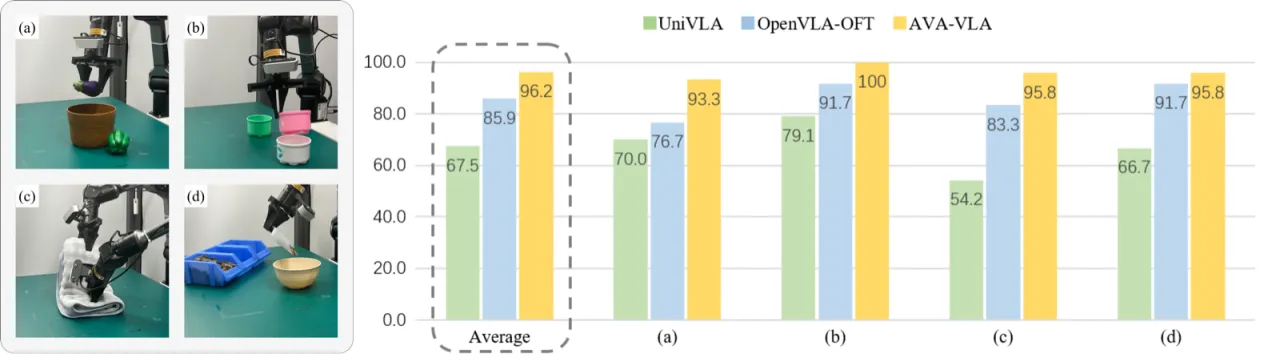
02 方法
AVA-VLA 将 VLA 策略重新表述为 POMDP:动作生成不仅依赖当前观测,
还依赖对任务历史信念的循环近似状态。
核心模块是 Active Visual Attention(AVA),
它将循环状态与语言条件化视觉特征融合,
生成 soft importance scores 对骨干 LLM 中所有层的视觉 token 注意力矩阵进行调制。
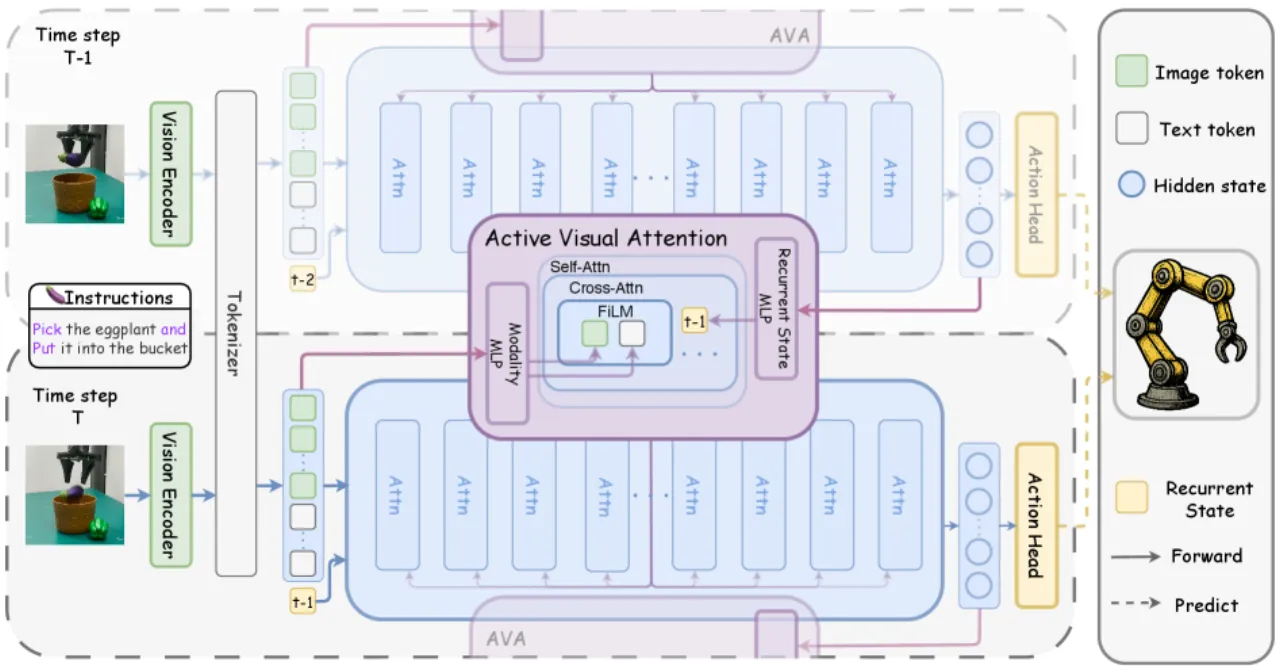
图 2:AVA-VLA 整体架构。
循环状态 rt-1 由上一时间步动作相关隐藏状态经 MLP 模块 ℬ 压缩而来。
AVA 模块将循环状态与文本条件化视觉特征融合,输出 soft 权重向量 ωt ,
对骨干 LLM 所有层的视觉 token 注意力矩阵进行调制。
推理时完全循环(fully recurrent),每次前向传播同时预测动作块并提取下一步循环状态。
POMDP 重表述与循环状态
将策略形式化为:Āt ~ Pθ (At | xt , bt-1 ) ,
其中 bt-1 捕获"all relevant historical context, including observations and actions"。
由于理论信念状态难以精确计算,方法学习一个压缩的循环表示 rt-1 ,
作为"a neural approximation",从上一时间步动作相关的 LLM 隐藏状态提取,通过 MLP 模块 ℬ 投影。
Active Visual Attention(AVA)模块
AVA 模块依次执行以下操作:
