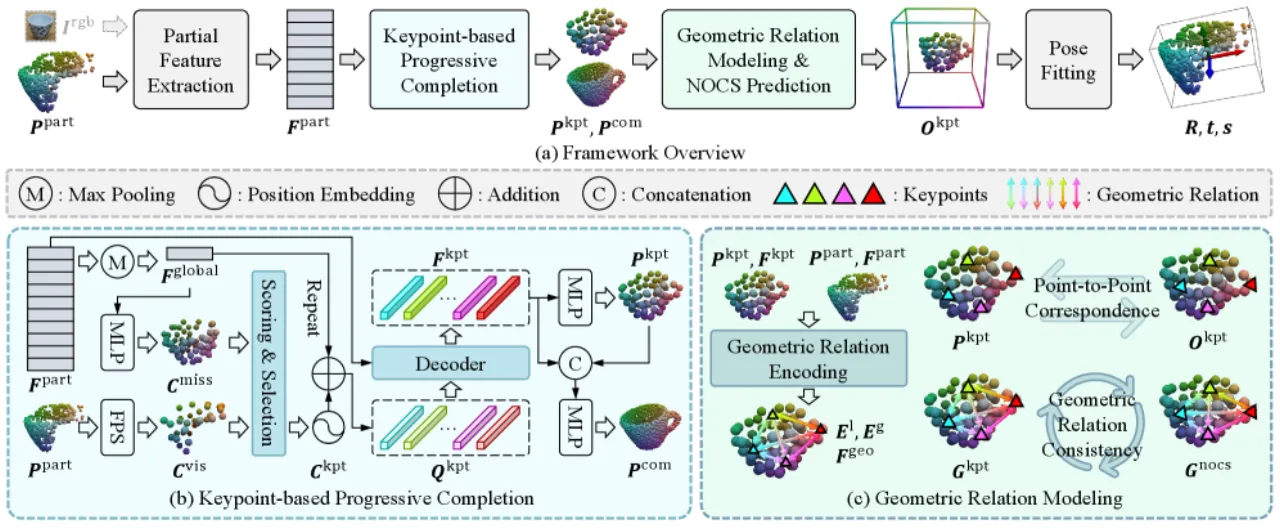
01 动机
类别级物体姿态估计旨在预测特定类别内任意物体的 6D 姿态与 3D 尺寸,无需实例级 CAD 模型。 现有方法的核心瓶颈:观测点云的固有不完整性——深度相机因自遮挡只能捕获物体正面,导致网络无法感知完整形状。
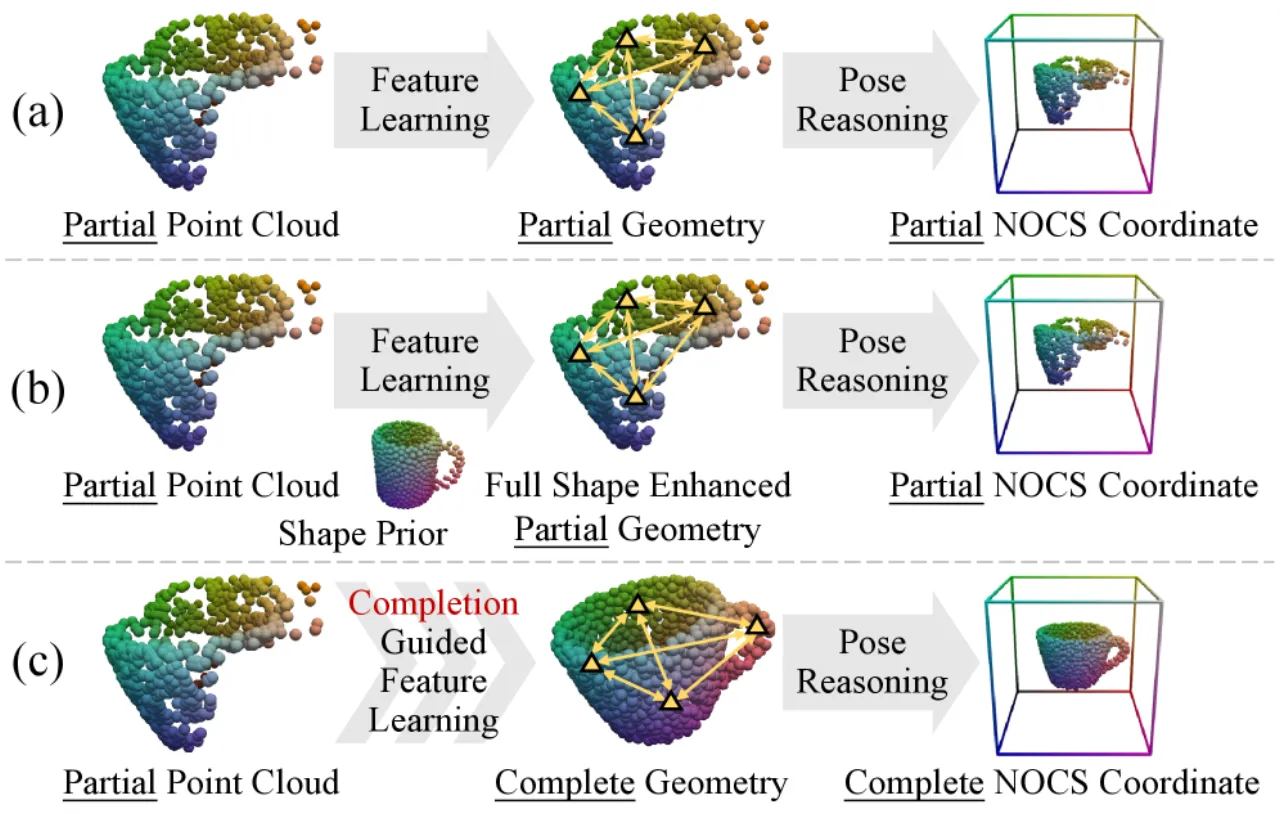
"how can we effectively and efficiently integrate the complete geometric cues recovered from point cloud completion to enhance object pose estimation?"
作者通过 oracle 实验量化了完整几何的上界价值:将 AG-Pose(当前最优 depth-only 方法)的输入替换为 ground-truth 完整点云(网络架构不变),10°2cm 精度从 68.5% 跃升至 91.7%,增幅高达 23.2 个百分点。 但朴素的"先补全再估计"两阶段流水线仅能达到 71.0%,且推理速度从 33.5 FPS 骤降至 21.5 FPS——说明简单级联补全与估计网络无法充分挖掘完整几何的潜力。

+9.3%10°2cm vs AG-Pose
(depth-only, REAL275)
(depth-only, REAL275)
38.4 FPS推理速度
RTX3090Ti
RTX3090Ti
91.7%Oracle 上界
完整点云输入
完整点云输入
无先验不依赖
类别形状先验
类别形状先验