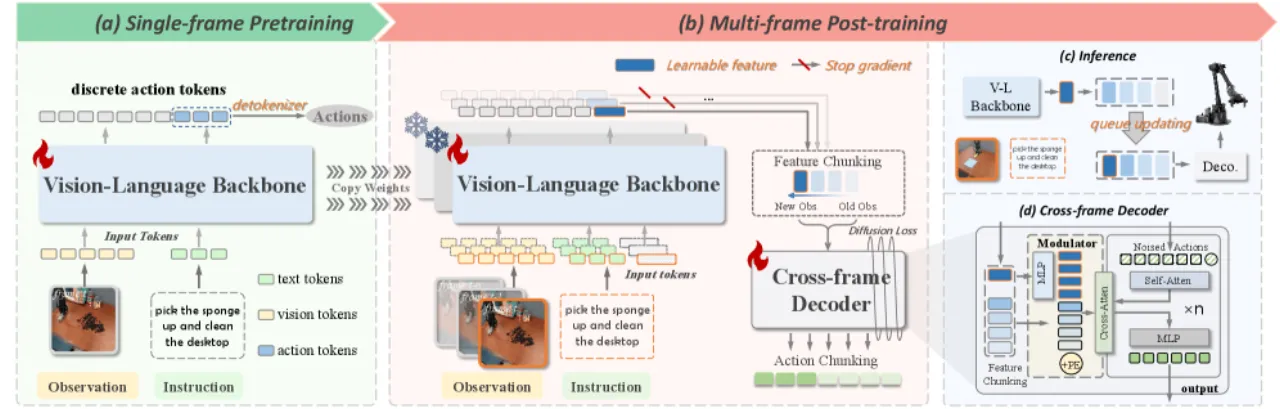
01 动机
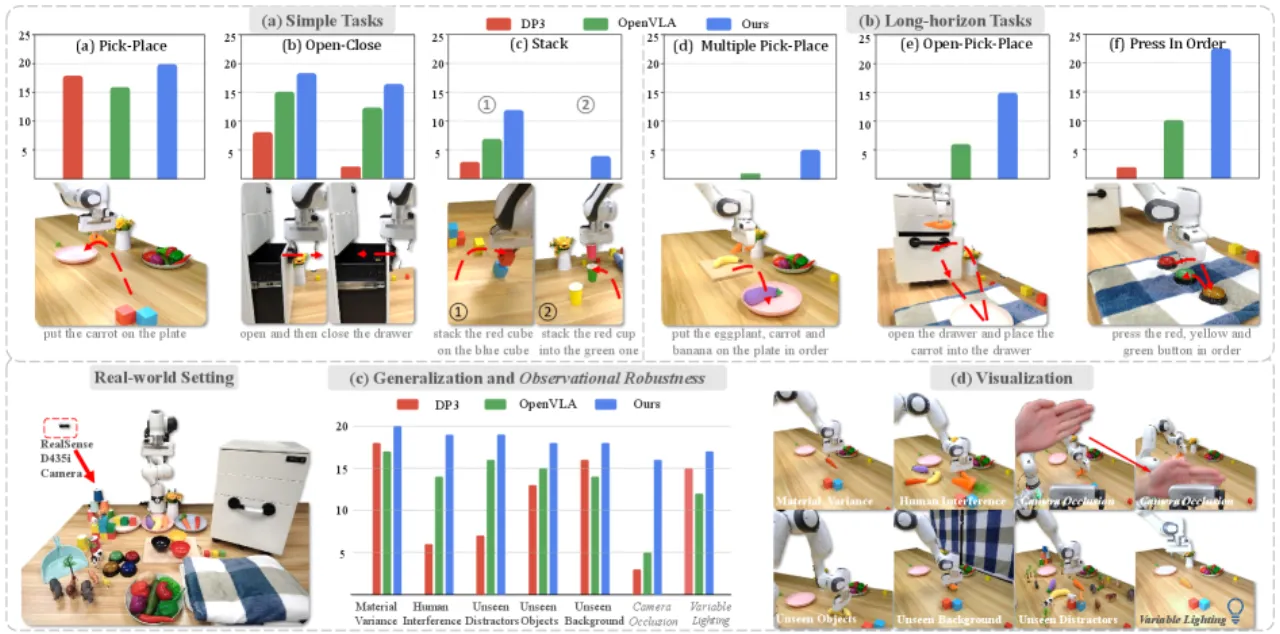
现有基于预训练视觉-语言模型(VLM)的 VLA 模型仍受限于单帧图像范式,无法充分利用多帧历史提供的时序信息。 直接将多帧图像输入 VLM backbone 会因 self-attention 的二次方计算复杂度带来巨大的计算开销和推理延迟。 低级策略(low-level policies)的研究已表明多帧历史观测可提升性能与鲁棒性,但如何将其高效地引入大型 VLA 模型仍是未解难题。
"these models remain constrained by the single-frame image paradigm and fail to fully leverage the temporal information offered by multi-frame histories, as directly feeding multiple frames into VLM backbones incurs substantial computational overhead and inference latency."
