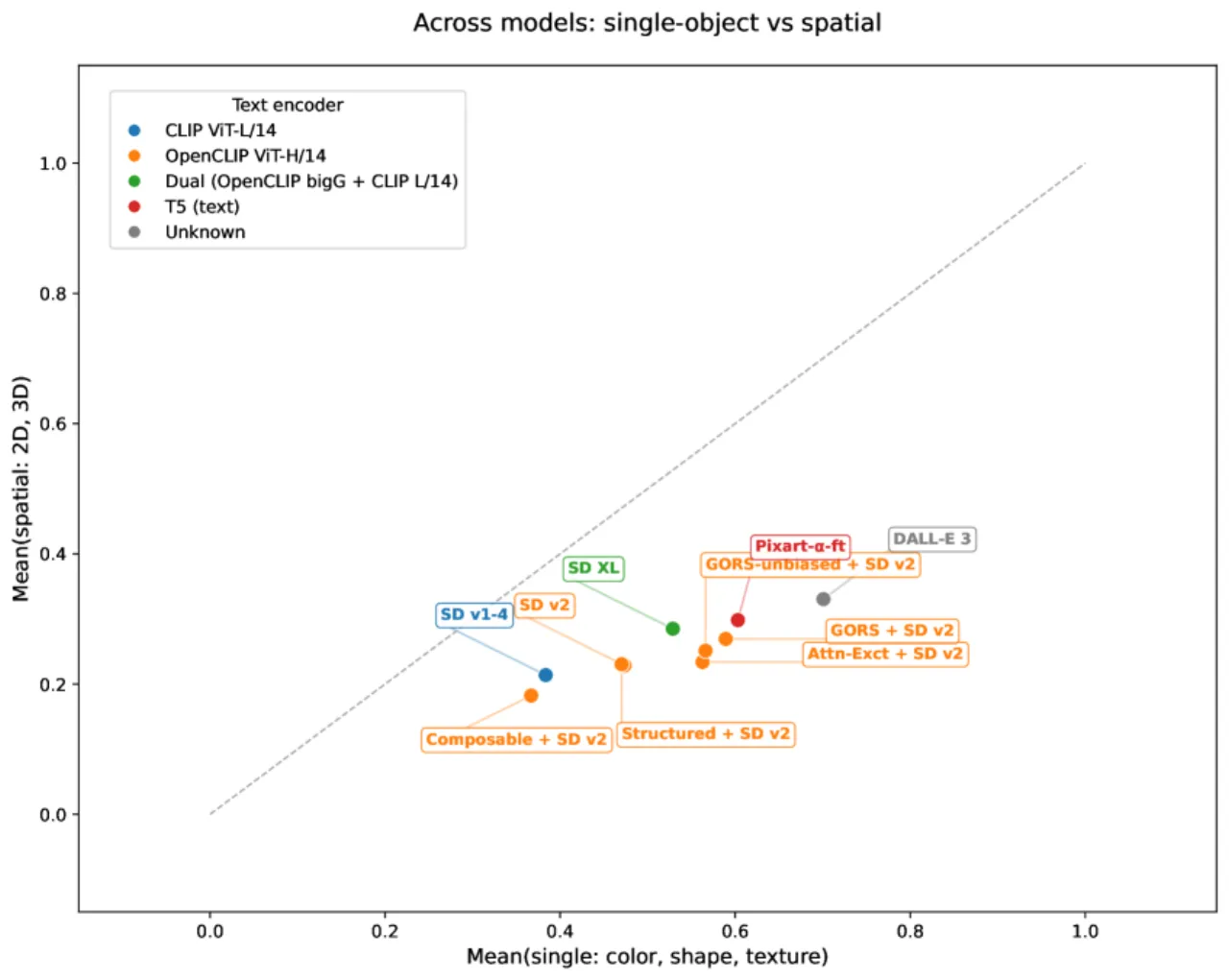
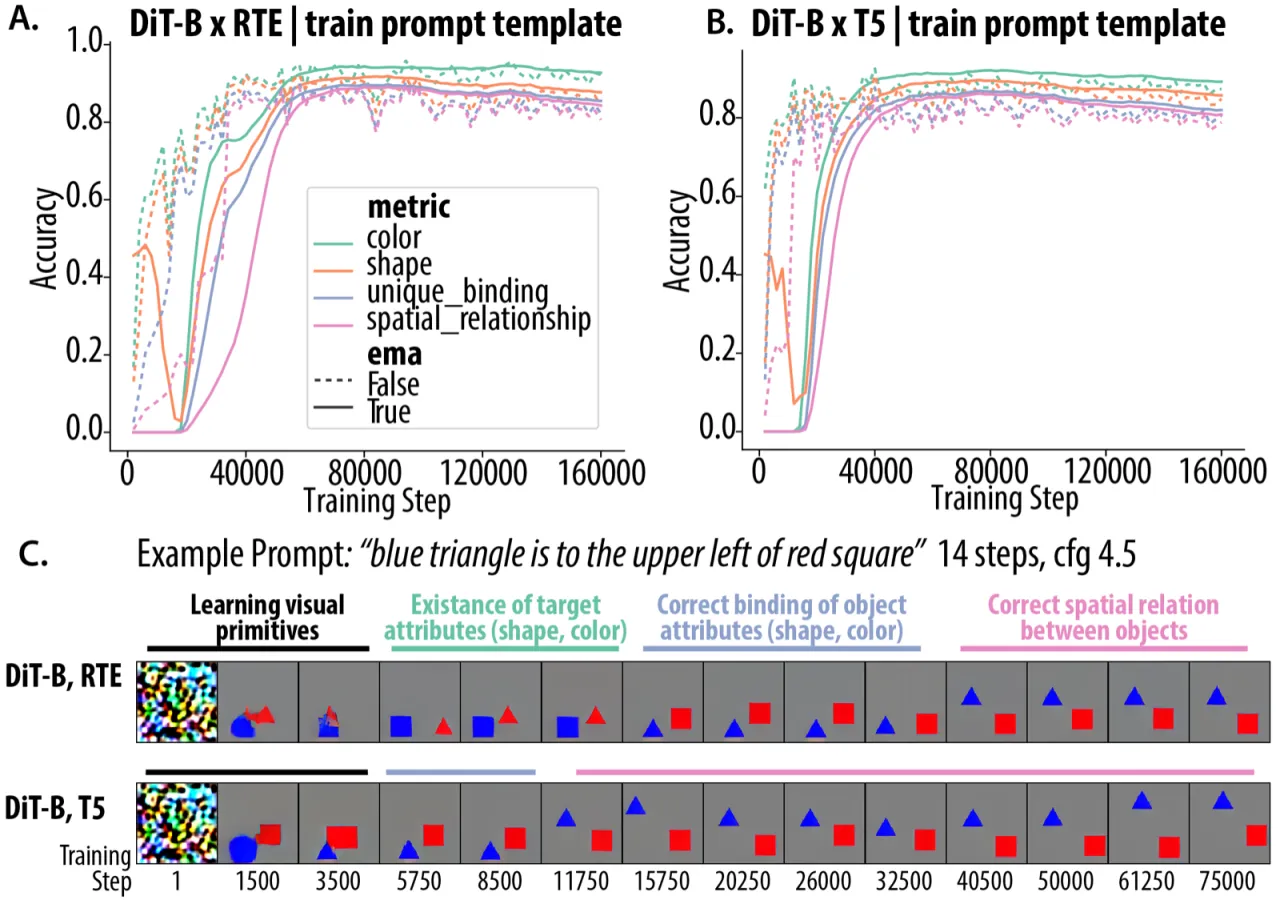
02 方法
研究采用"受控数据集 + 从头训练"的范式,配合提出的 Attention Synopsis 方法,
系统地在扩散时间步和空间 token 两个维度上定位关键注意力头,再通过消融和因果干预验证其功能。
受控数据集构建
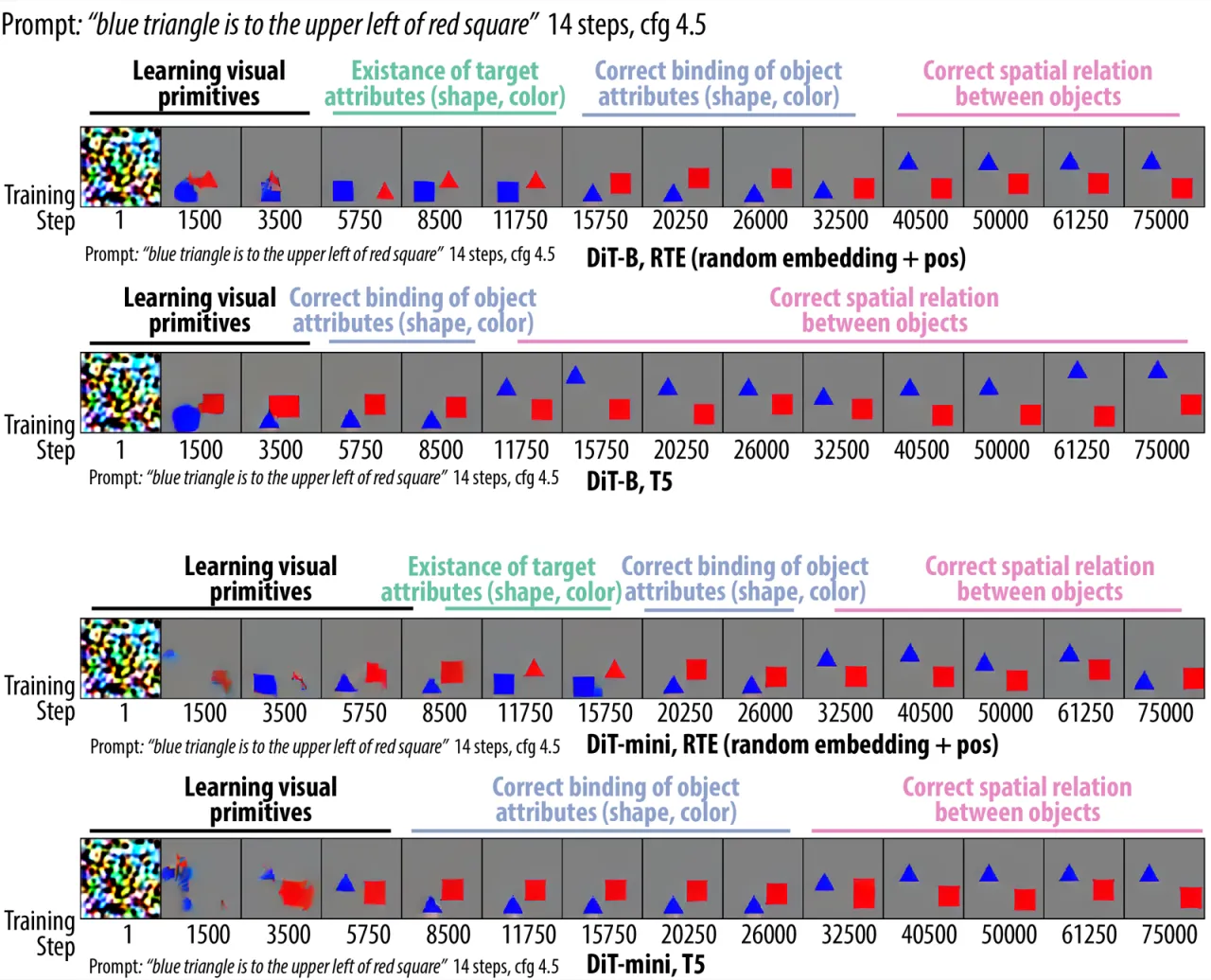
图2:数据集设计。
图像包含两个有颜色的几何形状(3 种形状:circle / triangle / square;2 种颜色:red / blue),
背景为灰色,物体位置避免碰撞。
Prompt 格式为 [color A] [shape A] [relation] [color B] [shape B],
