02 方法
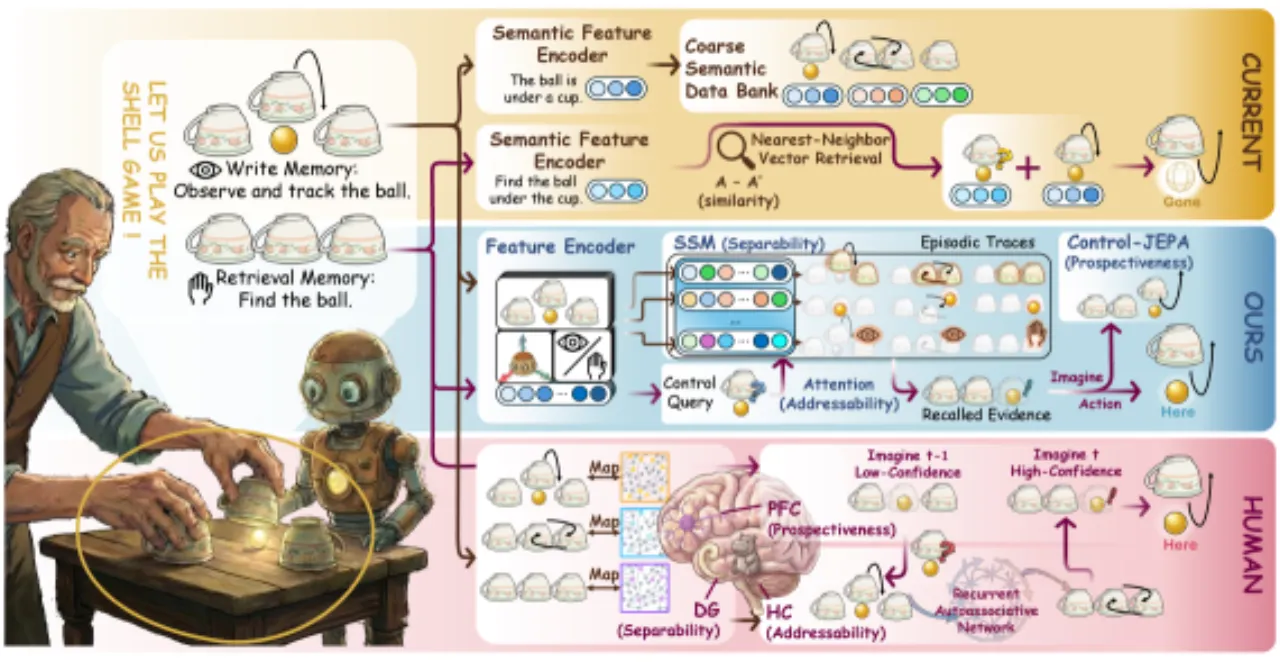
Chameleon 通过四个核心模块实现控制索引前瞻性记忆:①将多模态观测编码为具身事件 token(embodied event tokens);②通过选择性状态空间模型(SSM)进行逐 token 轨迹传播;③以学习到的控制索引进行可寻址检索;④将检索到的历史整合为前瞻性策略状态,驱动整流流(rectified-flow)动作生成头。
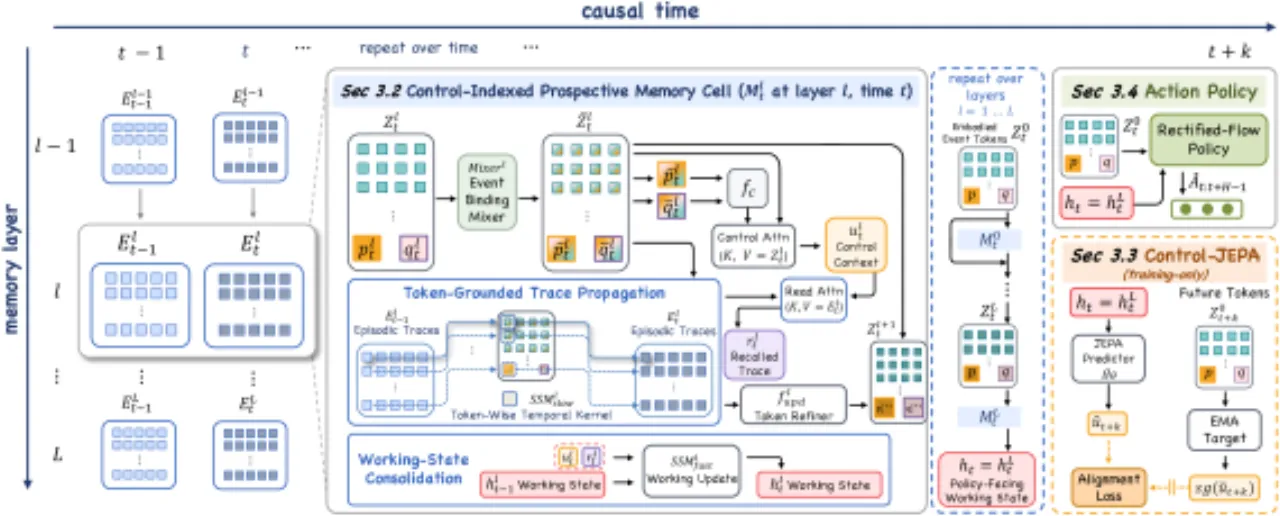 图2:Chameleon 系统总览。
系统按时间步处理多视角图像、本体感知和语言指令,生成具身事件 token,经双层控制索引记忆模块后输出前瞻性策略状态,最终通过整流流策略头生成动作序列。
图2:Chameleon 系统总览。
系统按时间步处理多视角图像、本体感知和语言指令,生成具身事件 token,经双层控制索引记忆模块后输出前瞻性策略状态,最终通过整流流策略头生成动作序列。
① 具身事件 Token 写入
每个时间步 t,系统将来自多摄像头的视觉补丁(经 DP 风格编码器处理)、本体感知(robot state)以及语言指令(经冻结 DistilBERT 编码)拼接为具身事件 token:
