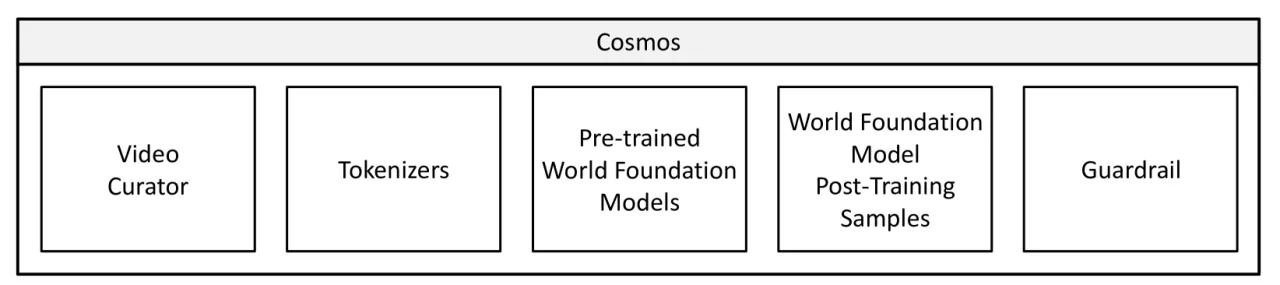
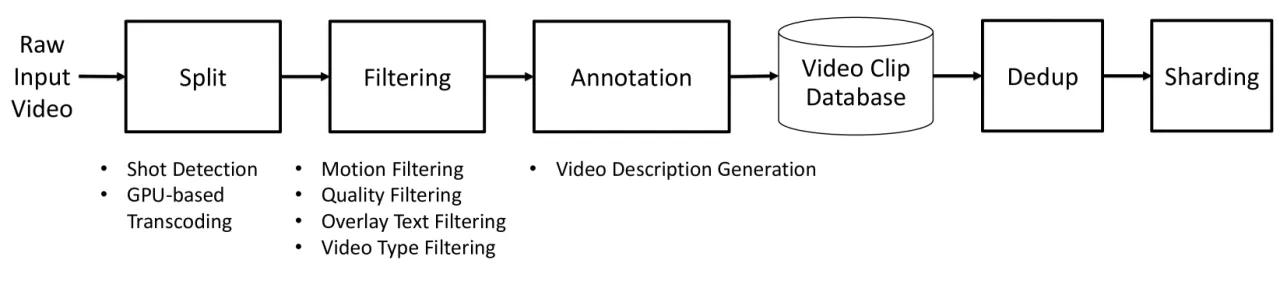
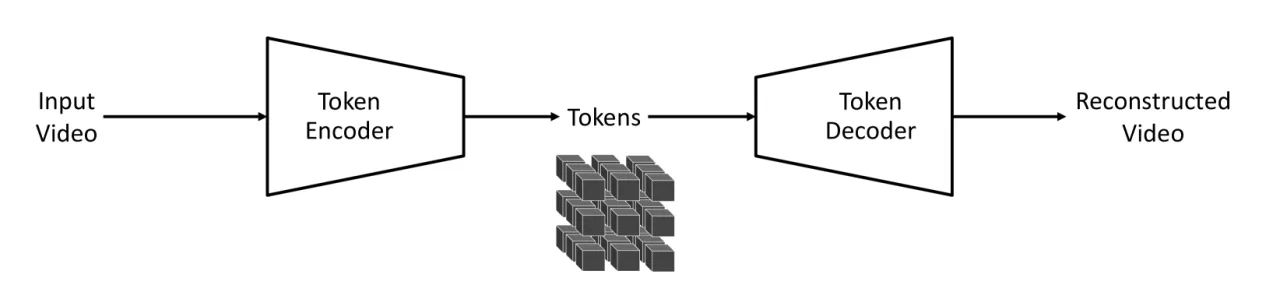
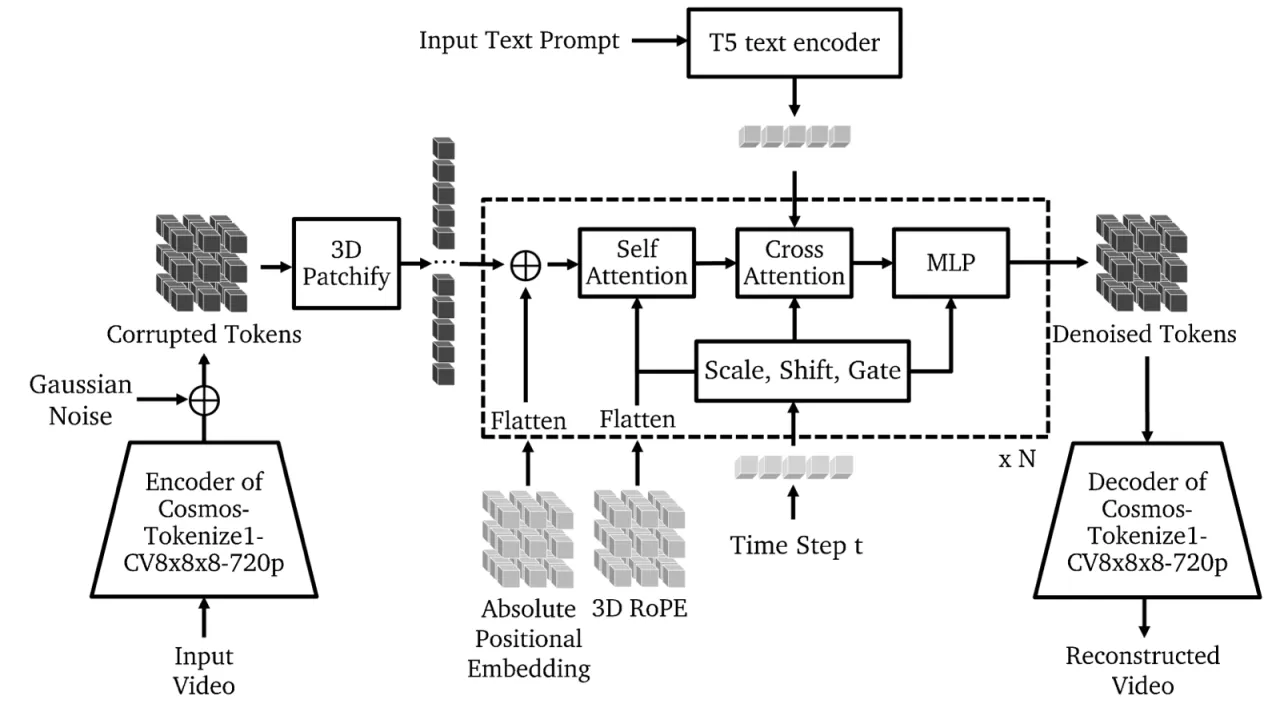
01 动机
当前 Physical AI 发展缓慢,核心瓶颈在于:现实世界中带标注的观测—动作交互数据极度稀缺,且采集成本极高。 世界模型(World Model)可以作为物理世界的"数字孪生",让智能体在仿真中安全、廉价地生成海量训练数据, 从而打破数据壁垒、加速 policy 的迭代。
"Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model."
20M小时原始训练视频
~100M处理后视频片段
7B / 14B扩散模型参数量
4B – 13B自回归模型参数量