01 动机 Motivation
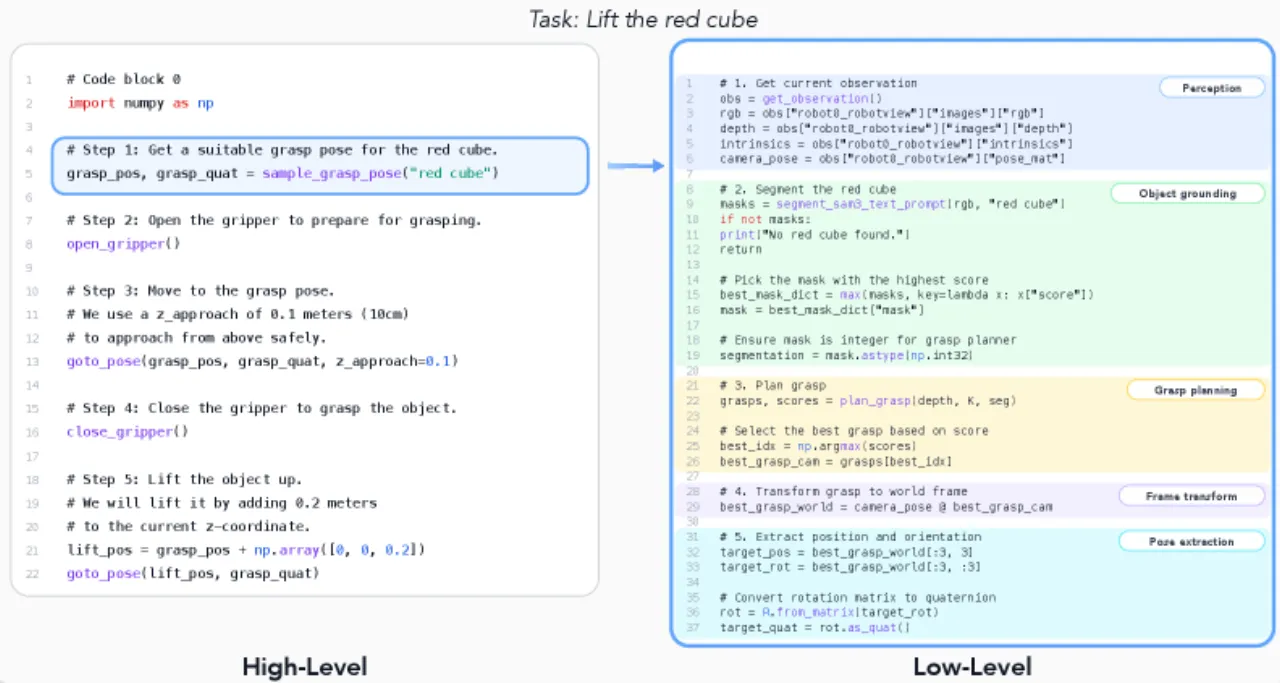
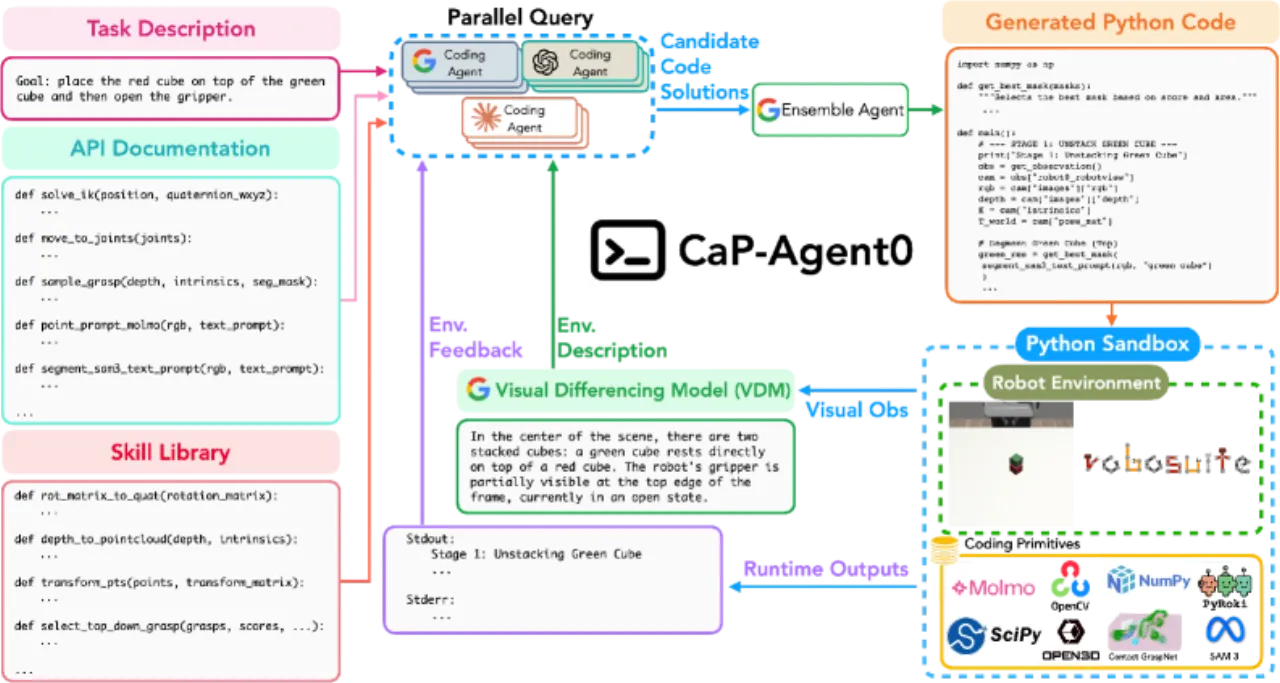
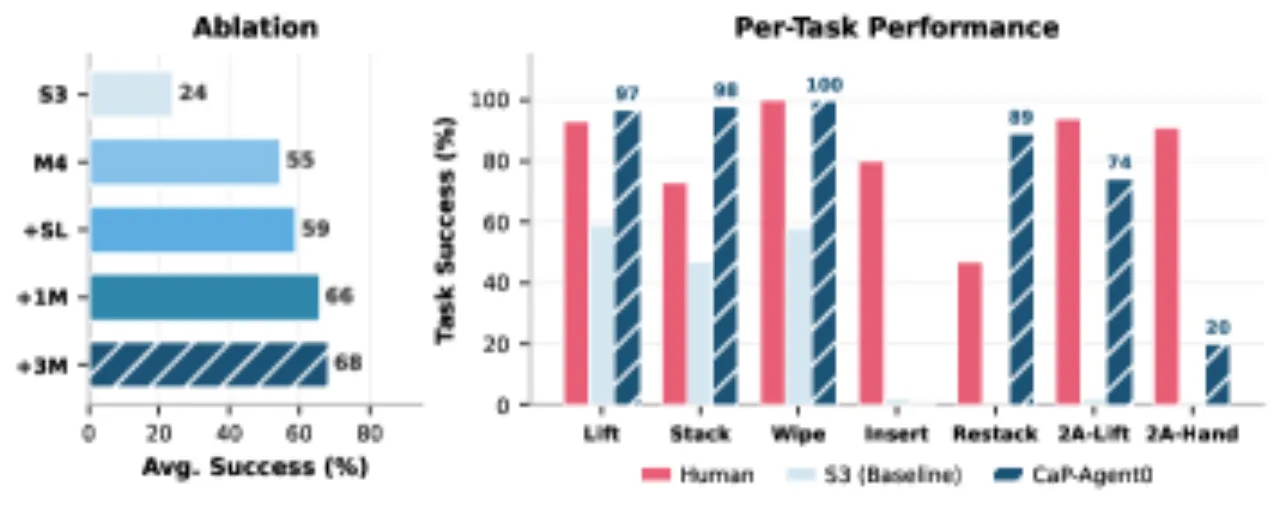
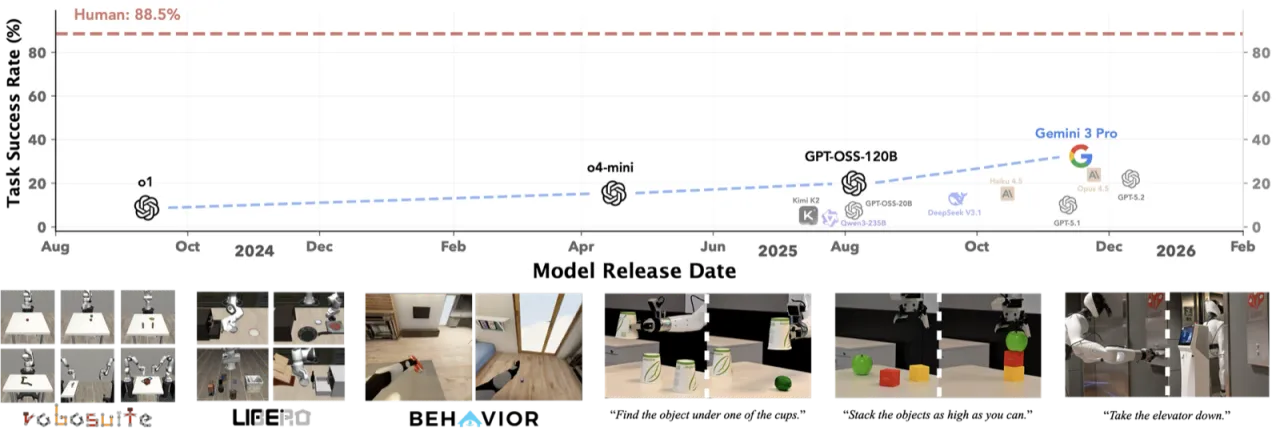
「代码即策略」(Code-as-Policy)被视为数据密集型 VLA 方法的有力补充,但其作为自主控制器在 embodied manipulation 场景中的有效性仍严重缺乏系统性研究。现有工作大多依赖高层原语(如 stack_objs_in_order()),使得模型性能究竟来自智能体本身还是原语封装的任务先验难以区分,且未回答:当抽象层级降低时性能如何变化?增加测试时计算量是否能弥补低层接口带来的挑战?
"Code-as-Policy considers how executable code can complement data-intensive Vision-Language-Action (VLA) methods, yet their effectiveness as autonomous controllers for embodied manipulation remains underexplored."
