01 动机 (Motivation)
扩散模型(diffusion models)在图像生成领域取得了令人瞩目的成就,但其生成过程并不总是可靠:即使是同一个模型,也会产生质量参差不齐的样本,包括语义混乱、artifact 明显或与文本 prompt 不符的图像。现有评估指标(如 FID、Inception Score)只能衡量整体分布质量,无法针对单张图像做出判断,这使得低质量图像的识别与过滤几乎无从下手。
"Bayesian uncertainty has long been used to identify data far from the manifold of training samples — the posterior delivers low uncertainty for training-like data and high uncertainty for others."
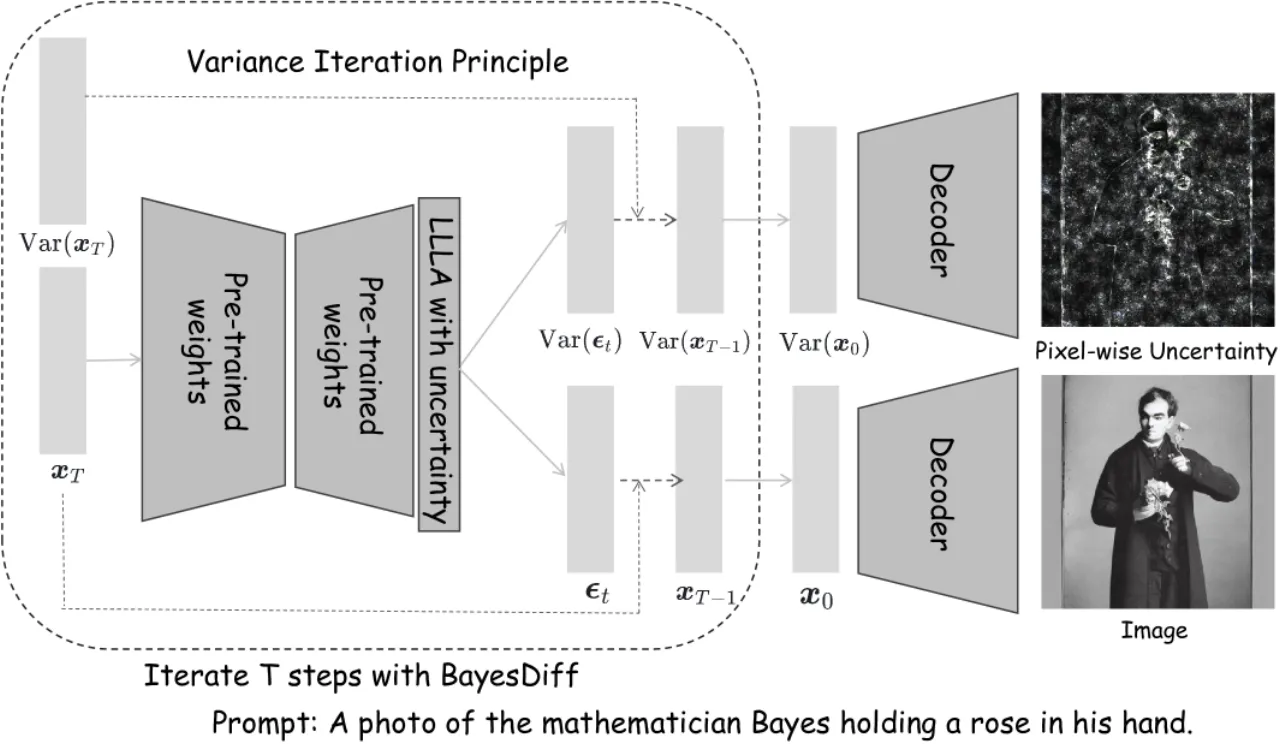
