01 动机 Motivation
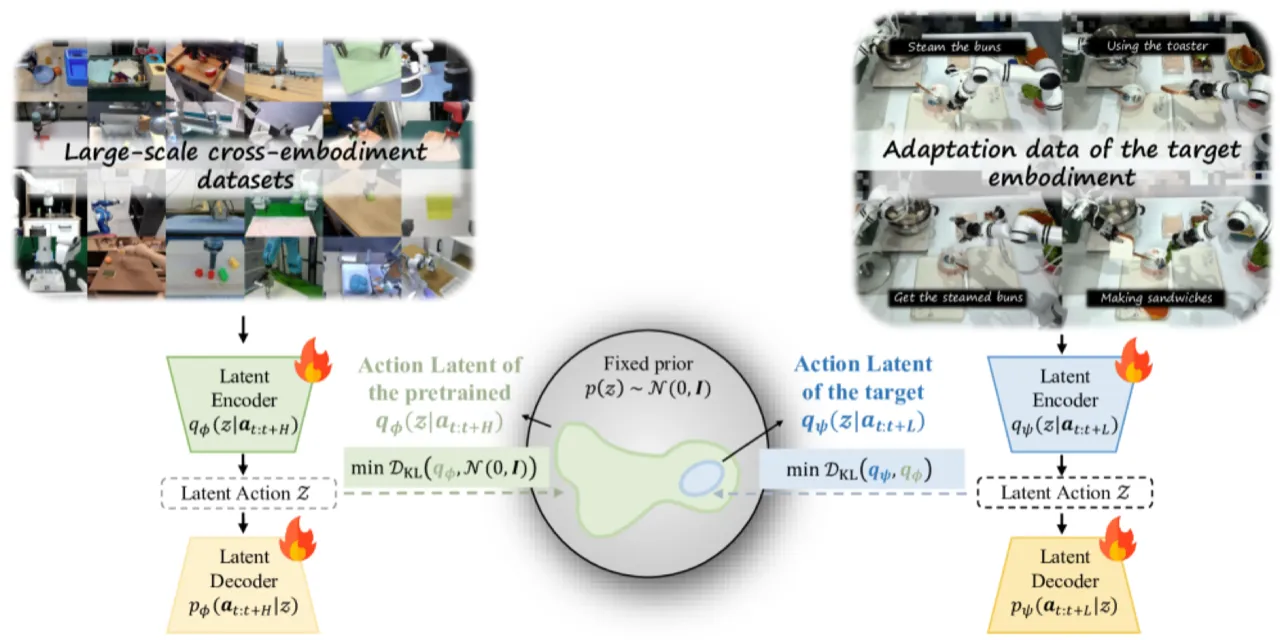
大规模预训练的 Vision-Language-Action(VLA)模型在通用机器人控制上展现出巨大潜力,但将其适配到新机器人平台或新任务时面临两大核心挑战:动作空间异构(不同机器人的 DoF、动作量纲、频率均不同)与数据稀缺(现实中目标任务数据往往只有数十条轨迹)。直接在目标任务上 fine-tune 往往导致灾难性遗忘,丢失预训练阶段习得的视觉-运动先验。
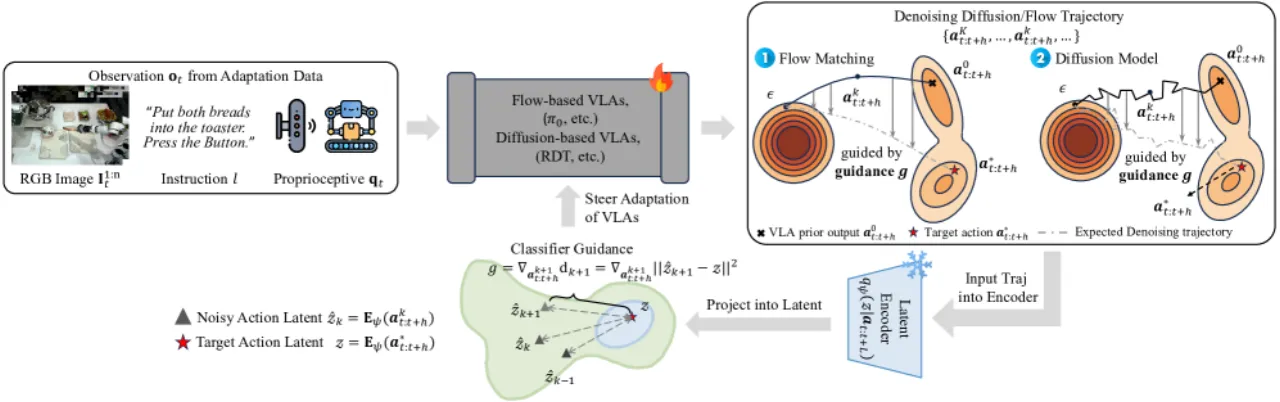
"Unlike prior methods that directly fine-tune VLAs, ATE aligns disparate action spaces into a unified latent representation and steers the VLA's generation via guidance, enabling data-efficient cross-task and cross-embodiment adaptation."