共 8 种空间关系(left / right / above / below / upper-left / upper-right / lower-left / lower-right)。
评估集包含 96 条 prompts(8 关系 × 12 物体对)。
PixArt 风格模型架构
模型采用 PixArt-style 架构,由三部分组成:
文本编码器 :分别使用 T5-XXL(预训练)、Random Token Embedding (RTE)、或 RTE 无位置编码三种配置VAE :来自 Stable Diffusion 的预训练 VAEDiffusion Transformer 主干 :测试 DiT-B (12L, 12H, 768d)、mini (6L, 6H, 384d)、micro (6L, 3H, 192d)、nano (3L, 3H, 192d) 四种规模
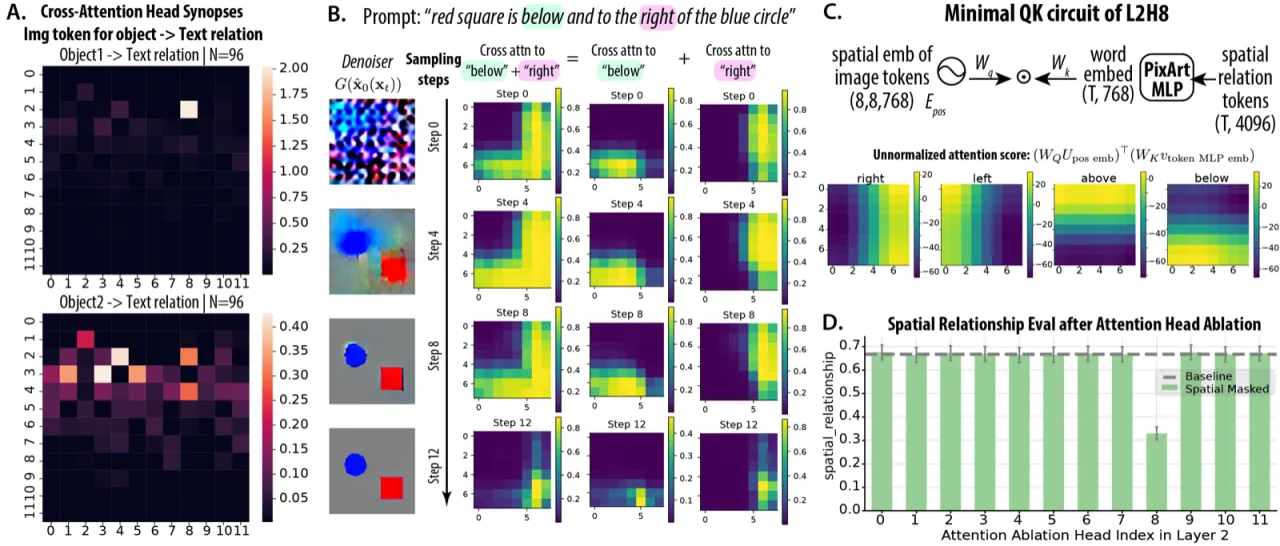
Attention Synopsis 方法
本文提出 Attention Synopsis :对所有扩散时间步的注意力图取汇总统计,
并在所有 prompt 条件下聚合,从而识别"对特定语义变量(如 relation)有选择性响应"的注意力头。
这避免了只看单一时间步带来的偶然性,能系统筛查模型中的稀疏功能电路。
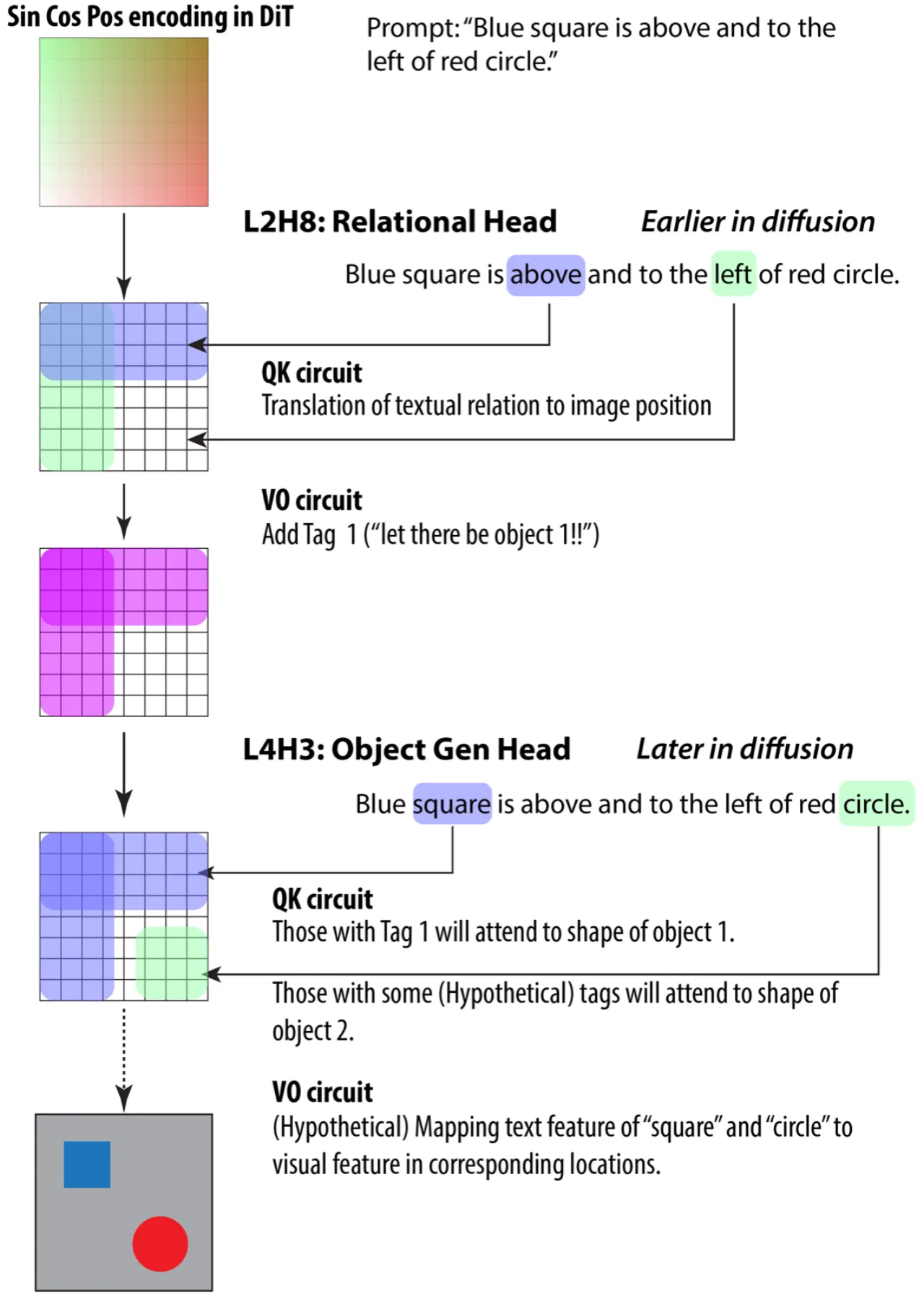
图3:RTE-DiT 中发现的两阶段空间电路示意图。
第一阶段(Stage 1):Layer 2 Head 8(L2H8)为"空间关系头",读取 relation token 的 key,
将正弦位置编码映射为空间梯度(如"above"对应竖向梯度);
