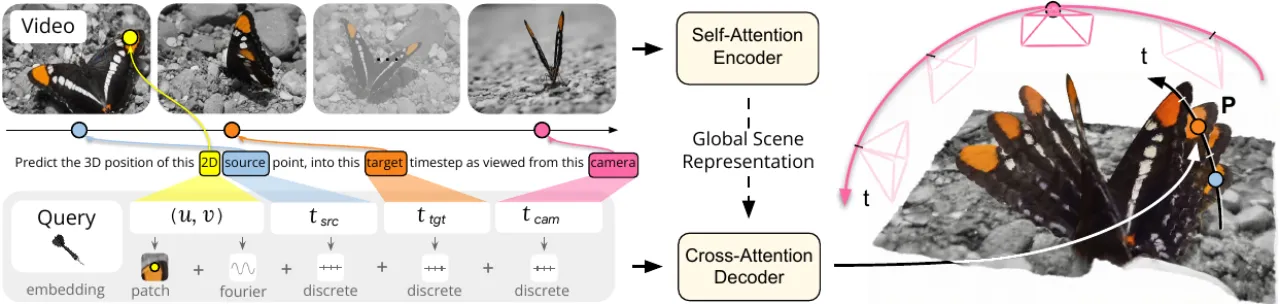
3D 重建:点云 / 深度 / 相机位姿
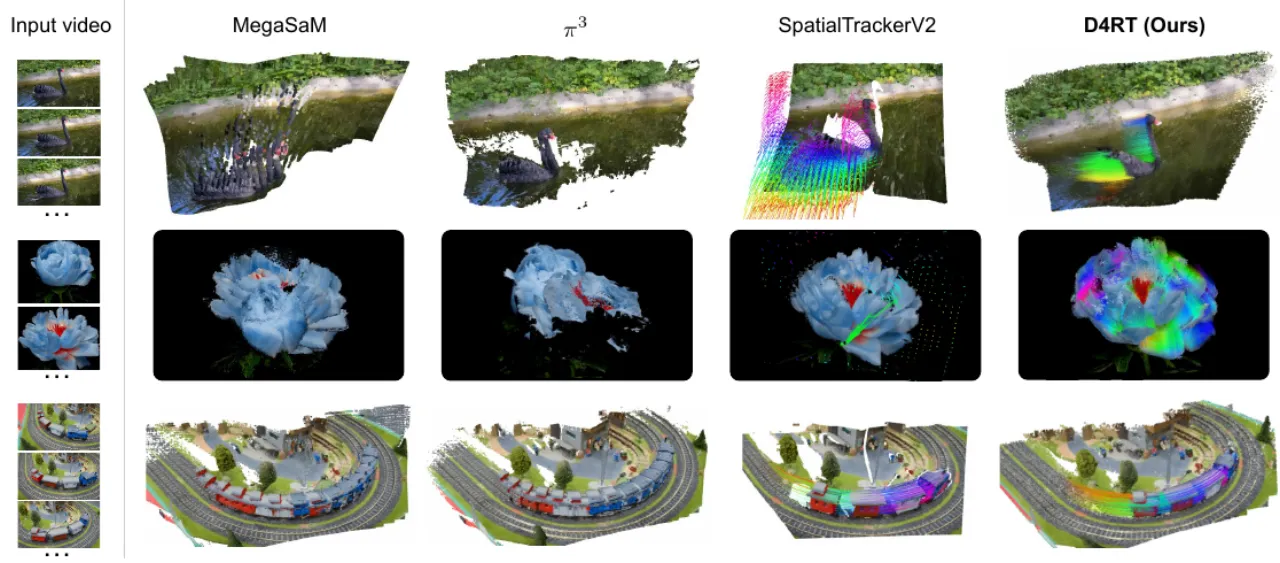
点云(Sintel 动态 + ScanNet 静态):mean-shift 对齐后取 mean L1,「我们的模型在各数据集上都优于近期的 SOTA 模型」。