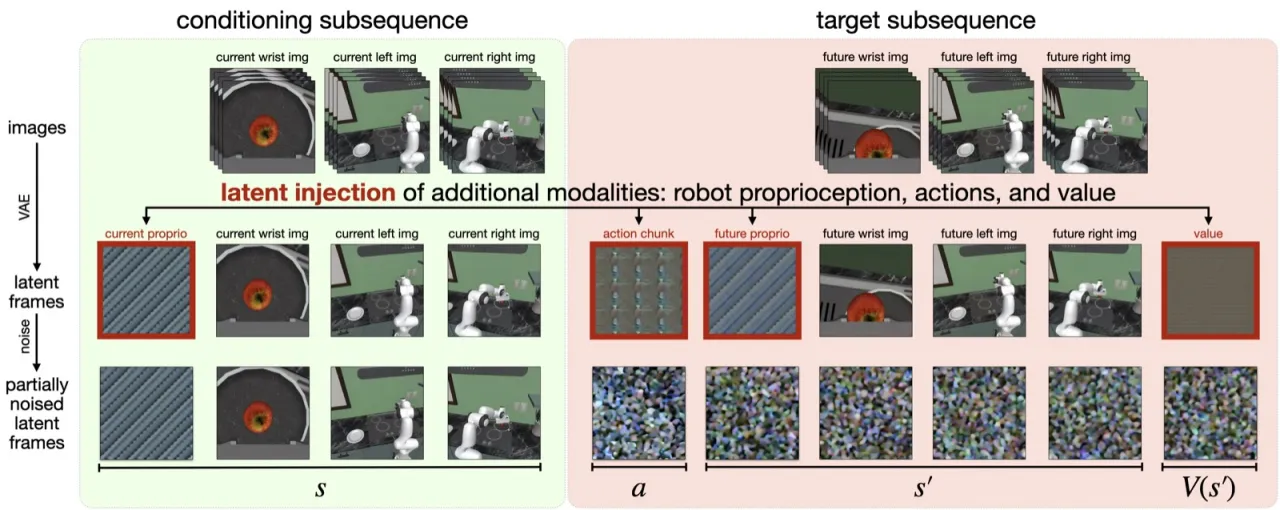
01 动机(Motivation)
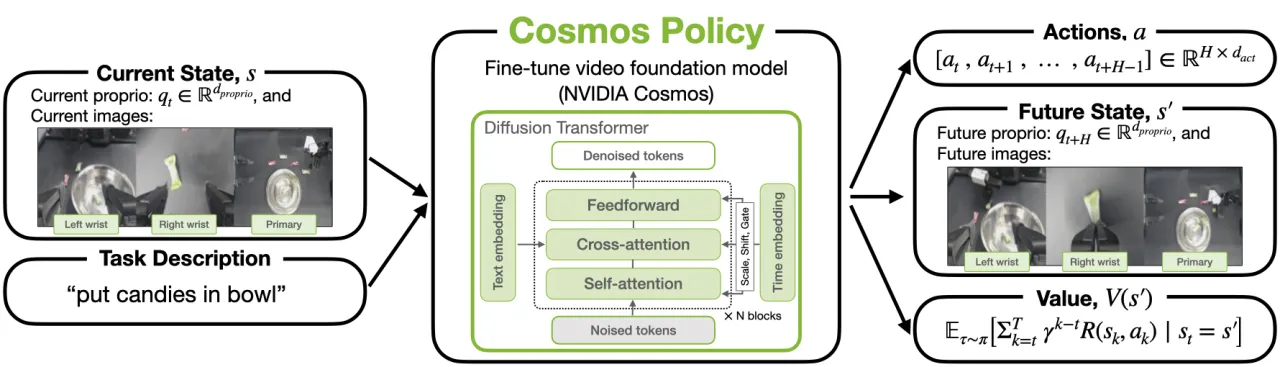
大型预训练视频生成模型捕获了丰富的时序动态与隐式物理先验,理论上是理想的机器人策略骨干网络—— 然而如何将其高效转化为可执行的控制策略,此前仍缺乏简洁的单阶段解决方案。
"large pretrained video generation models have shown impressive ability to generate