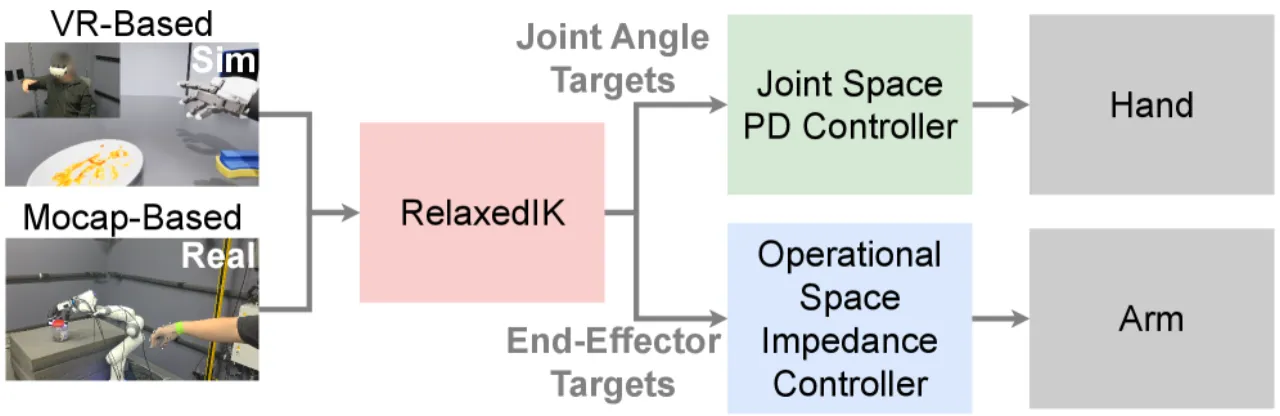
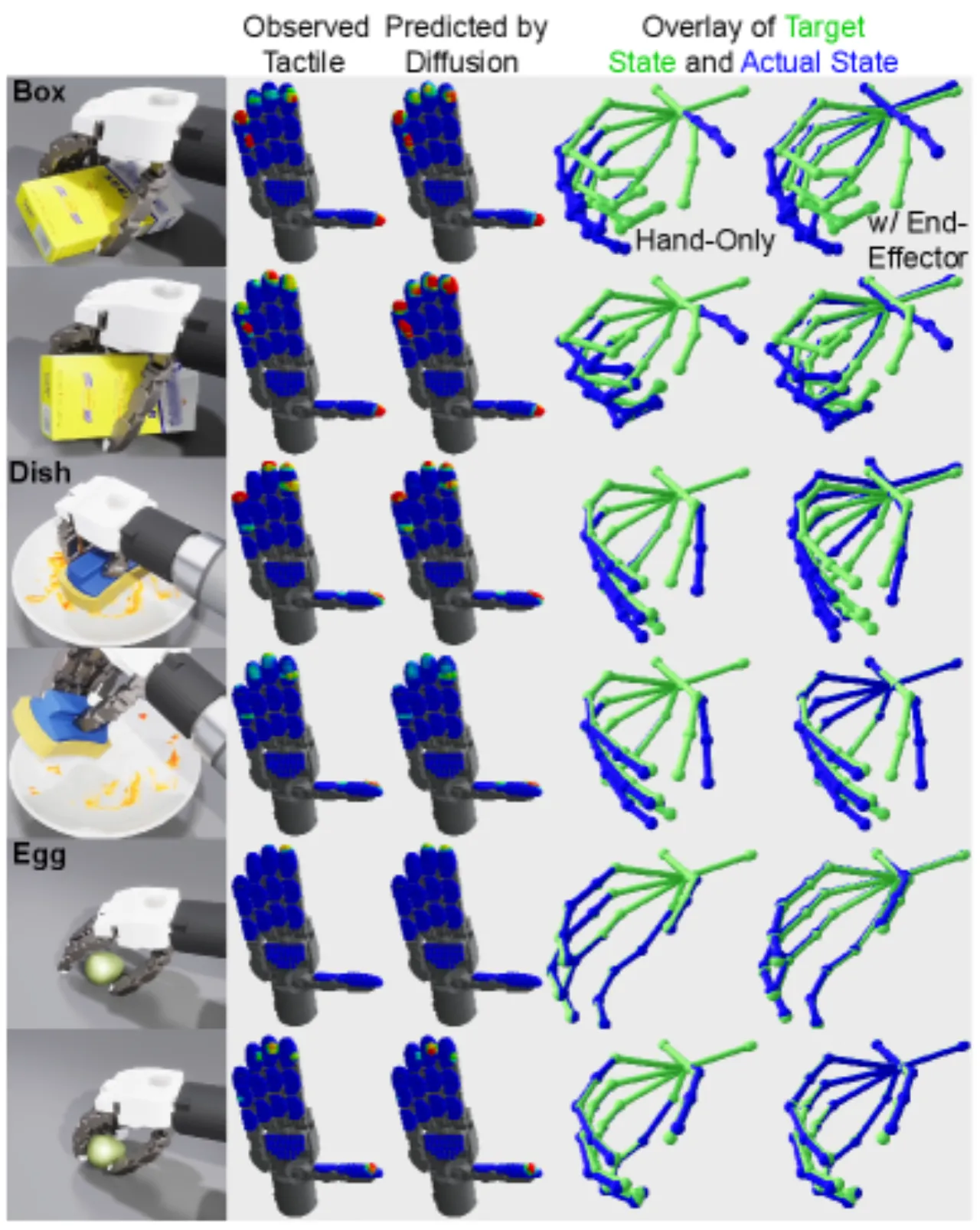
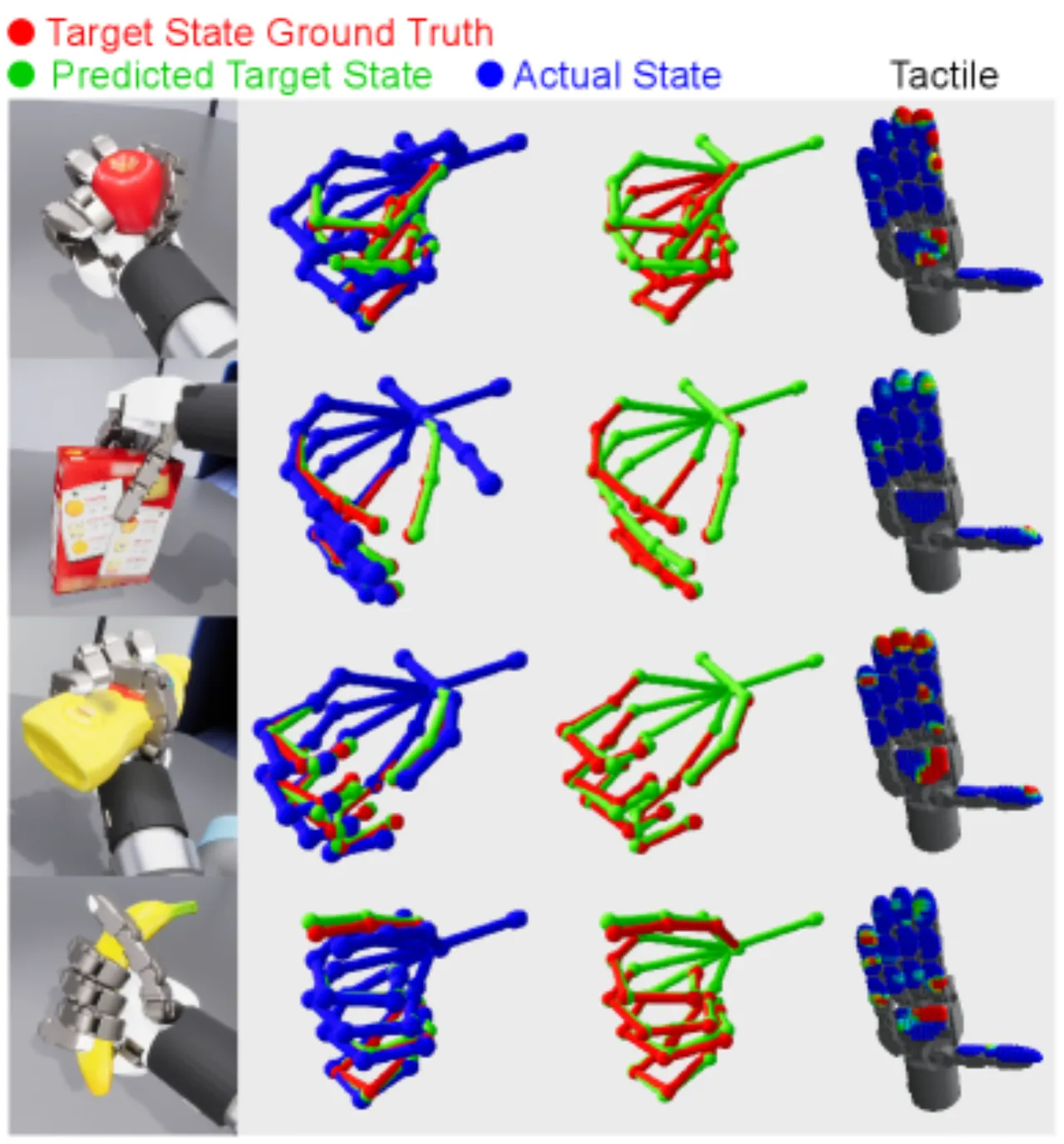
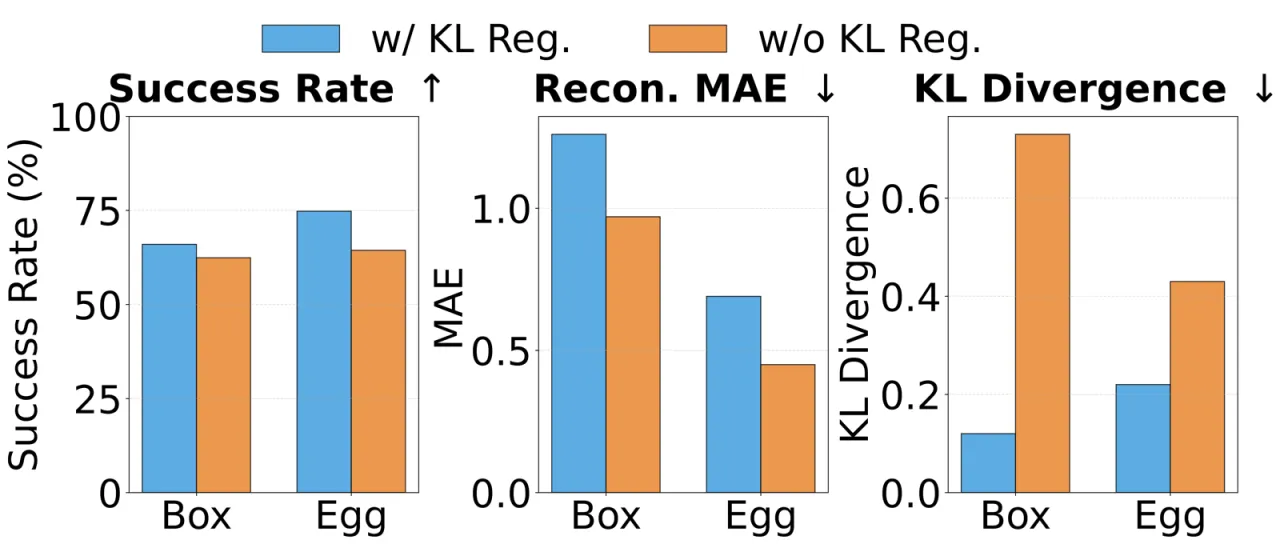
01 动机
