01 动机 Motivation
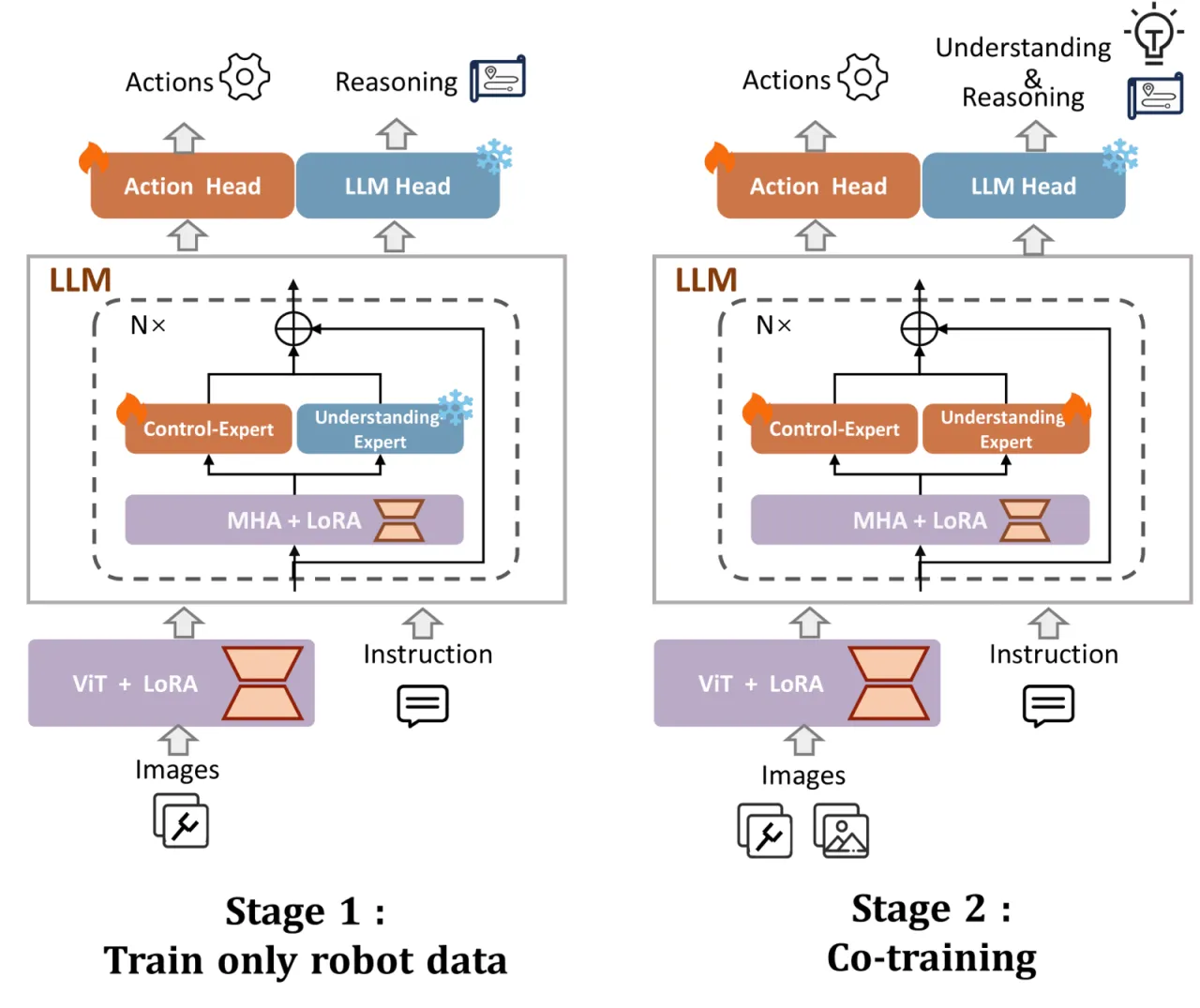
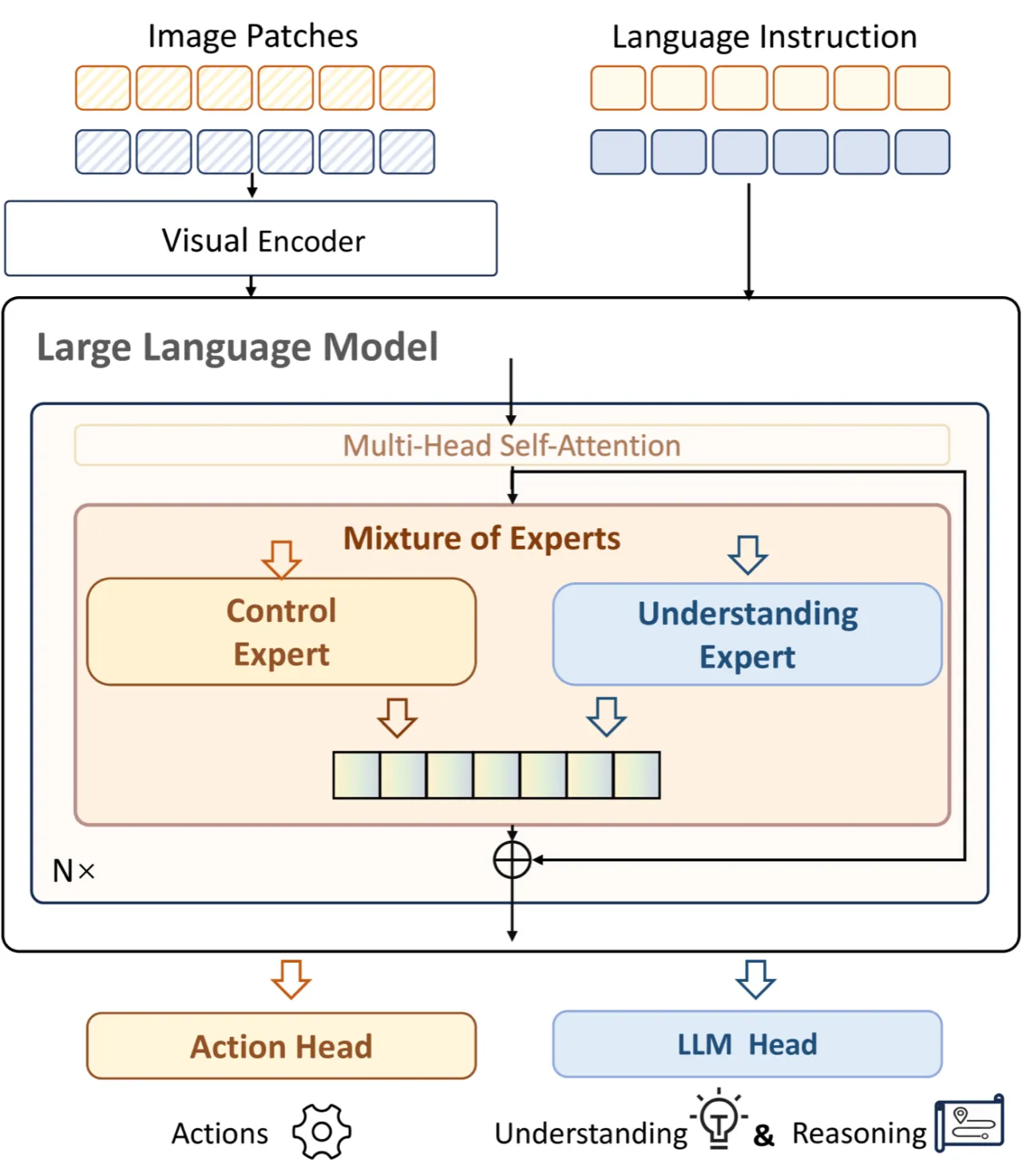
现有 VLA 模型在机器人控制与多模态理解之间存在根本性矛盾:擅长底层操作的架构往往丧失视觉-语言对齐能力,而强大的 VLM 又缺乏物理交互能力。作者通过系统分析训练范式,识别出两大核心挑战。
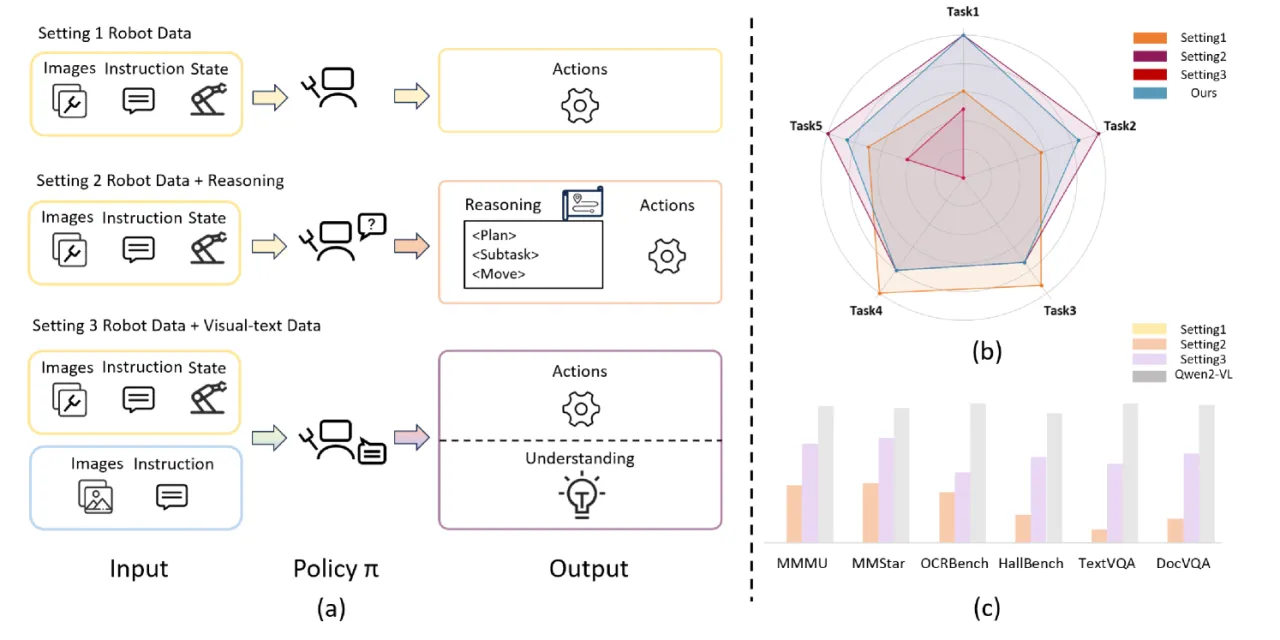
"Through a systematic analysis of existing training paradigms in vision-language-action models (VLA), we identify two key challenges: spurious forgetting, where robot training overwrites crucial visual-text alignments, and task interference, where competing control and understanding tasks degrade performance when trained jointly."
