01 动机
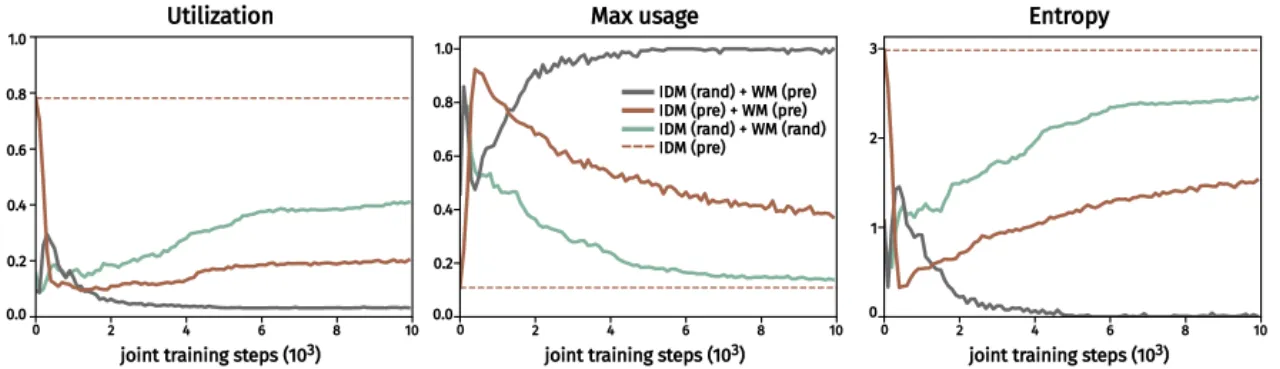
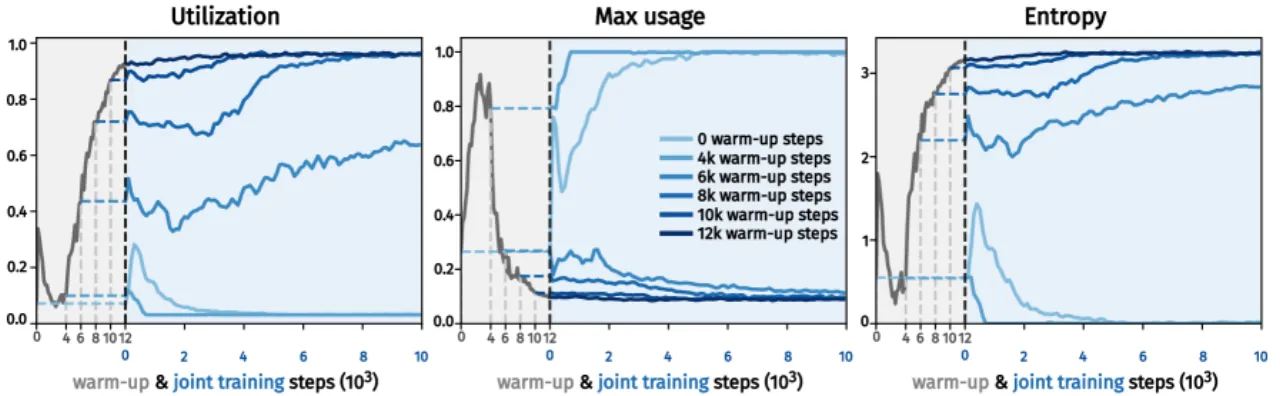
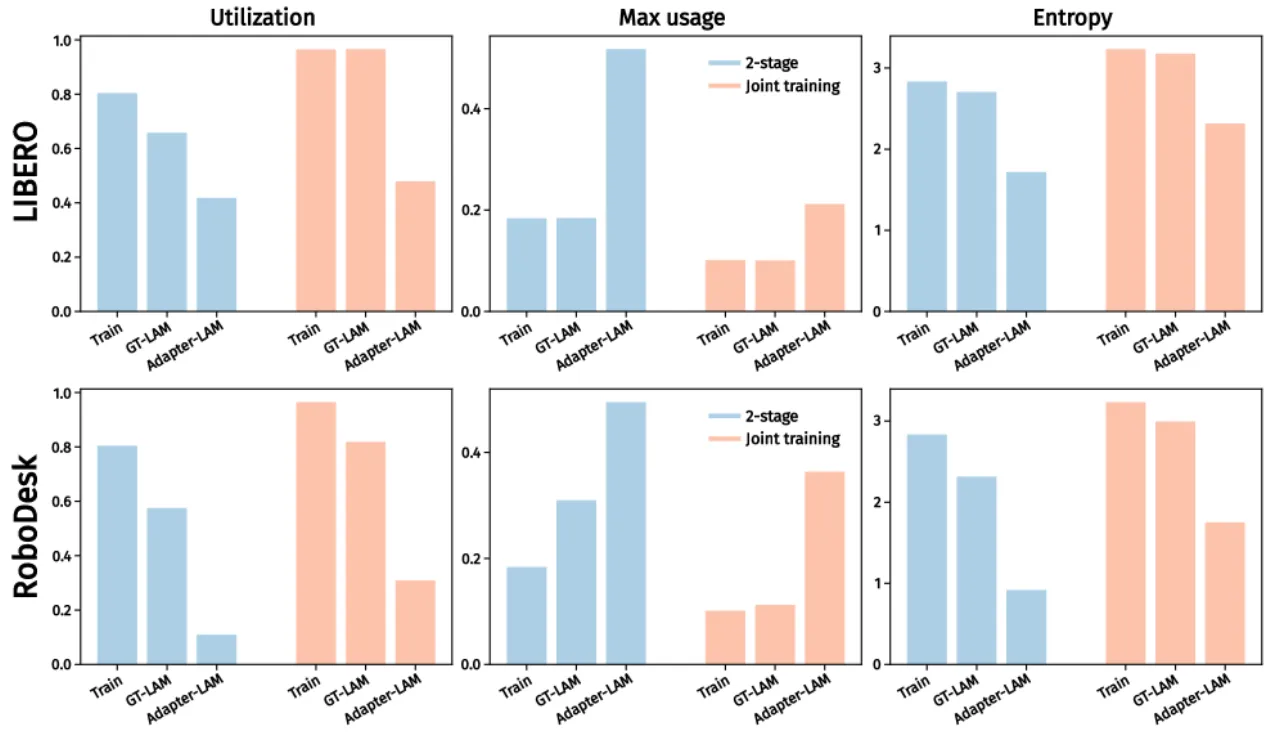
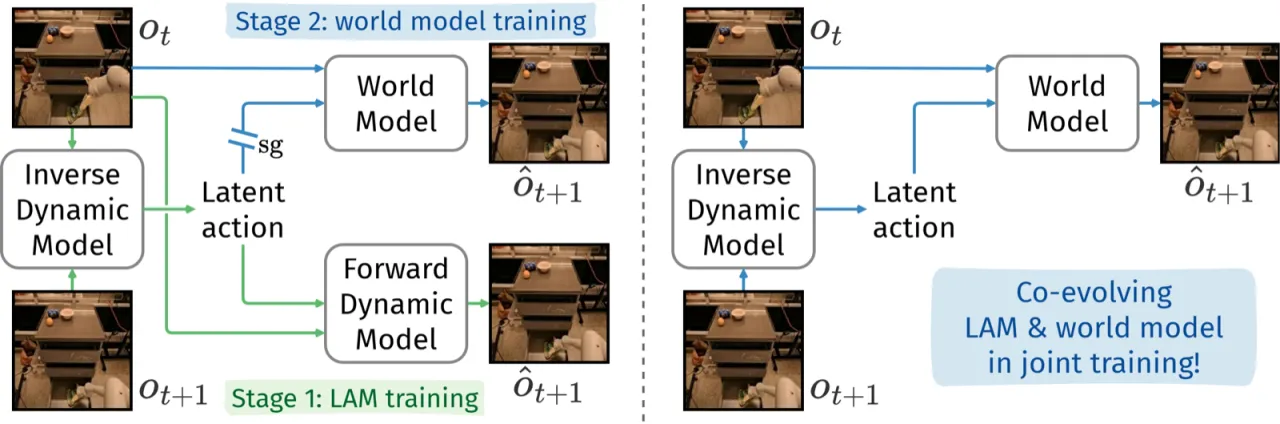
机器人和视频生成领域普遍采用"latent action model(LAM)+ world model(WM)"的两阶段流水线:先用 inverse dynamics model(IDM)从无标注视频中学习 latent action codebook,再将 codebook 固定,训练以 latent action 为条件的 world model。这种分离训练方式存在根本性冗余——IDM 内部的 forward dynamics model(FDM)与 WM 本质上做的是同一件事(预测下一帧),却各自为政、无法相互促进。