第二阶段(Stage 2):Layer 4 Head 3(L4H3)为"物体生成头",
接收来自 L2H8 的位置标记,将其与物体 shape token 匹配并在对应位置生成物体。
Stage 1:空间关系头 (L2H8)
通过 QK circuit 读取 relation text token
将正弦位置编码变换到 query 空间,relation embedding 变换到 key 空间
输出平滑的空间梯度(如"above"→竖向梯度)
在采样步骤 step 0 即开始激活
Stage 2:物体生成头 (L4H3)
接收来自关系头的位置标记
将标记位置与物体 shape token 匹配
在对应空间位置生成物体
在采样步骤 4–8 后期激活
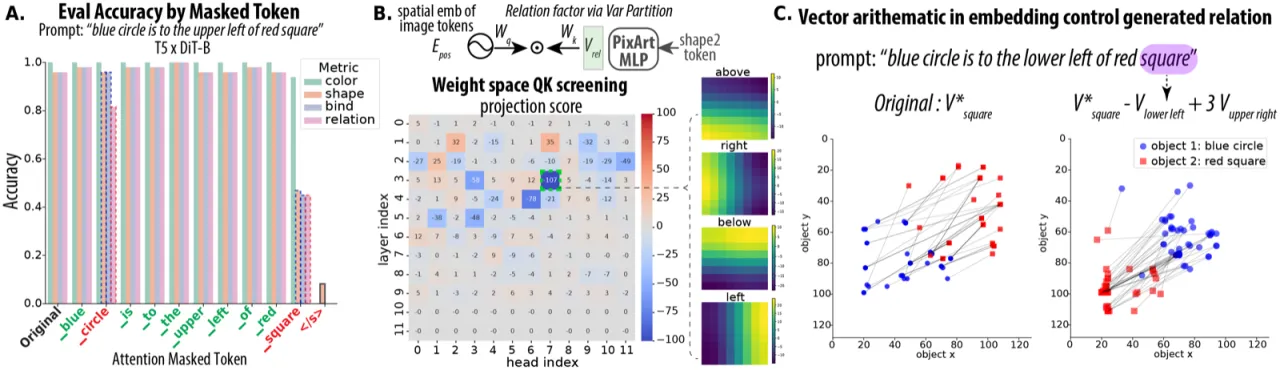
T5-DiT 中的不同机制
图4:T5-DiT 中的向量运算干预实验。
通过从第二个物体的 T5 contextual embedding 中减去原 relation 向量并加入目标 relation 向量,
可以因果性地改变生成物体的空间位置,同时保持形状和颜色不变——证明空间信息融合在 contextual token 中。
在 T5-DiT 中,空间信息并非由独立的 attention head 处理,而是通过 T5 自注意力
将 relation 信息融合进第二个物体 token 的 contextual embedding 中。
方差分解(Variance Partitioning)显示:
DiT MLP 映射前,shape2 解释约 37.5% 的方差,relation 仅占 12% ;
经 DiT MLP 投影后,relation 的贡献上升至 21.3% 。