physically plausible and temporally coherent videos"—— 这一能力与机器人任务高度契合,但既有方法往往需要多阶段训练或大量架构改动。
98.5%LIBERO 平均成功率(4 个任务套件)
67.1%RoboCasa 成功率(仅 50 条演示)
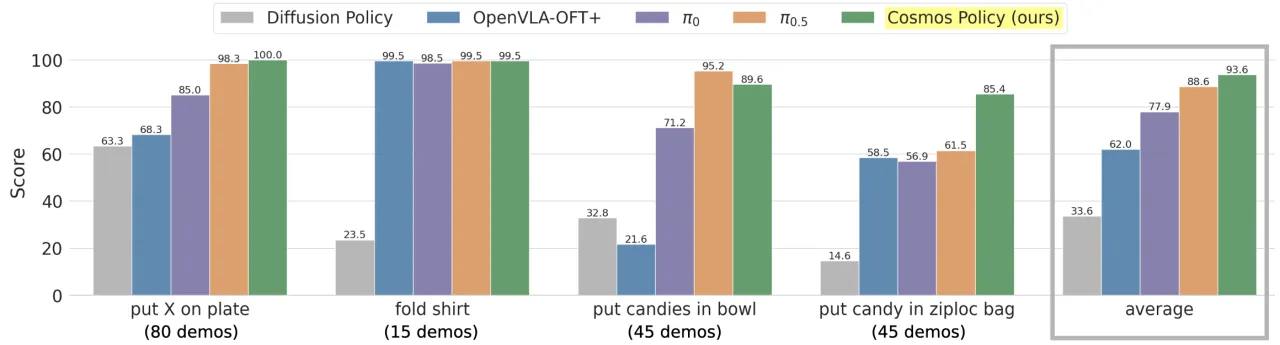
93.6ALOHA 真实机器人平均得分
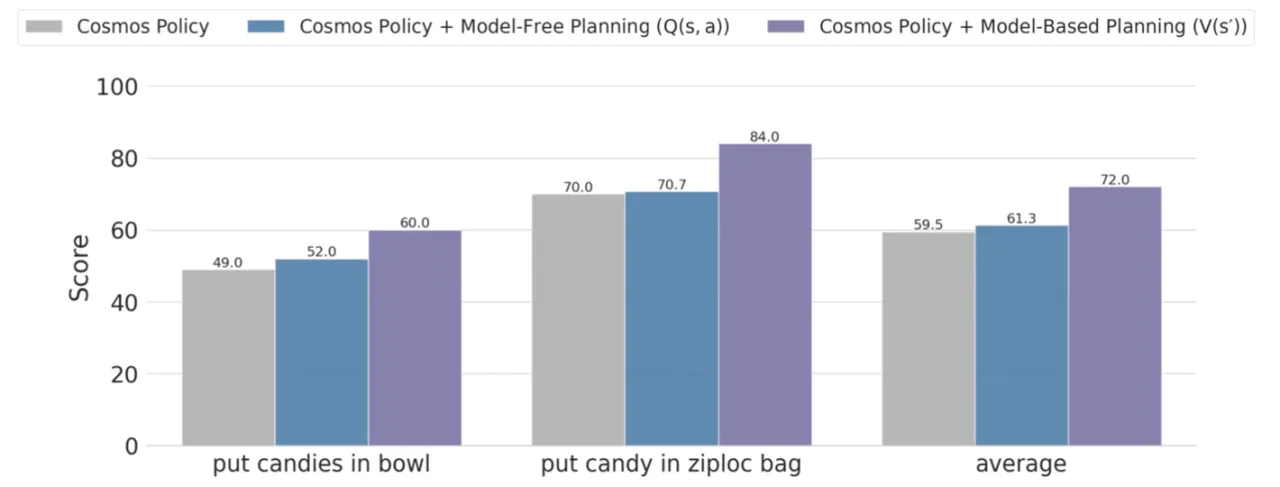
+12.5planning 在最难任务上的提升(分)