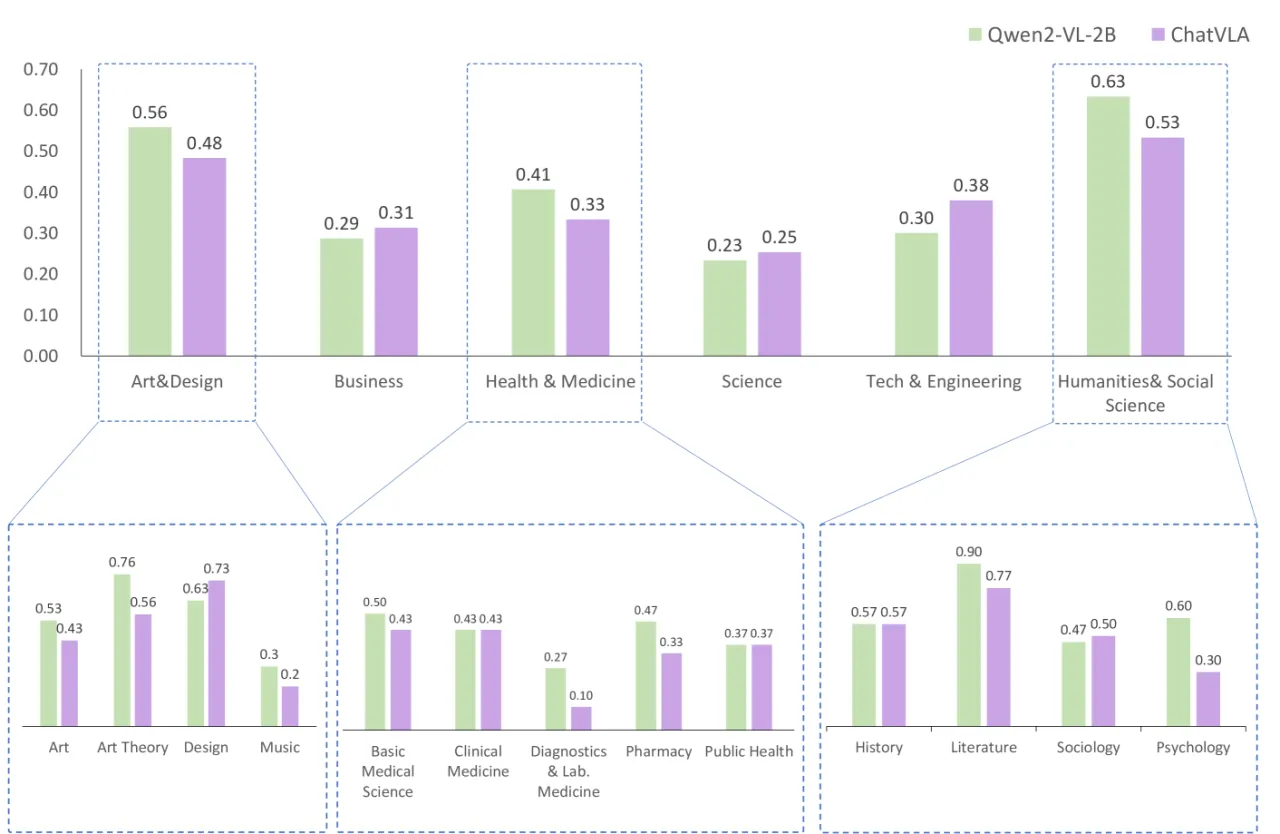
6×在 MMMU 上相比 ECoT 的性能提升(37.4 vs. 5.4)
55/107ChatVLA 跨技能多任务成功次数(OpenVLA 仅 20/107)
1.00Task 3 平均成功长度(满分),Octo 仅 0.11
2B模型参数量,对标 Qwen2-VL-2B 底座
两大核心挑战
Spurious Forgetting(伪遗忘)
机器人数据微调过程中,模型会覆盖预训练阶段习得的视觉-文本对齐能力。即便使用 LoRA 等参数高效方法,这种遗忘现象依然存在,导致 VLA 在多模态理解基准(如 MMMU、TextVQA)上性能几乎归零。
Task Interference(任务干扰)
当控制任务与理解任务同时训练时,二者的梯度方向相互冲突,导致两端性能均出现退化。这与 Dual Coding Theory(双编码理论)的预测一致——不同模态的信息在大脑中由独立通道处理。