01 动机
大规模预训练的 VLA(如 π0、π0.5)具备强大的操作能力,但在将自然语言指令转化为精确动作时仍频繁出现"intention-action gap"。 扩大策略预训练规模(更多数据、更大模型)虽然有效,但代价极高。 那么,能否在推理时利用额外算力来弥合这一鸿沟?
"Can we enable VLAs to leverage additional computation at test time to improve alignment between generated actions and provided language instructions?"
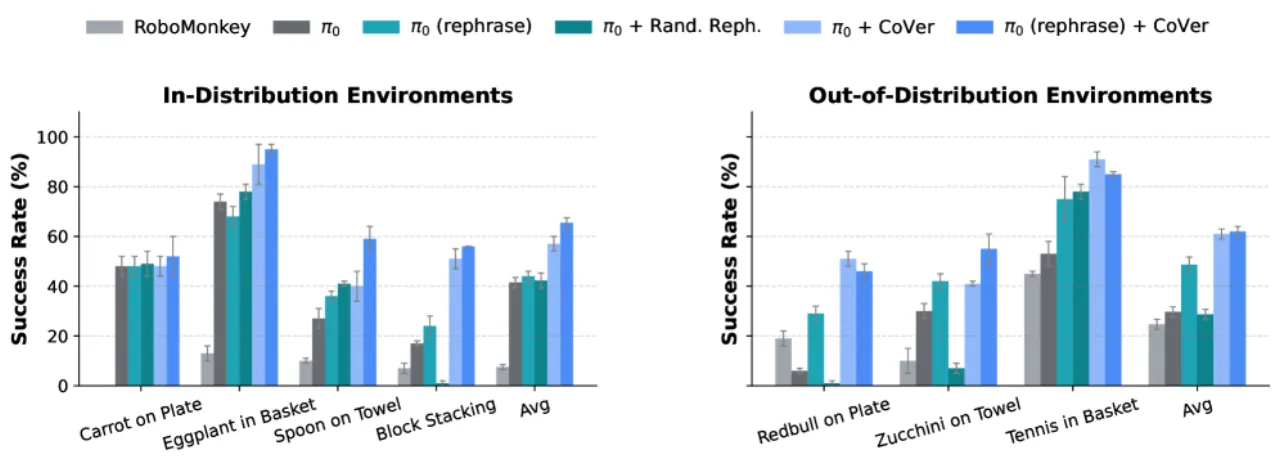
+22%SIMPLER 域内成功率(vs. 扩大策略训练)
+13%SIMPLER 域外成功率(OOD)
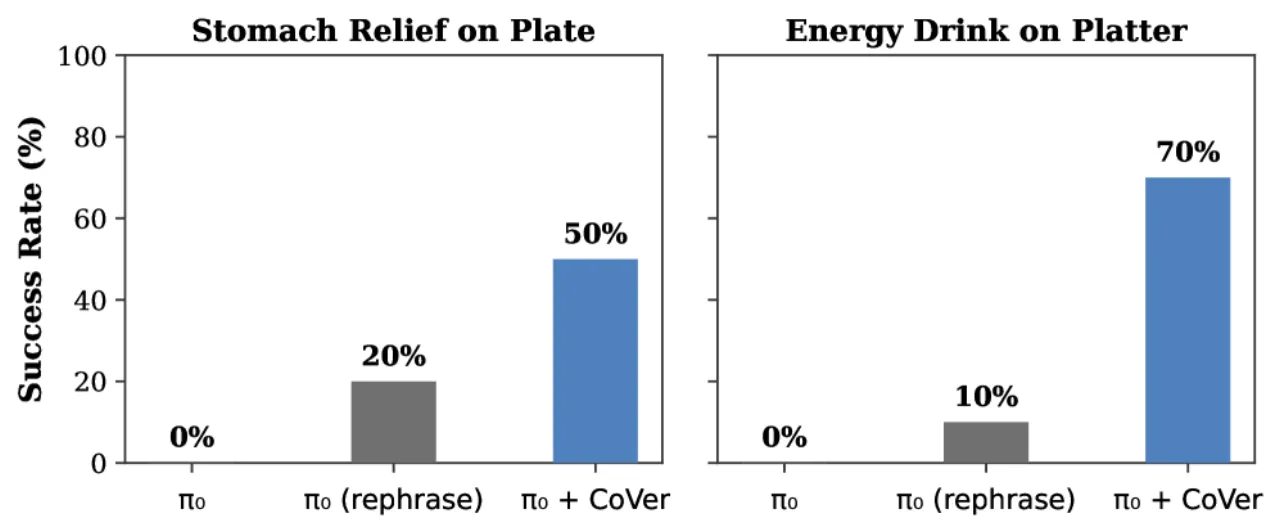
+45%真实机器人实验成功率提升
+13.9%PolaRiS 基准任务进度提升