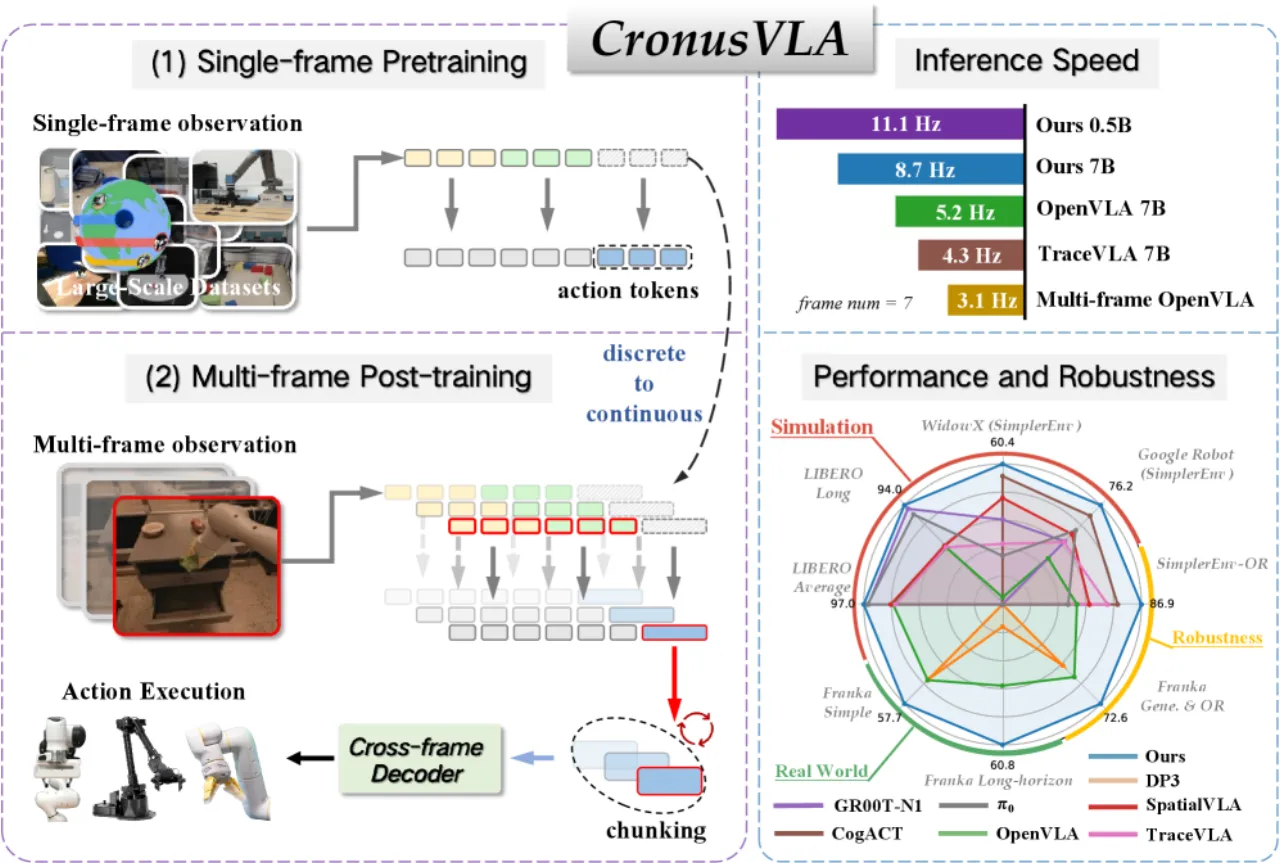
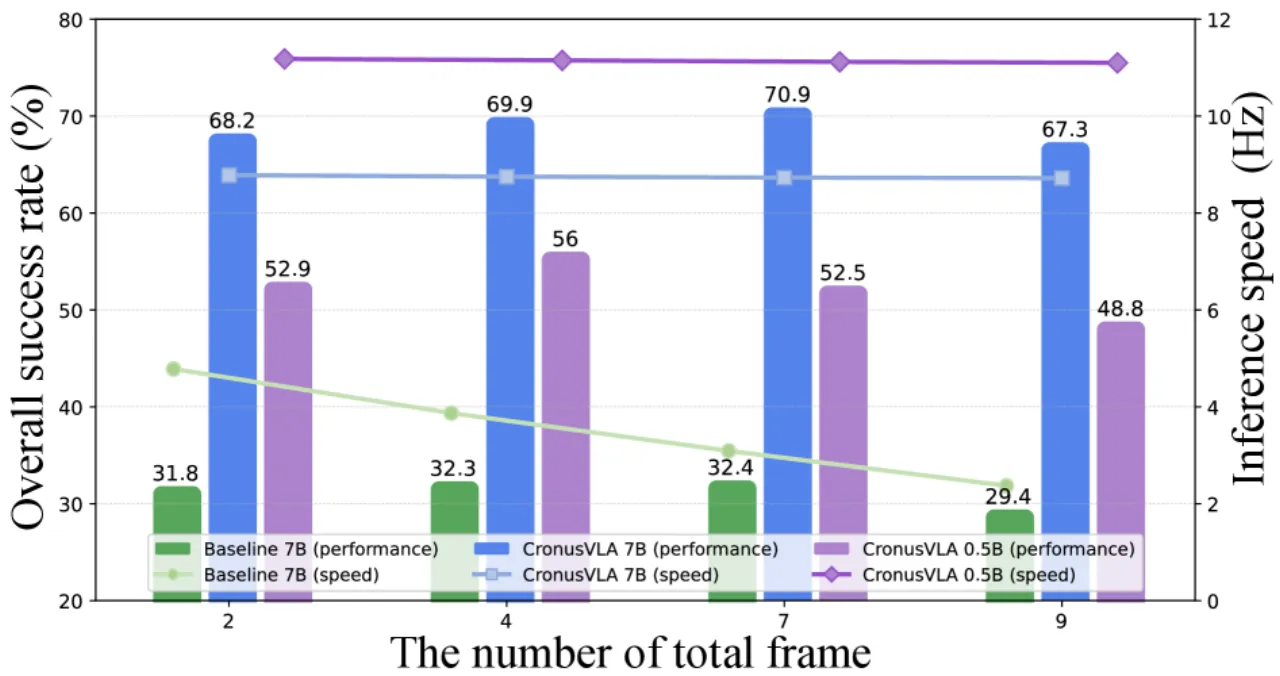
70.9%SimplerEnv 平均成功率
+26.8%LIBERO 较 OpenVLA 的提升
8.73 Hz推理速度(基线 3.09 Hz)
24 类SimplerEnv-OR 干扰类型