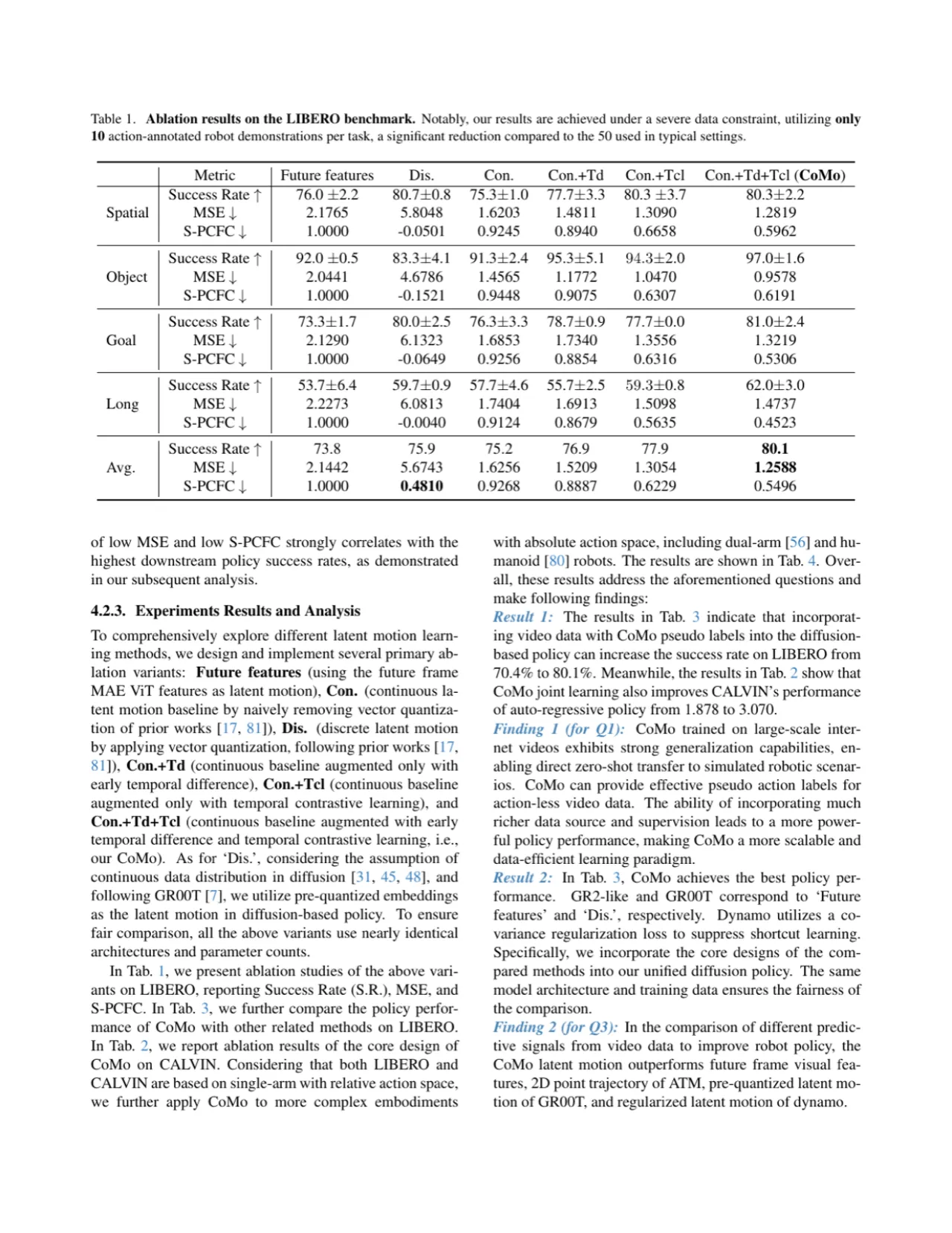
02 方法 · Method
CoMo 以标准 IDM-FDM(Inverse Dynamics Model / Forward Dynamics Model)架构为基础,引入两个关键设计:早期时序差分(Early Temporal Difference, Td)机制增强运动线索,时序对比学习(Temporal Contrastive Learning, Tcl)方案使潜在运动聚焦前景。两者协同作用,无需向量量化即可学到精确的连续潜在运动表示。

Early Temporal Difference(Td)机制
传统 IDM 直接以原始帧 Ot、Ot+n 为输入,编码器容易捕捉帧间背景差异作为捷径。CoMo 在进入编码器之前,先计算帧差特征 Dt = Ft − Ft+n(token 级特征减法),用差分代替原始帧喂入 IDM。差分操作显式消除了静态背景的共同信息,迫使编码器关注真正发生变化的前景区域,从而提升潜在运动对运动线索的敏感度。同时,FDM 以潜在运动 Z(t,t+n) 为条件,在 pooled 帧特征之上重建未来帧 Ôt+n,采用 pixel-level 精度损失确保运动信息足够精细。
Temporal Contrastive Learning(Tcl)方案
为进一步确保潜在运动聚焦于有意义的前景,CoMo 引入 Tcl。核心思想是:
- 正样本对:以小时间偏移 δ 的未来帧 Z(t,t+δ) 构造,两者描述相似的短期运动方向。
- 负样本对:直接反转时序方向得到 Z(t+δ,t),描述运动的反方向。
对比损失使用 InfoNCE,使正对在嵌入空间中相互靠近,负对远离。这一方案鼓励潜在运动编码"方向性运动"而非"背景外观变化",与 Td 机制协同作用,共同解决捷径学习问题。
"The proposed Td and Tcl work synergistically and effectively ensure that the latent motion focuses better on the foreground and reinforces motion cues."
联合策略学习(Joint Policy Learning)
CoMo 具备强零样本泛化能力:训练完成后,直接将 IDM 应用于未见的机器人操控视频,生成伪动作标签(pseudo action labels)用于下游策略训练。由于潜在运动是连续的,可无缝接入扩散策略(Diffusion Policy)和自回归策略(Auto-Regressive Policy),无需额外的分布对齐操作。具体地,联合学习时,CoMo 为视频数据提供运动标签,与机器人遥操作数据共同训练统一策略模型,实现视频数据规模化扩展。