01 动机
Behavior Cloning(BC)在机器人操作领域取得了巨大成功,但绝大多数工作依赖人工遥操作收集演示数据。对于需要多接触点协调配合的接触丰富操作任务(如双臂搬运、灵巧手重定向),遥操作接口的局限性使得高质量演示的采集极为困难。
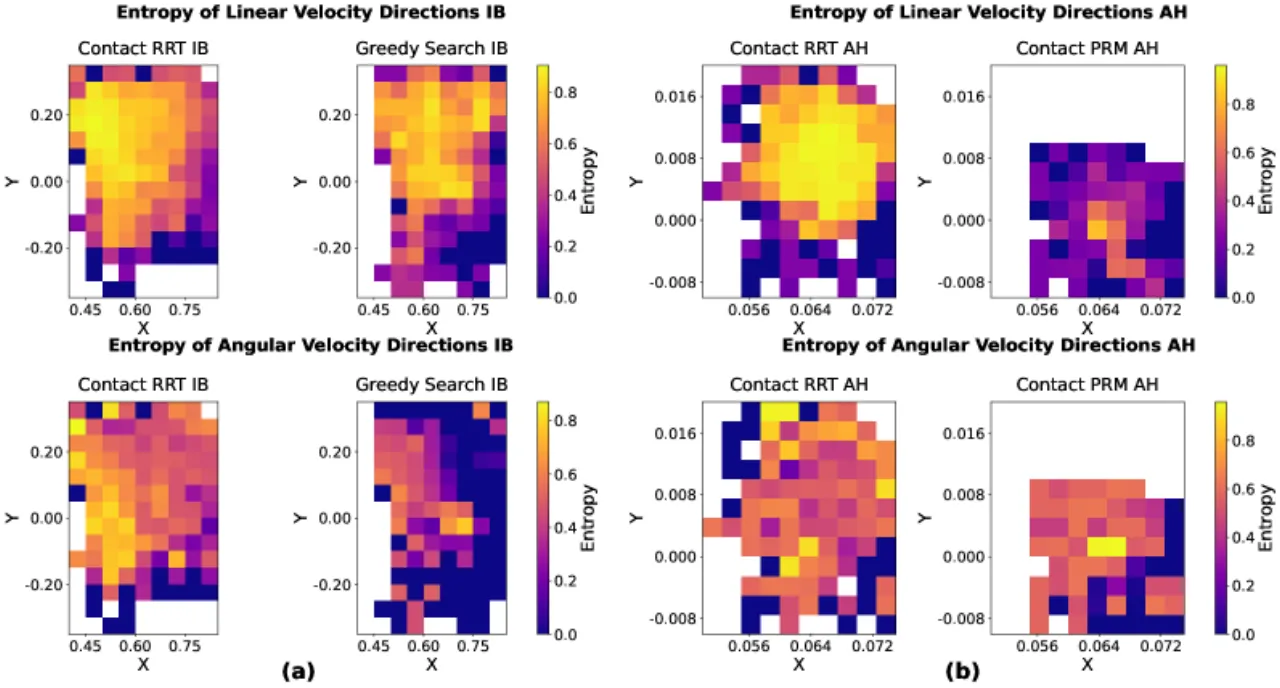
"我们的分析揭示,以 RRT(Rapidly Exploring Random Tree)为代表的流行基于采样的规划器虽然在运动规划中效率极高,却会产生具有不利的高熵特性的演示数据。"
— 原文摘要
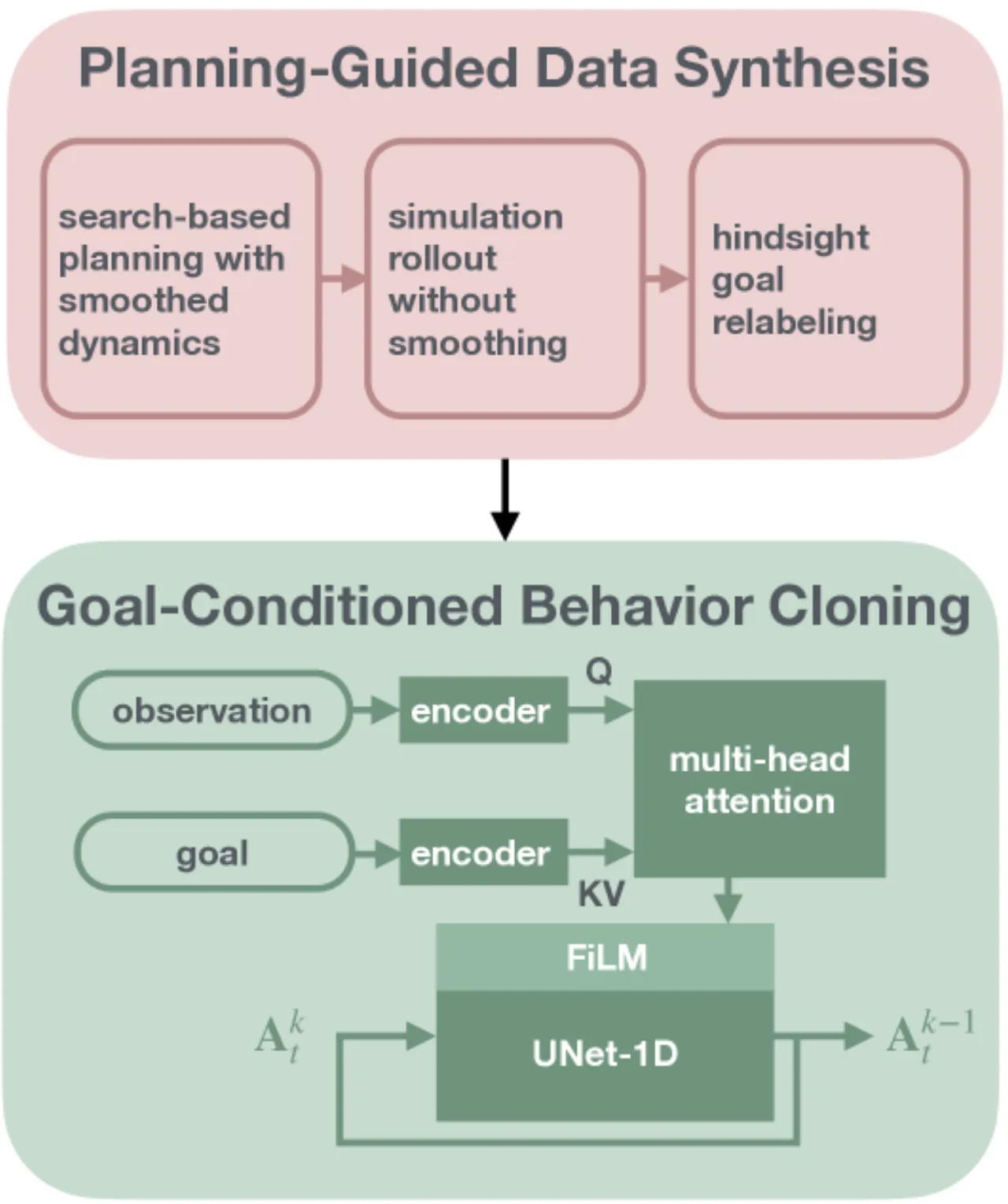
核心研究问题:能否用基于模型的规划与优化替代人工遥操作,为接触丰富的灵巧操作任务生成训练数据?RRT 等基于采样的规划器真的适合作为 BC 的数据来源吗?
99%Greedy Search · 100 条演示
IiwaBimanual 任务成功率
IiwaBimanual 任务成功率
44%Contact-RRT · 100 条演示