12前沿模型(开源+闭源)
7操控任务(单臂+双臂+移动)
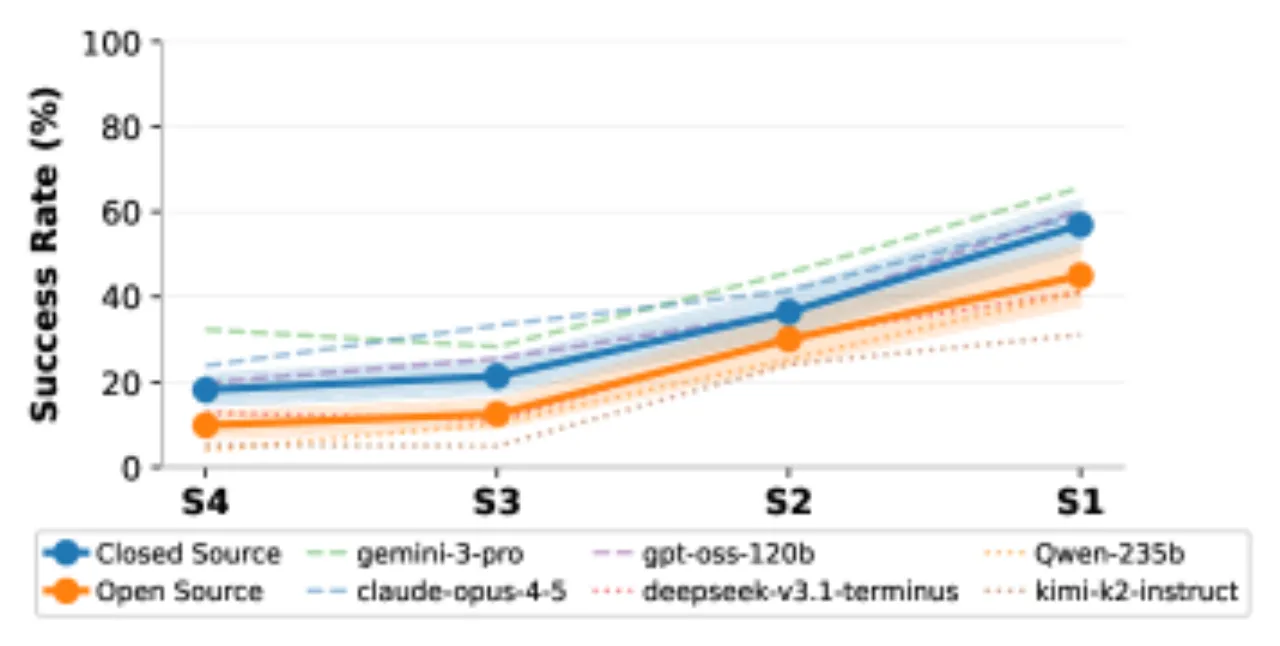
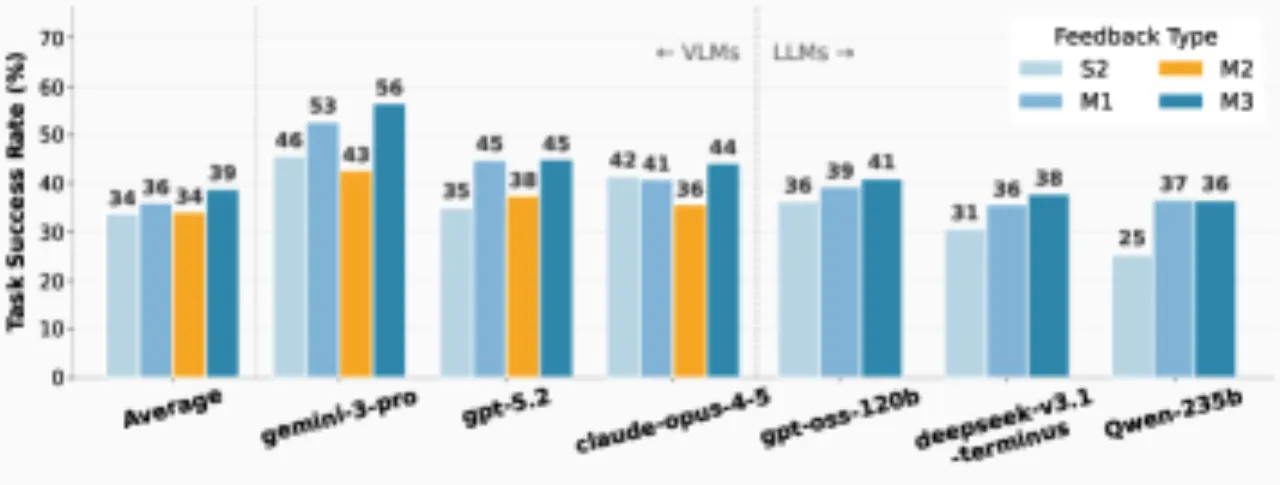
8评测层级(S1-S4, M1-M4)
4/7CaP-Agent0 达到或超越人类水平的任务数