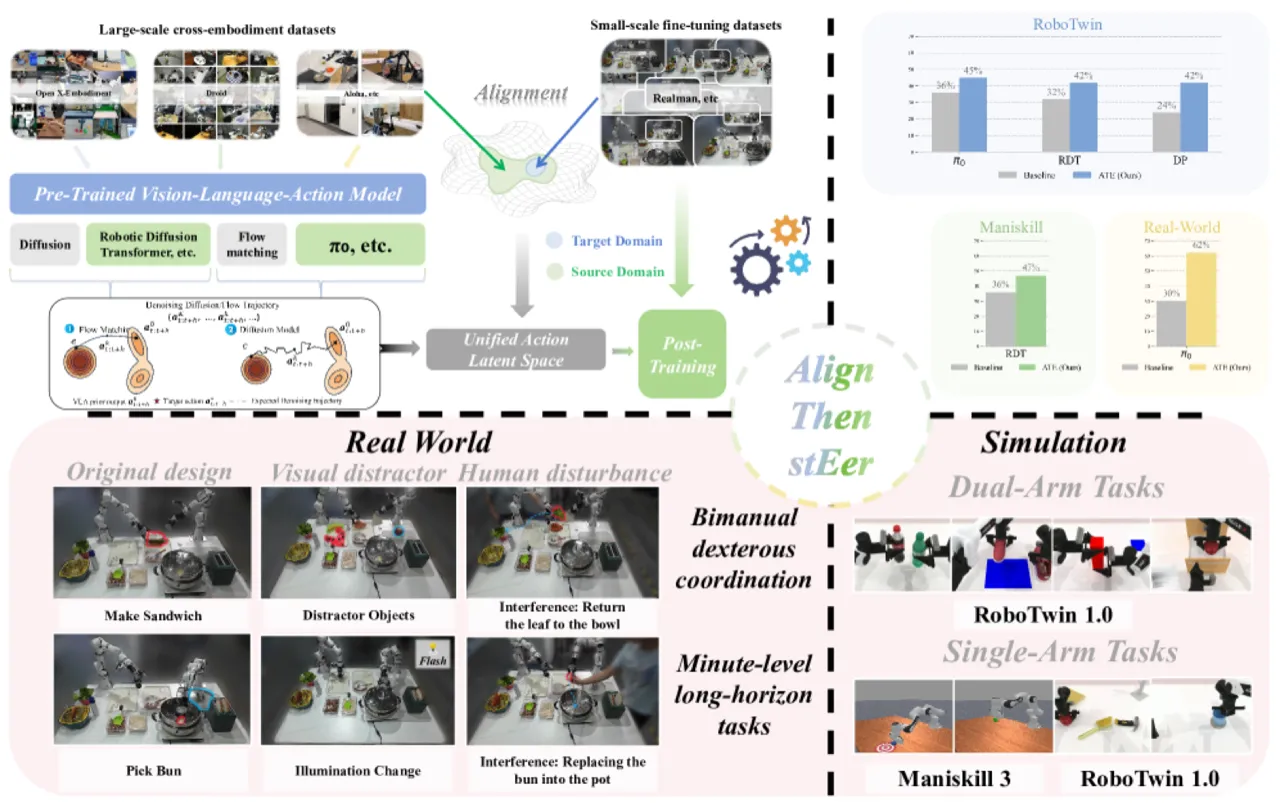
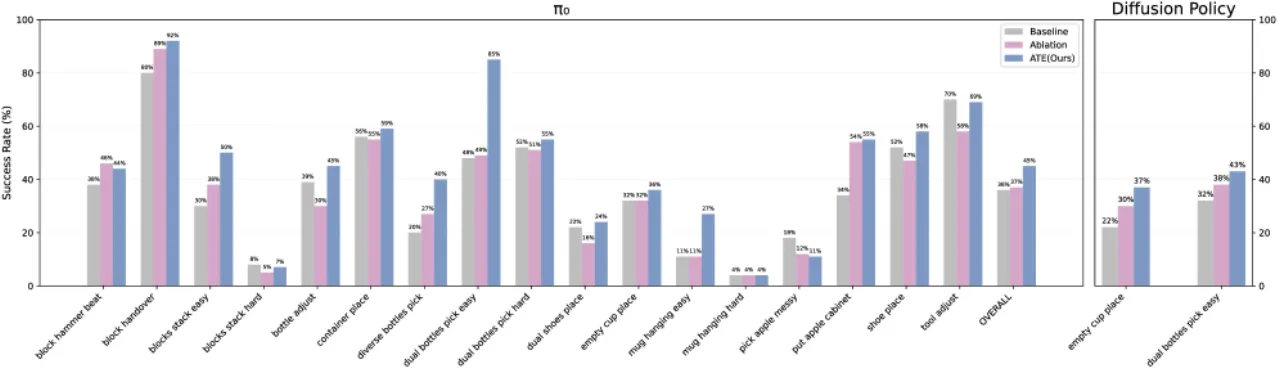
+9.8%RoboTwin 1.0 平均成功率(RDT-1B backbone)
+8.7%RoboTwin 1.0 平均成功率(π₀ backbone)
