01 动机
现有视觉-语言任务数据集在序列长度、动作空间复杂度和语言多样性方面均存在明显不足, 难以训练出能够在日常真实环境中与人类协作的通用机器人。如何让机器人在仅凭语言指令的条件下, 自主完成由多个子技能组合而成的长序列操控任务,是迈向通用机器人的关键挑战。
"General-purpose robots coexisting with humans in their environment must learn to relate human language to their perceptions and actions to be useful in a range of daily tasks. Moreover, they need to acquire a diverse repertoire of general-purpose skills that allow composing long-horizon tasks by following unconstrained language instructions."

34操控任务类别
7-DOF连续动作空间
400+人工采集自然语言标注
4→1训练环境 → 零样本测试环境
为什么现有基准不够用?
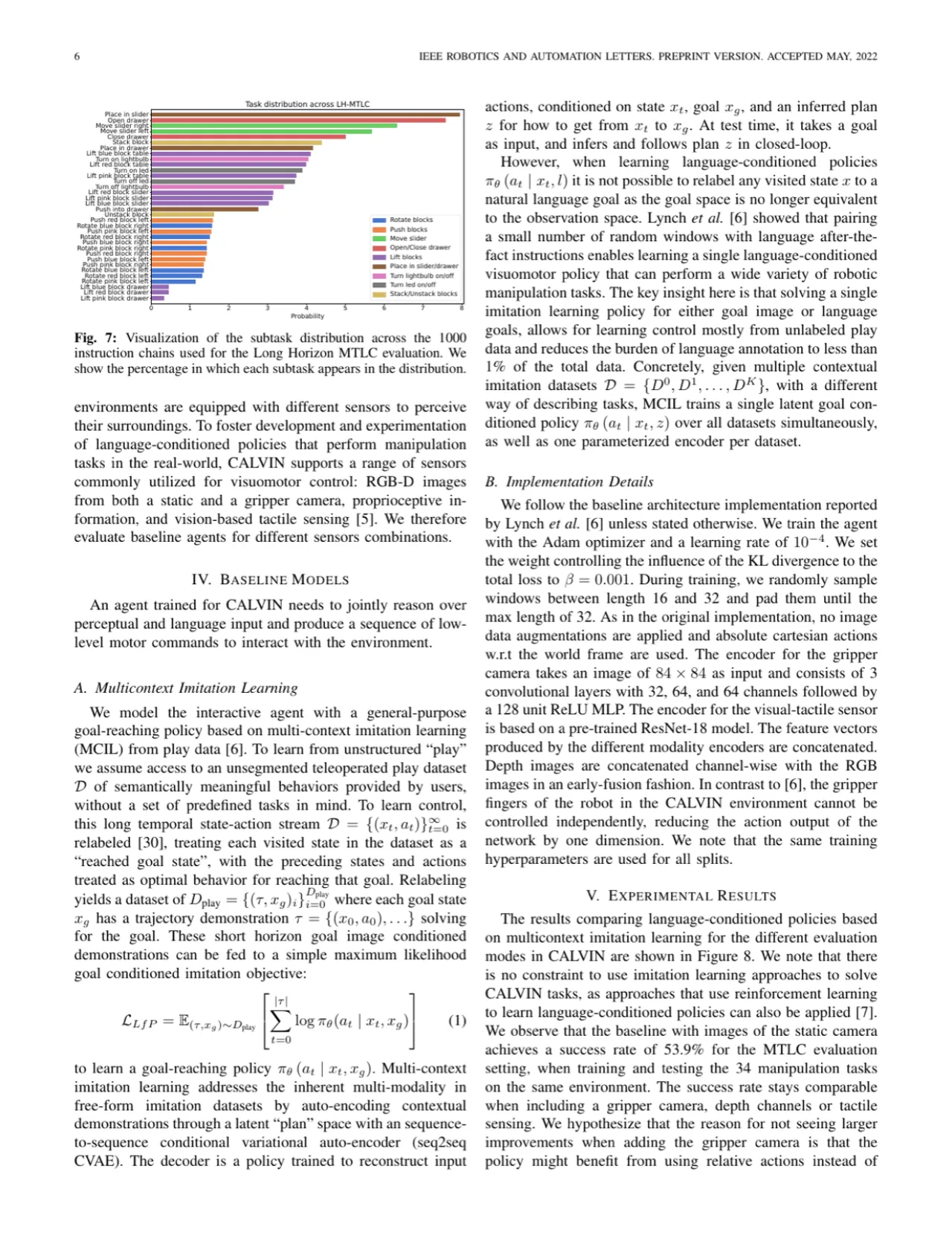
- 序列长度受限:现有数据集通常只评估单步或短序列任务,无法衡量智能体对多技能组合的掌握程度。
- 语言多样性不足:现有数据集多依赖模板化语言标注,而 CALVIN 收集超过 400 条众包自然语言指令, 对应 34 种精细操控任务,并提供超过 30,522 个词汇量的语料库(平均句长 7.98 词)。
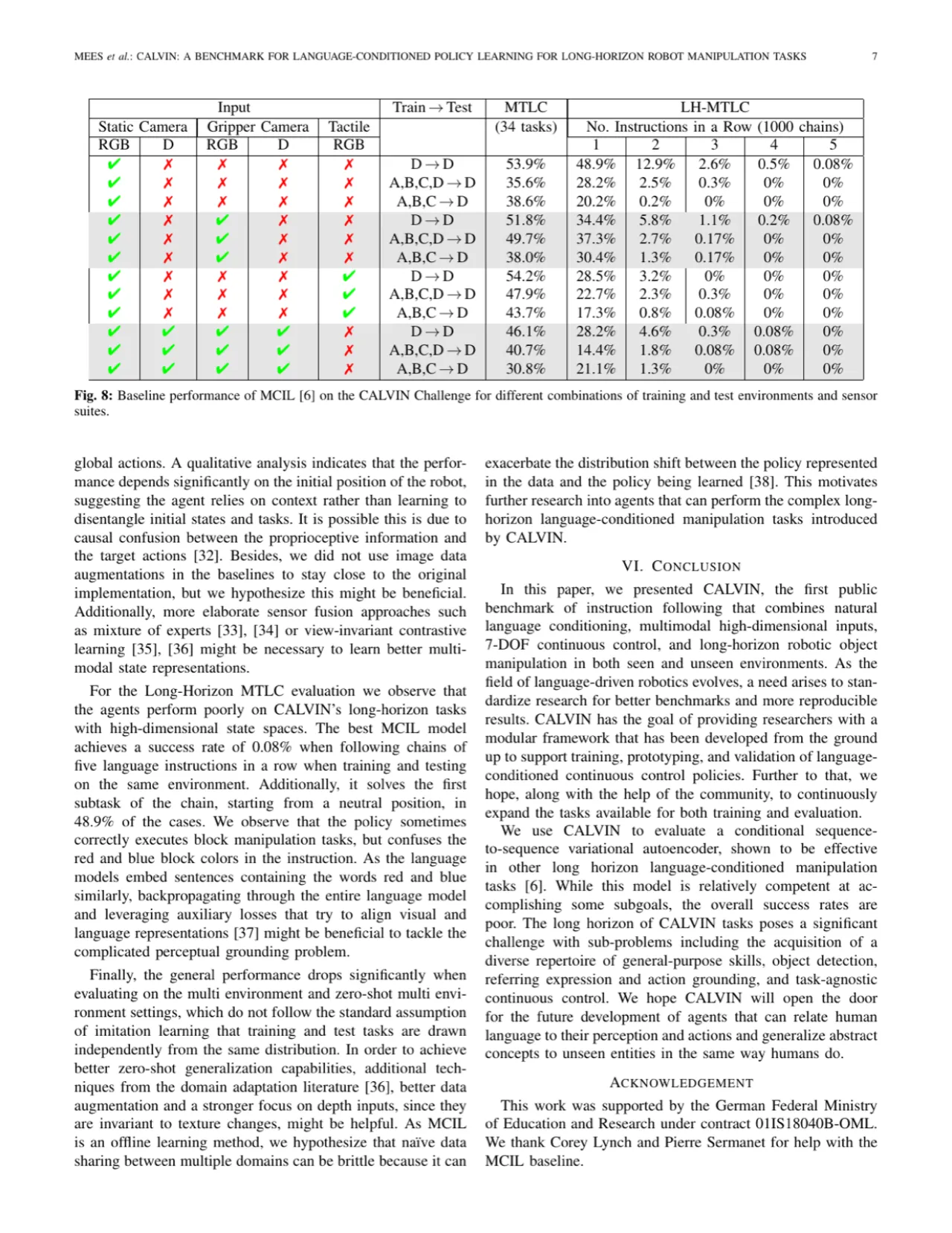
- 泛化评估缺失:既有方法很少在全新环境和对象上进行零样本评估,CALVIN 将跨环境零样本泛化作为核心评估轴。
- 传感器灵活性差:CALVIN 支持 RGB-D 图像、本体感知、视觉触觉等多种传感器组合,便于研究多模态感知对策略的影响。