Zt⁰ = Concat[Xt¹, ..., Xtᵛ, Prop, Lang]。
每类 token 保持独立,为后续分离性存储奠定基础。
② 逐 Token 轨迹传播(Separability)
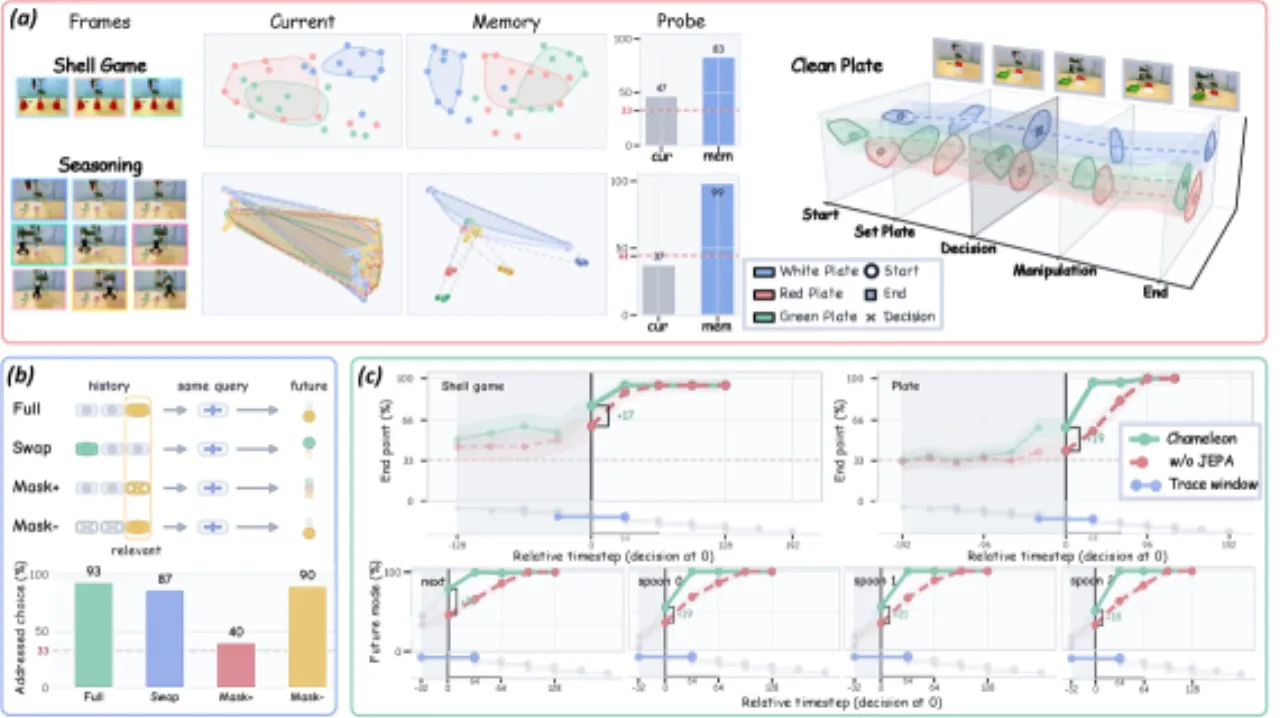
使用选择性状态空间模型(SSM)在时间维度上独立传播每条 token 流的轨迹,而非将所有历史压缩为单一递归向量。这确保视觉、本体感知等不同来源的历史各自保持独立表示,实现可分离性。事件绑定步骤(Event Binding)通过自注意力混合器让各类 token 先相互交互,使写入的事件已包含任务与身体的条件化信息。
③ 控制索引与可寻址检索(Addressability)
模型从本体感知与语言中构建学习到的控制索引(control index),再通过对当前场景证据的注意力加以精化,形成控制上下文(control context)。该上下文以注意力方式查询逐 token 历史轨迹,检索与当前决策相关的历史,实现可寻址性。检索到的轨迹合并为"快"工作状态(fast working state),与"慢"情节级记忆(slow episode-level memory)分离。