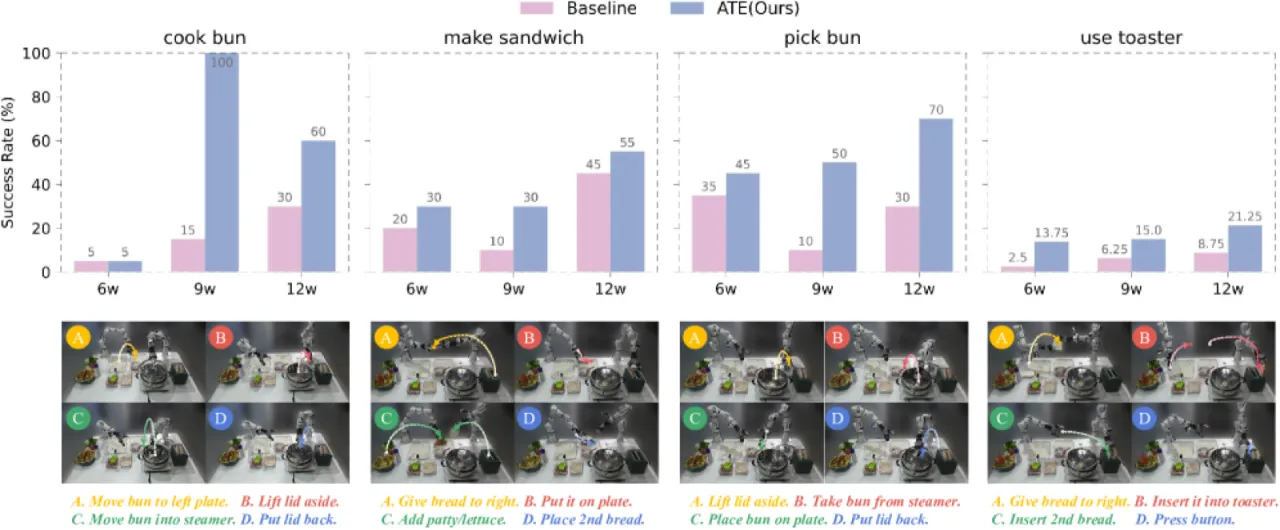
+32%真实跨机器人场景(π₀,120k steps)
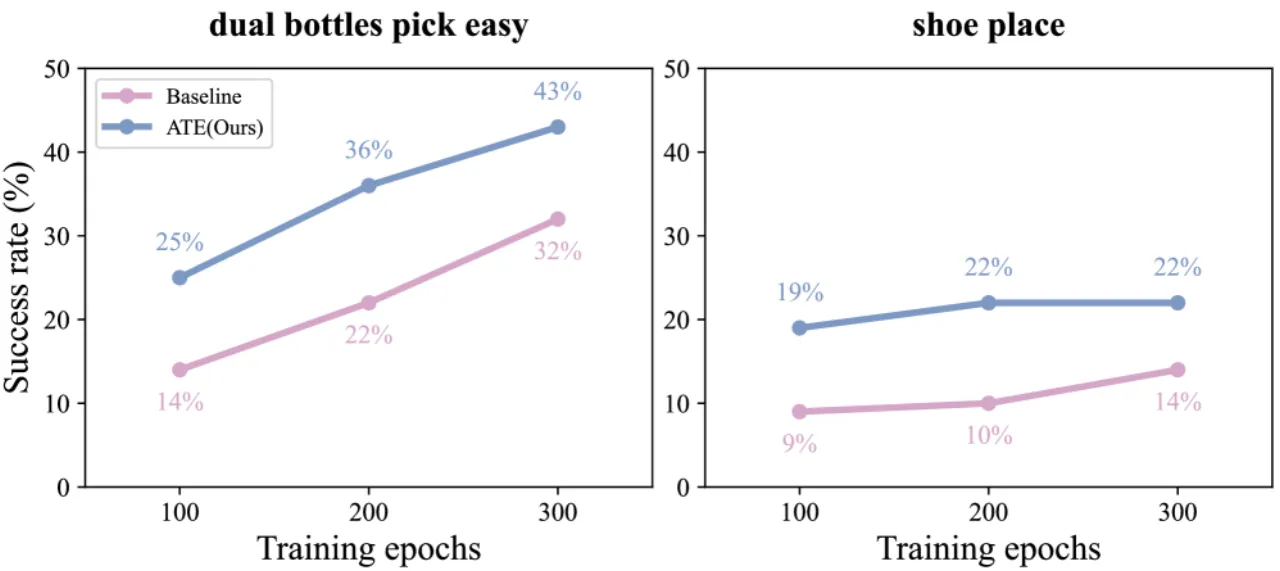
+10.2%ManiSkill3 平均成功率(RDT-1B backbone)