作者将 Bayesian uncertainty 的这一特性迁移到扩散模型的生成过程中:如果一张生成图像的像素分布偏离训练数据的流形,则该像素对应的不确定性应当更高。基于这一直觉,BayesDiff 建立了一套从 Bayesian inference 出发、跟踪整个反向扩散链(reverse diffusion chain)中不确定性传播的理论框架。
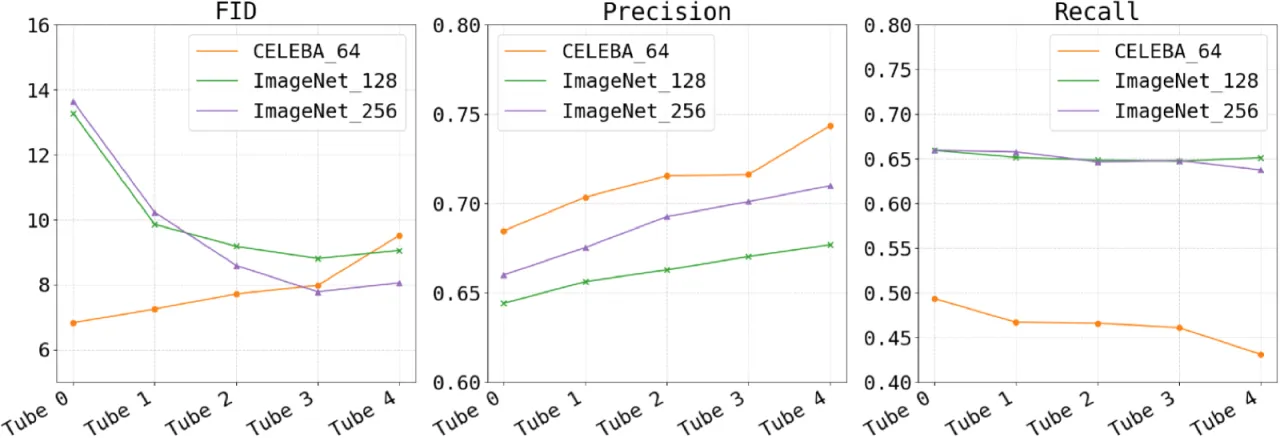
FID ↓U-ViT ImageNet 256: 7.24 → 6.81(过滤后)
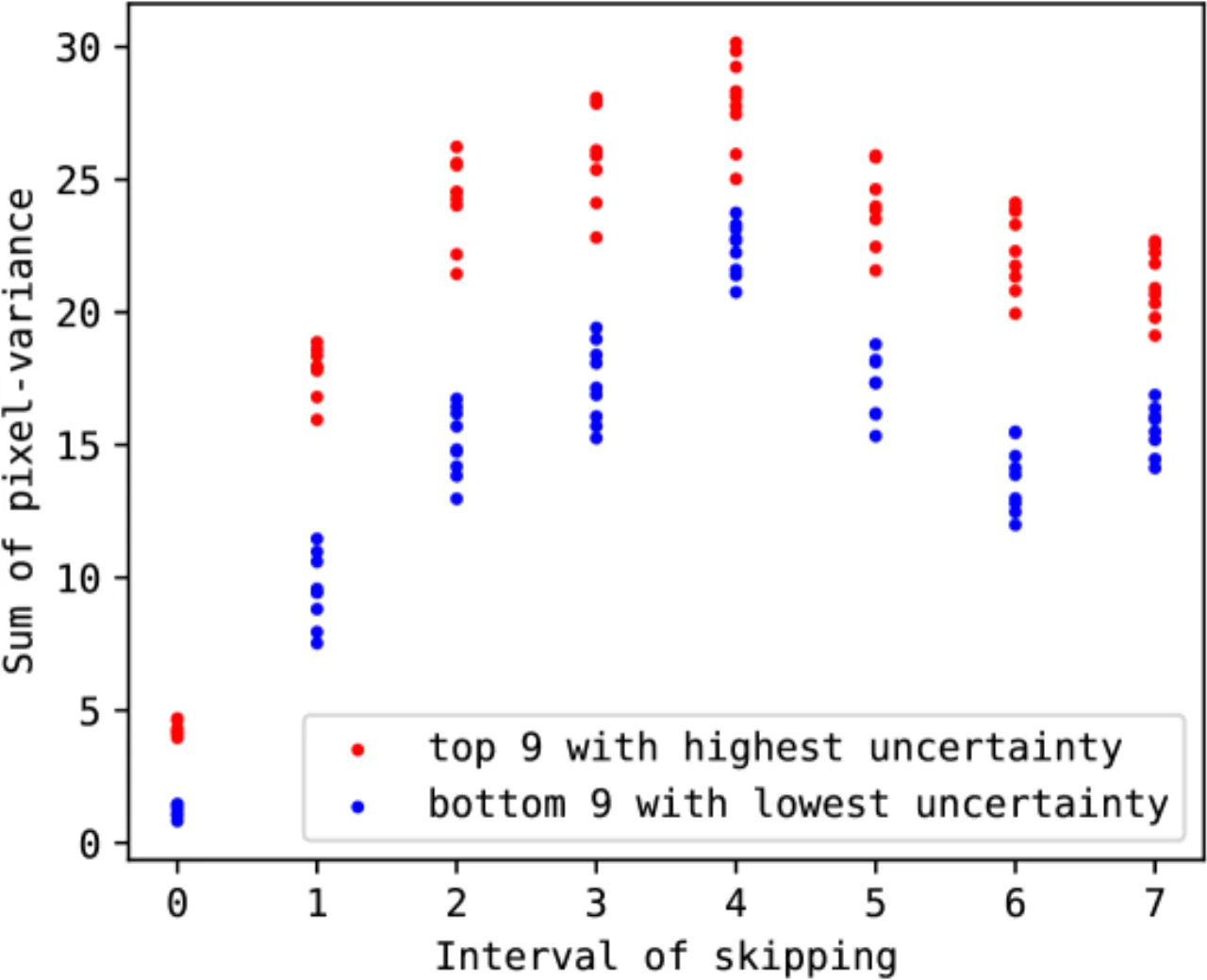
5×BayesDiff-Skip 加速比,保持排序一致性
Precision ↑ADM ImageNet 128: 0.661 → 0.665(过滤 top 16%)
Pixel-wise不确定性集中于语义关键区域(眼睛、轮廓等)