01 动机
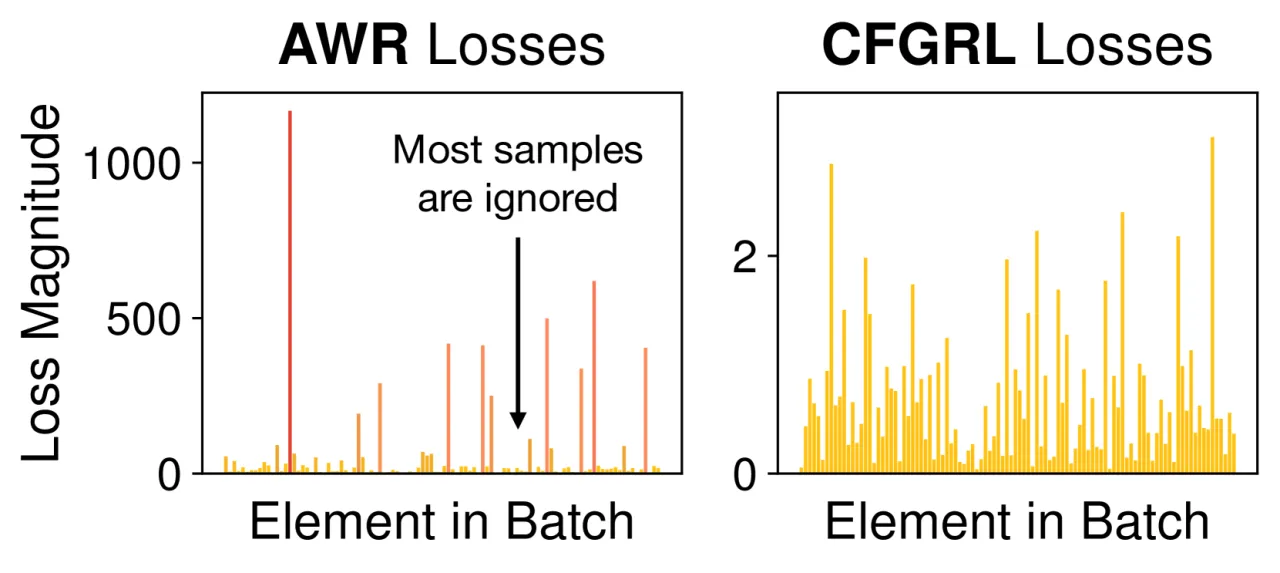
离线强化学习(offline RL)的核心挑战是:如何在不超出数据支撑的情况下,从固定数据集中提取比行为策略更优的策略? 现有方法(如 Advantage-Weighted Regression / AWR)通过对数据样本赋予奖励权重来进行策略提升, 但这会造成梯度幅度在 batch 内严重不均衡——大量低优势样本几乎不贡献梯度,学习效率低下。
"We derive a direct relation between policy improvement and guidance of diffusion models, and show that CFGRL is trained with the simplicity of supervised learning, yet can further improve on the policies in the data."
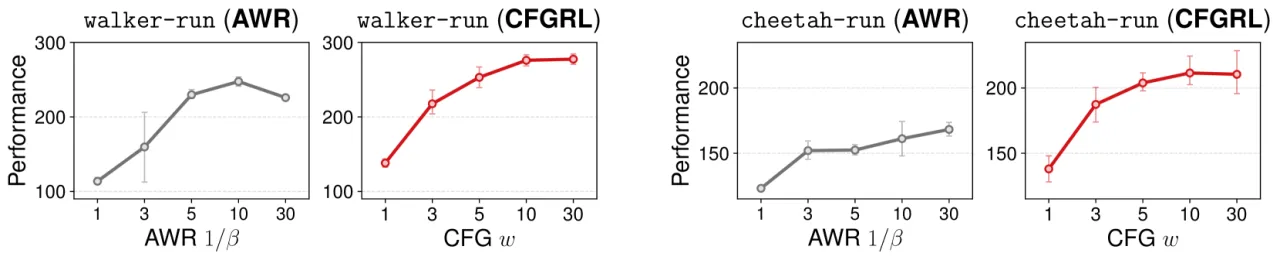
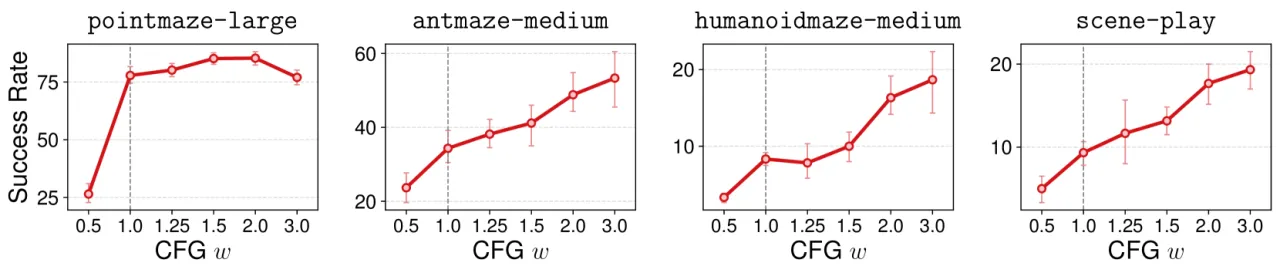
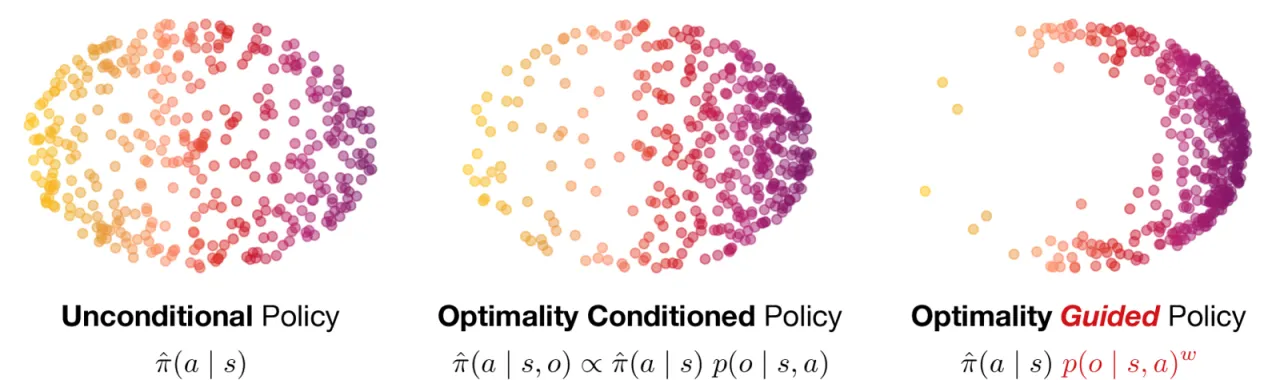
本文的洞察:扩散模型中的 classifier-free guidance(CFG)天然对应着策略改进算子。 条件分支学习"最优行为",无条件分支学习"参考行为",两者的分数函数之差正是优势函数(advantage) 对策略的梯度方向。推理时放大引导权重 w,等价于对最优性进行更强的"衰减(attenuation)", 从而单调地提升期望回报。
+30%walker-stand 相对 AWR 提升
(782 vs 603)
(782 vs 603)
+29%walker-walk 相对 AWR 提升
(608 vs 444)
(608 vs 444)
15×pointmaze-giant CFGRL vs GCBC
(30 vs 2)
(30 vs 2)
37×visual-cube-single CFGRL vs GCBC
(37 vs 1)
(37 vs 1)