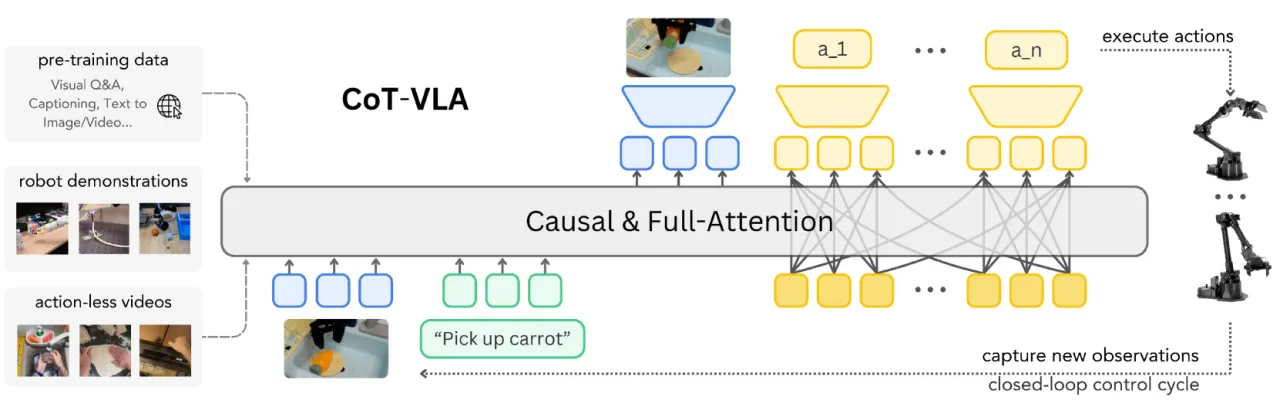
01 动机
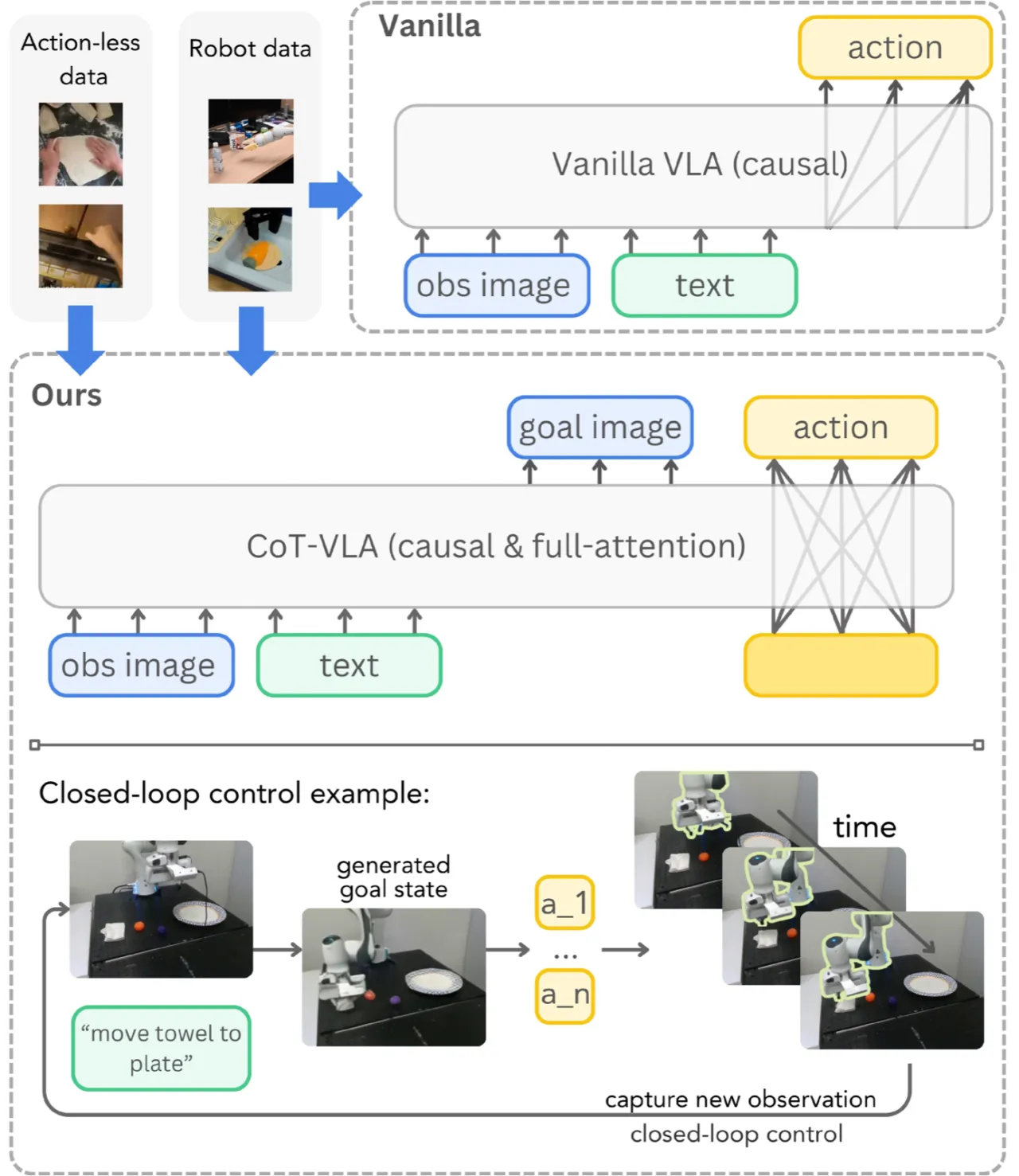
当前主流 VLA 模型直接将语言指令与视觉观测映射到机器人动作,缺乏中间推理过程。这与人类"先在脑海中规划目标状态,再执行"的认知方式相悖,也限制了模型在复杂长视野任务中的泛化能力。
"We propose to incorporate explicit visual chain-of-thought (CoT) reasoning into VLAs by predicting future image frames autoregressively as visual goals before generating a short action sequence to achieve these goals."
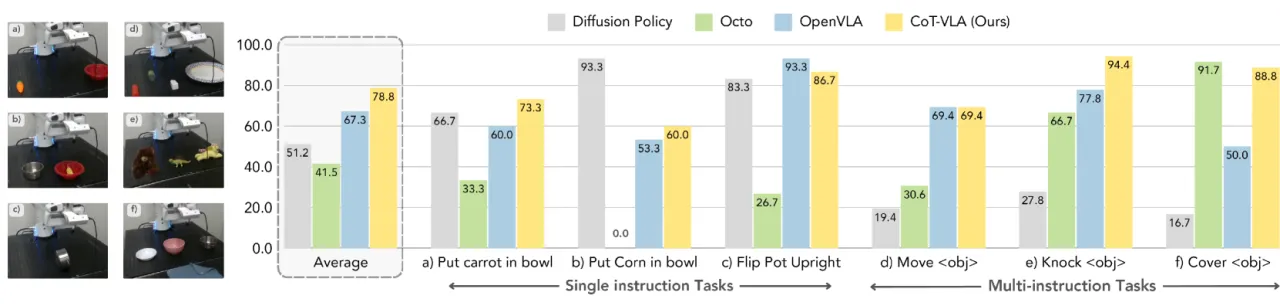
+17%真实机器人操作任务 vs SOTA
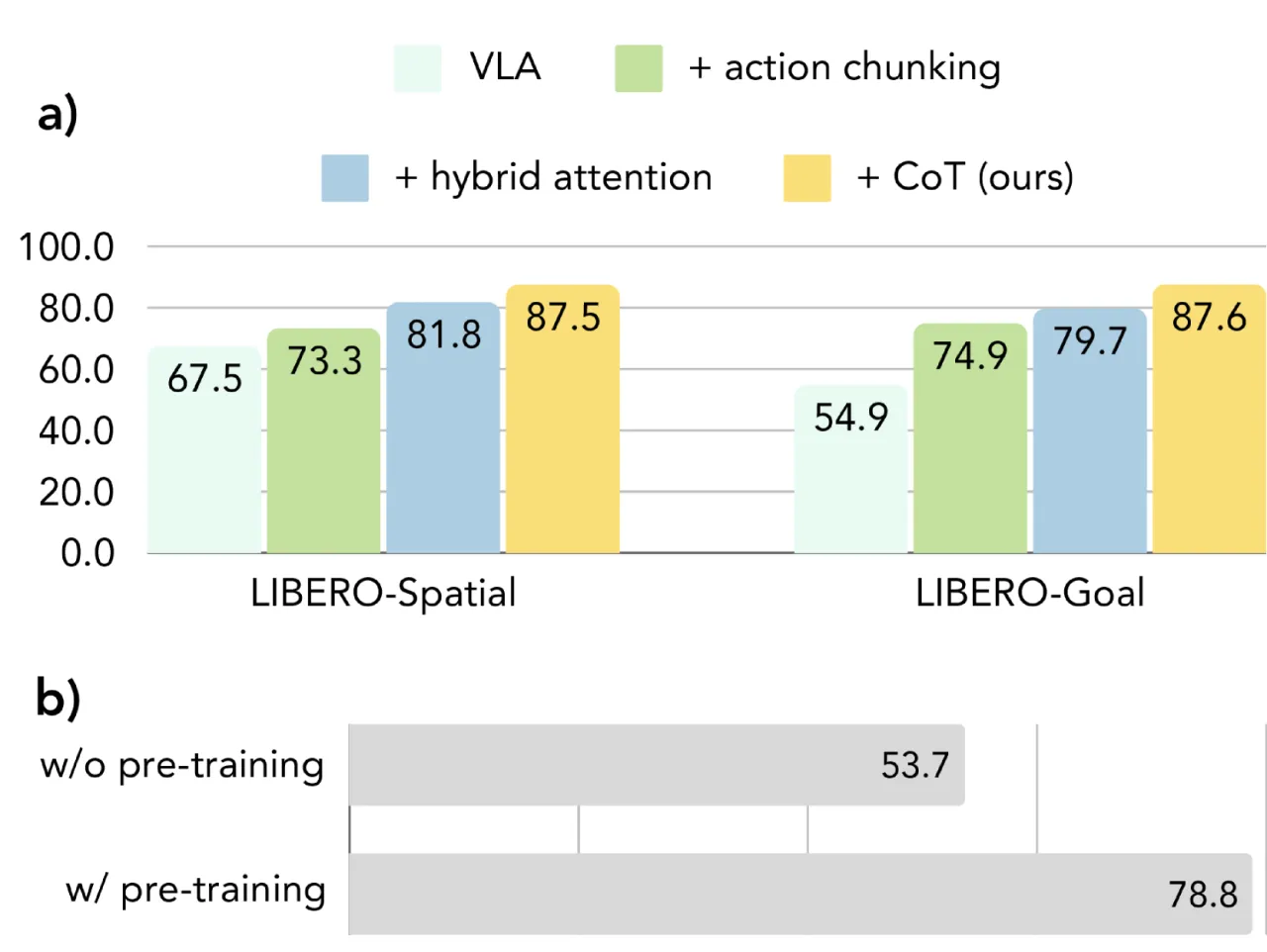
+6%LIBERO 仿真 benchmark
7BVILA-U 骨干参数量
46.7%预训练阶段带来的相对提升(Franka-Tabletop)
核心洞察在于:若模型能生成"接下来 n 步后的场景应该是什么样"的图像,则这一预测本身就构成了对任务进度的显式规划。无动作标注的视频数据(如 EPIC-KITCHEN、Something-Something V2)同样包含丰富的视觉动态先验,可用于训练子目标图像生成能力,从而扩大有效训练数据规模。