01 动机
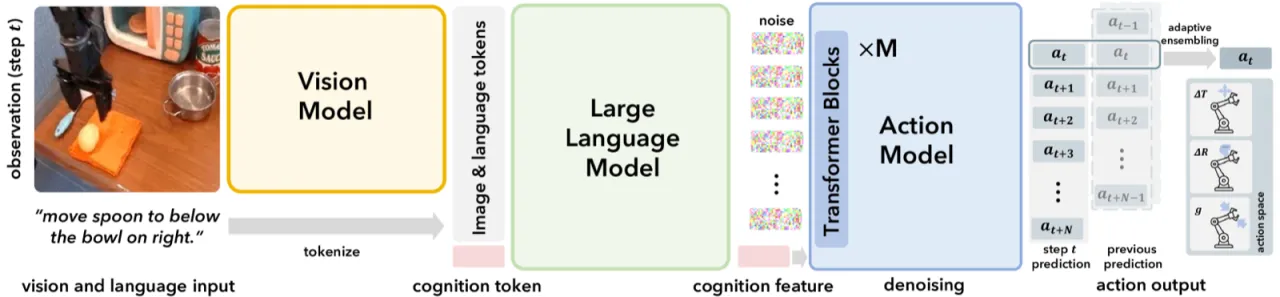
现有 VLA 模型将视觉语言模型(VLM)直接用于动作预测,通常通过动作量化或简单回归头来输出控制指令,忽略了机器人动作预测与语言 token 生成之间的本质差异,导致泛化能力和精度受限。
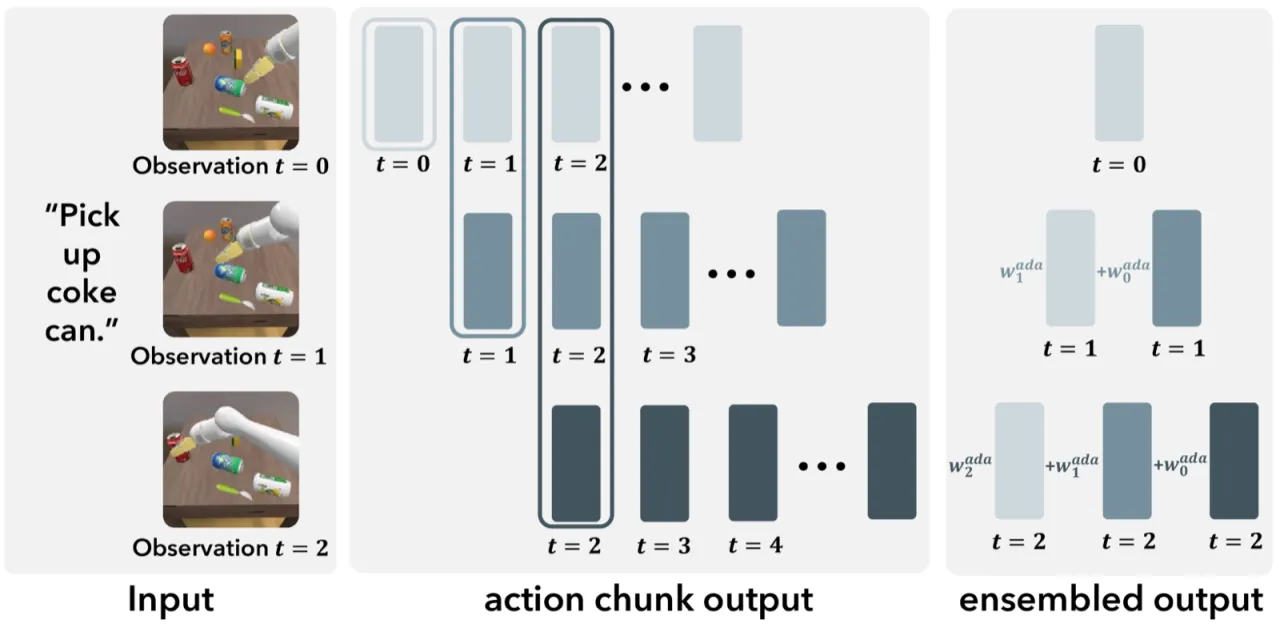
"Rather than naively adapting pretrained VLMs for action prediction through simple action quantization or adding regression heads, we propose a componentized VLA architecture with specialized action modules."
现有方法存在两大问题:第一,动作空间是连续的高维多模态分布,离散化会丢失精度;第二,视觉语言模型的 next-token 预测范式并不适合时序动作序列建模。CogACT 的核心动机在于"认知"(理解场景与指令)和"行动"(输出精确控制序列)应由专门模块分别承担。
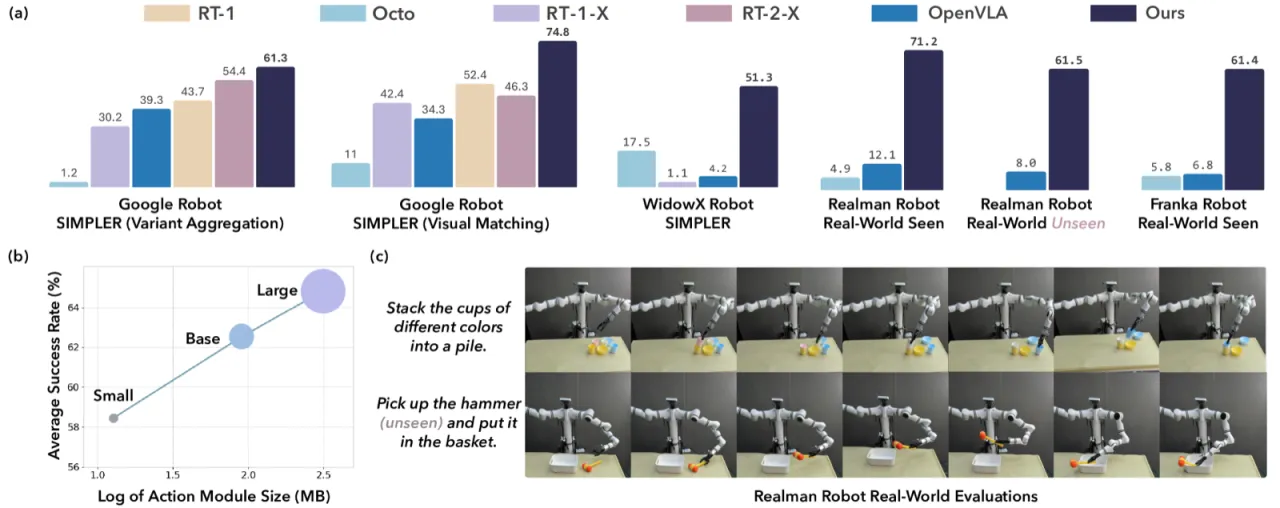
74.8%Google Robot 仿真平均成功率
(vs OpenVLA 34.3%)
(vs OpenVLA 34.3%)
71.2%Realman 真实机器人平均成功率
(vs OpenVLA 12.1%)
(vs OpenVLA 12.1%)
61.4%Franka 真实机器人平均成功率
(vs OpenVLA 6.8%)
(vs OpenVLA 6.8%)
>35%仿真中相对 OpenVLA 的成功率提升幅度