灵巧操作需要对高维、动态变化的多点接触进行持续调控。现有方法在处理接触丰富任务时均存在明显短板: 以抓取为中心的流水线在完成抓取后限制了手指运动;强化学习面临繁琐的奖励工程与 sim-to-real 迁移难题; 模仿学习虽可扩展,但在接触丰富任务上表现不佳。
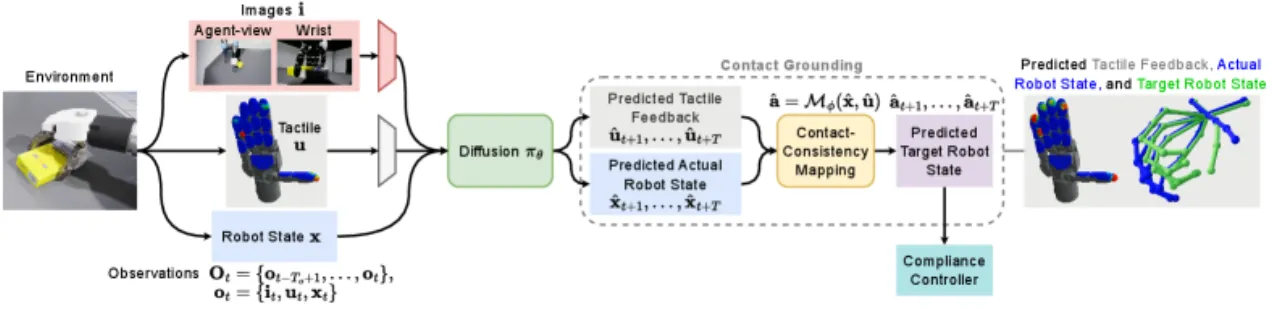
"Policies must go beyond using tactile signals as additional observations and instead model contact state and how action outputs interact with low-level controller dynamics."