特征编码: 视觉与指令特征各自通过模态专用 MLP 压缩到低维空间 d' < d。FiLM 条件化: 将语言指令通过 Feature-wise Linear Modulation 条件化到视觉特征上。Cross-Attention: 以语言条件化的视觉 token 为 query、循环状态为 key/value,计算跨模态注意力。Self-Attention: 进一步精炼 cross-attention 输出。Importance Scoring: 经 FFN 和带 Softmax 的线性层,预测每个视觉 token 的"logits for enhancing or weakening"。动态注意力调制: 软权重 ωt 作用于 LLM 所有层,修改注意力矩阵:
A'tm ij = exp(Ctm ij ) · Uij / Σl exp(Ctm il ) · Uil 。
训练策略
采用截断反向传播(truncated BPTT) ,时间窗口 T=4,平衡计算可行性与时序动态学习。
同时引入 L2 正则化损失 ℒω t,n = ‖μ(ωt,n ) − c‖ ,
约束注意力权重均值接近目标常数 c,使模型"focus on task-relevant regions while suppressing distracting background responses"。
超参数:LIBERO 中 λ=1.0, c=0.6, γ=[1.9, 0.1];CALVIN 中 c=0.2。
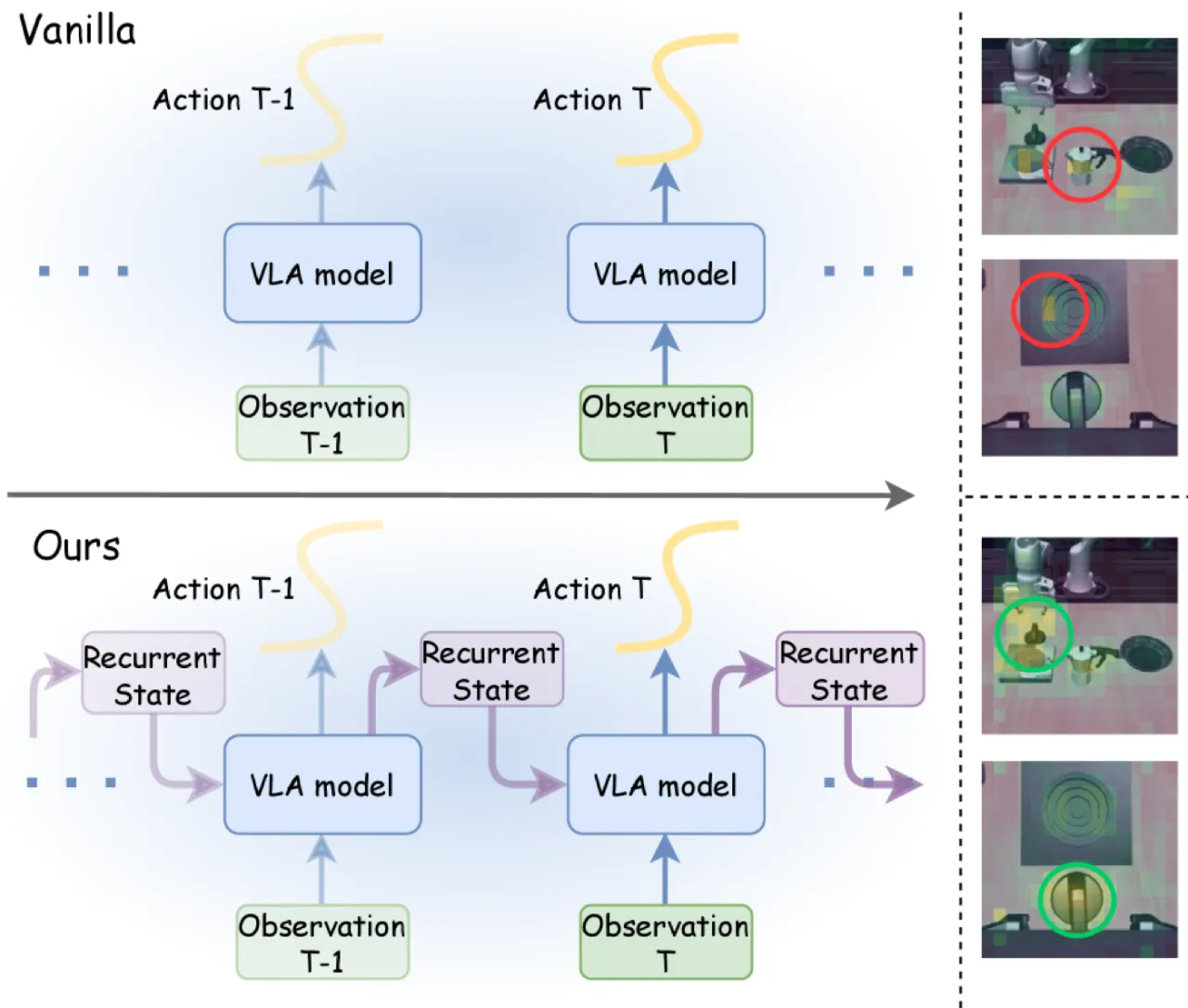
图 3:LIBERO 注意力动态可视化。
任务"put both moka pots on the stove",两路视角下 soft 权重随时间步的演化。
可以看到注意力权重逐步集中到机械臂接触区域和目标物体上,体现了 AVA 模块的主动聚焦能力。