"We argue that there is an inherent redundancy in the design: the FDM and the world model perform almost identical functions, both modeling the transition dynamics of the environment."
2.73×视觉规划平均成功率提升(joint vs two-stage,VP2 benchmark)
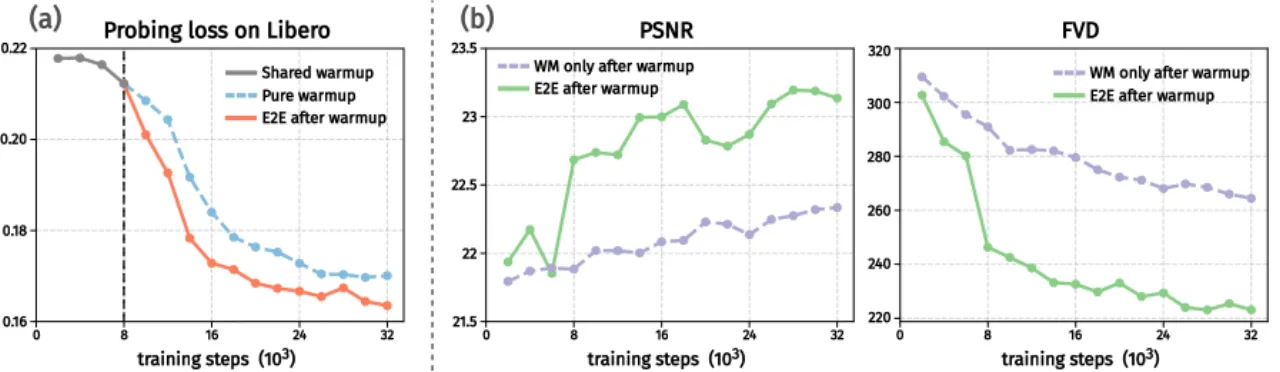
158.36FVD(joint)vs 167.06(two-stage),LIBERO OOD 视频预测
35.33%Upright Block 任务成功率(joint),vs two-stage 22.00%
38K步联合训练(计算量更少)即可达到或超越 60K 步两阶段基线