01 动机
现有大型视觉语言模型(VLM)无法满足复杂3D游戏战斗场景对"秒级响应、高分辨率感知和动态战术推理"的实时要求,而专用小模型又缺乏足够的通用视觉理解能力。
"Real-time decision-making in complex 3D environments … demand second-level responses, high-resolution perception, and tactical reasoning under dynamic conditions."
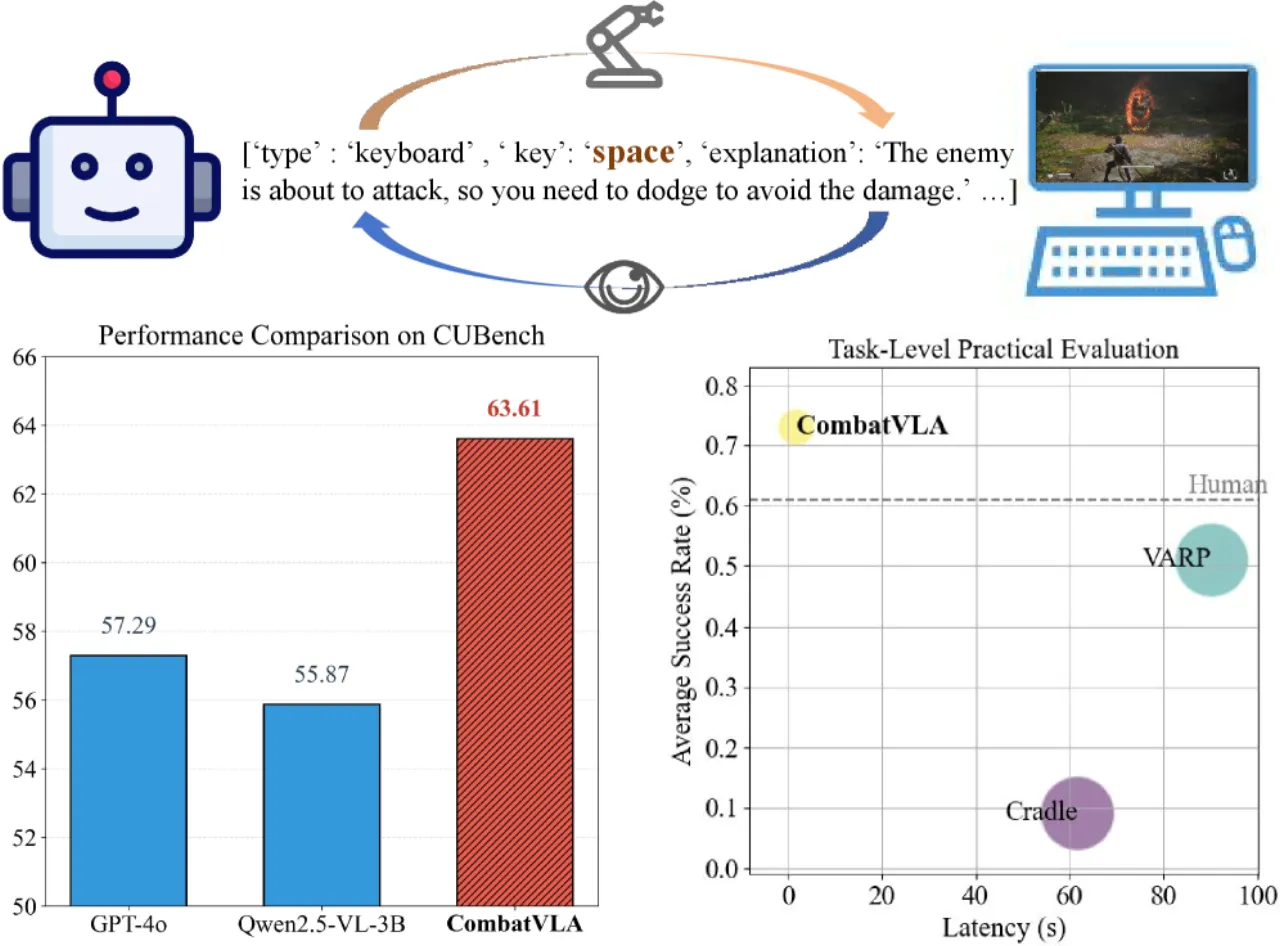
50×比 VARP 快(推理延迟)
63.61%CUBench 平均准确率(第一名)
1.85s单次推理延迟
3B模型参数量
现有方案的核心瓶颈在于:
- 通用 VLM(GPT-4o, Gemini):需要60–90秒推理,完全无法用于实时战斗控制。
- 框架型方案(Cradle, VARP):多次模型调用(5–10次)叠加延迟,1次战斗指令需61–90秒;且高度依赖提示工程。
- 专用小型模型:缺乏对复杂战斗场景的感知和推理能力。
CombatVLA 的目标是在单次1.85秒推理内完成"观察→思考→行动"的完整闭环,同时保持通用视觉能力不大幅退化。