IiwaBimanual 任务成功率
IiwaBimanual 任务成功率
90%真机硬件
IiwaBimanual 成功率(18/20)
IiwaBimanual 成功率(18/20)
62.5%真机硬件
AllegroHand 成功率(15/24)
AllegroHand 成功率(15/24)
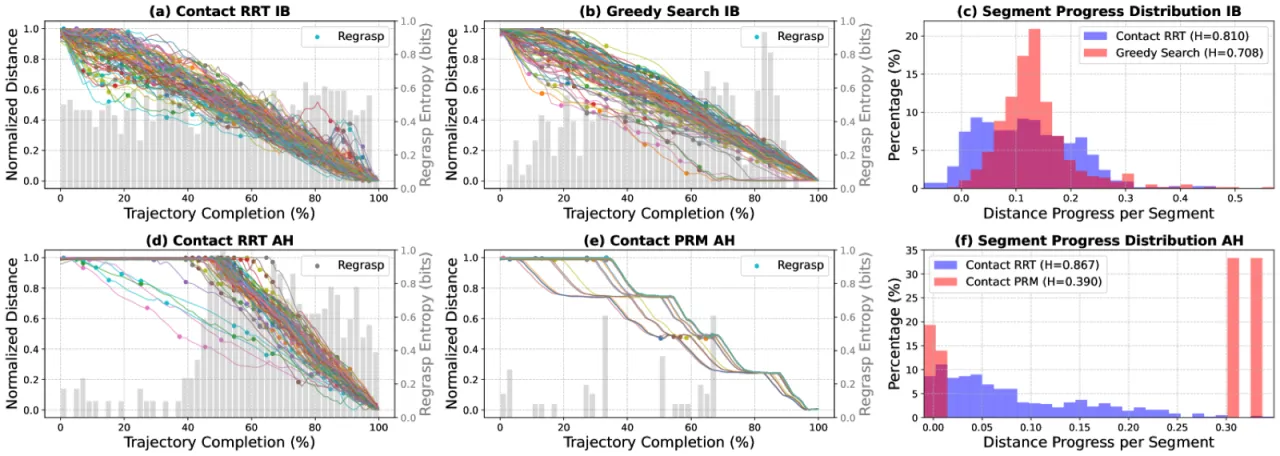
为什么 RRT 演示会"难以学习"?
作者从三个维度量化了演示熵:
- 速度方向熵(Velocity Direction Entropy):RRT 规划路径迂回,在状态空间中各位置的物体运动方向高度发散,导致在同一状态下策略需要"预测"多个截然不同的动作;
- 目标进展分布(Progress Toward Goal):RRT 演示的目标进展分布分散,甚至偶尔出现负进展(远离目标),而 Greedy Search 演示则单调收敛;
- 重新抓取熵(Regrasp Entropy):RRT 的重抓取熵几乎始终接近 1,意味着在任意时刻执行重抓取的概率约为 50%,策略无从判断何时应执行重抓取动作。