④ Control-JEPA 前瞻性训练(Prospectiveness)
区别于重建过去图像或状态的训练目标,Control-JEPA 让当前工作状态预测未来的控制上下文:
ûₜ₊ₖ = gθ([hₜ, ηₖ])
目标为后续策略步真实使用的控制上下文,使记忆具有前瞻性和"动作就绪"特性。训练损失采用 smooth-L1 对齐(带 stop-gradient 目标)与跨多个预测视野 {1, 2, 4, 8, 16, 32} 的方差正则化。动作生成头使用整流流(rectified-flow),以无噪初始化 Aτ = (1−τ)A₀ + τA* 进行训练。
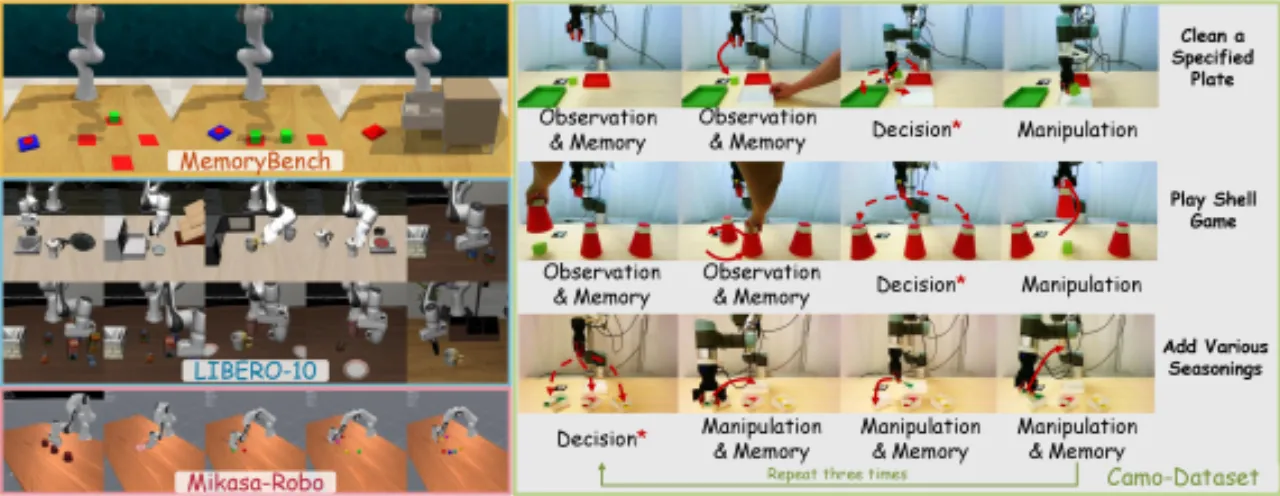
 图5(补充):真实机器人实验平台。
6自由度 UR5 机械臂,配备自适应夹爪与 22 个标注摄像头视角,用于 Camo-Dataset 数据采集。
图5(补充):真实机器人实验平台。
6自由度 UR5 机械臂,配备自适应夹爪与 22 个标注摄像头视角,用于 Camo-Dataset 数据采集。