—— 论文第 I 节,Introduction
80.0%真实机器人 In-Hand Box Flipping 成功率(CGP)
93.3%真实机器人 Jar Opening 成功率(CGP)
+13.3~26.7%真实任务相对 Visuotactile DP 的提升幅度
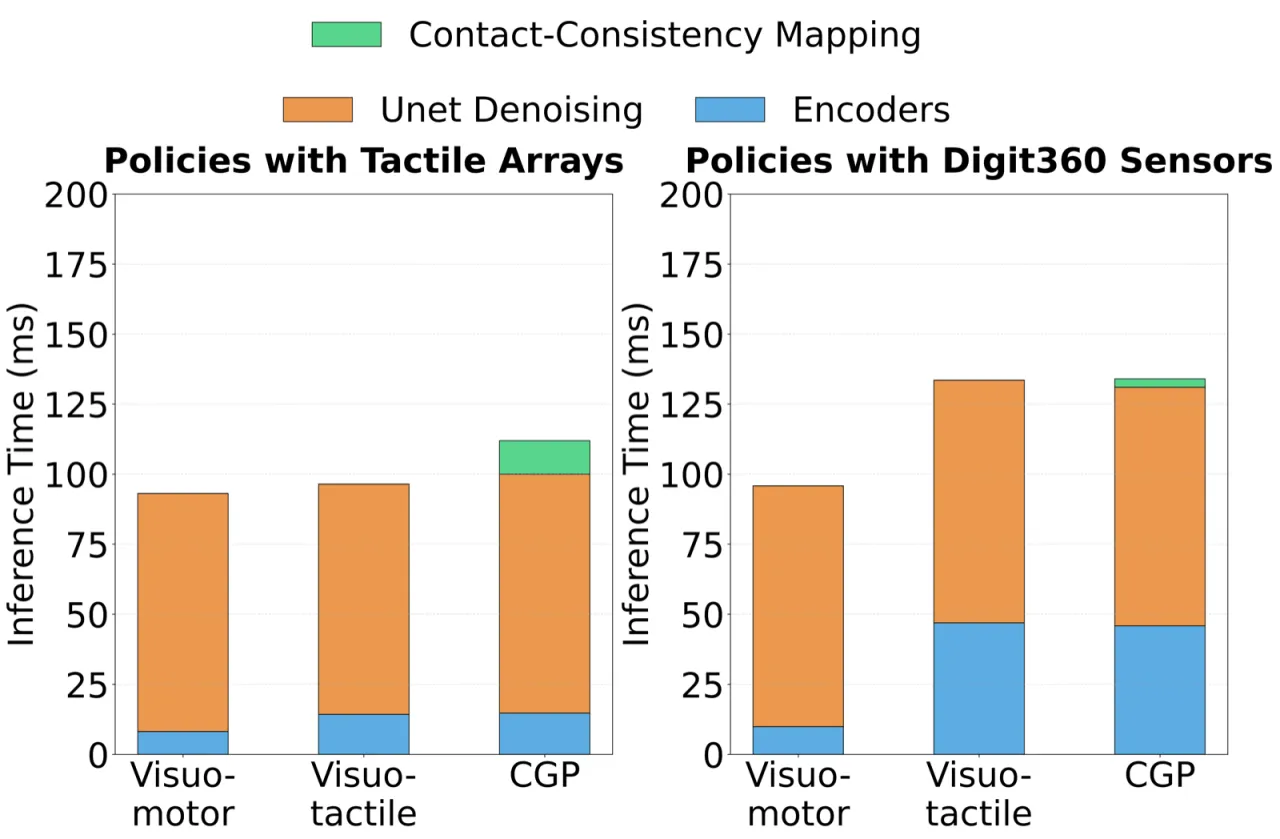
5 Hz策略推理频率(8步 DDIM 降噪)
三种现有范式的对比
| 策略范式 | 可执行接触建模 | 多指手支持 | 分布式接触可扩展性 |
|---|---|---|---|
| Adaptive Compliance Policies | ✓ | 受限(单末端执行器) | ✗ |
| Sparse Fingertip Force Policies | ✗ | ✓ | 有限 |
| Contact-Grounded Policy (CGP) | ✓ | ✓ | ✓ |