01 动机
现有机器人视觉编码器面临双重困境:一方面,机器人轨迹数据规模远不及互联网图文数据;另一方面,用图文对比(CLIP/SigLIP)或掩码自编码(MAE/DINOv2)预训练的编码器虽捕获语义或空间结构,却从未接触过配对的视觉-动作信号,因此在策略学习中产生根本性的表示错位。
"robot trajectories, the most direct source of this paired signal, are not available at pre-training scale, motivating us to extract action signals from abundant human video instead."
CAIP 的核心洞察:人类手部姿态(3D 关键点)在形式上类似于机器人末端执行器轨迹,可以从海量第一视角视频中廉价获取,从而弥合人类示范与稀缺机器人数据之间的鸿沟。
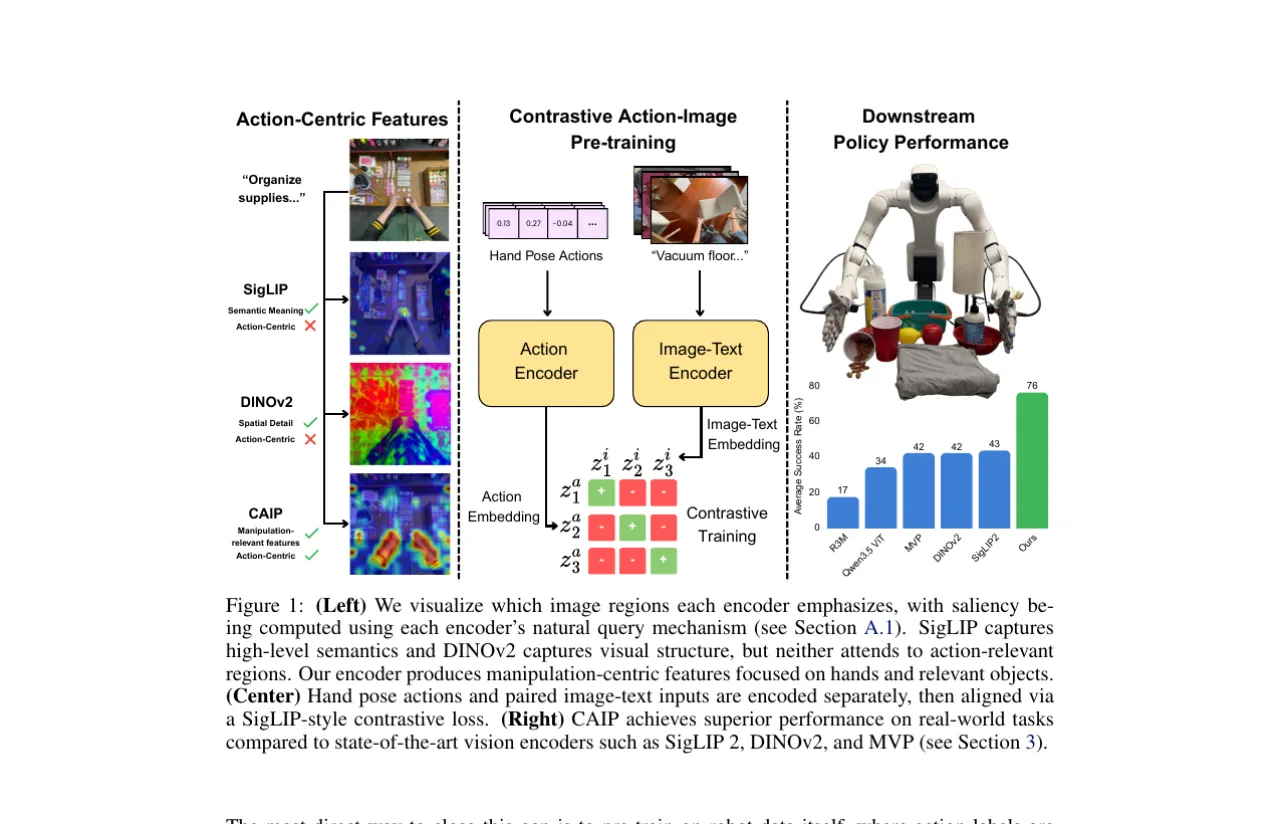
76%CAIP 平均成功率
43.4%最强基线 SigLIP 2
>30pp超越最强基线的提升幅度
32,041 h自我中心预训练视频


