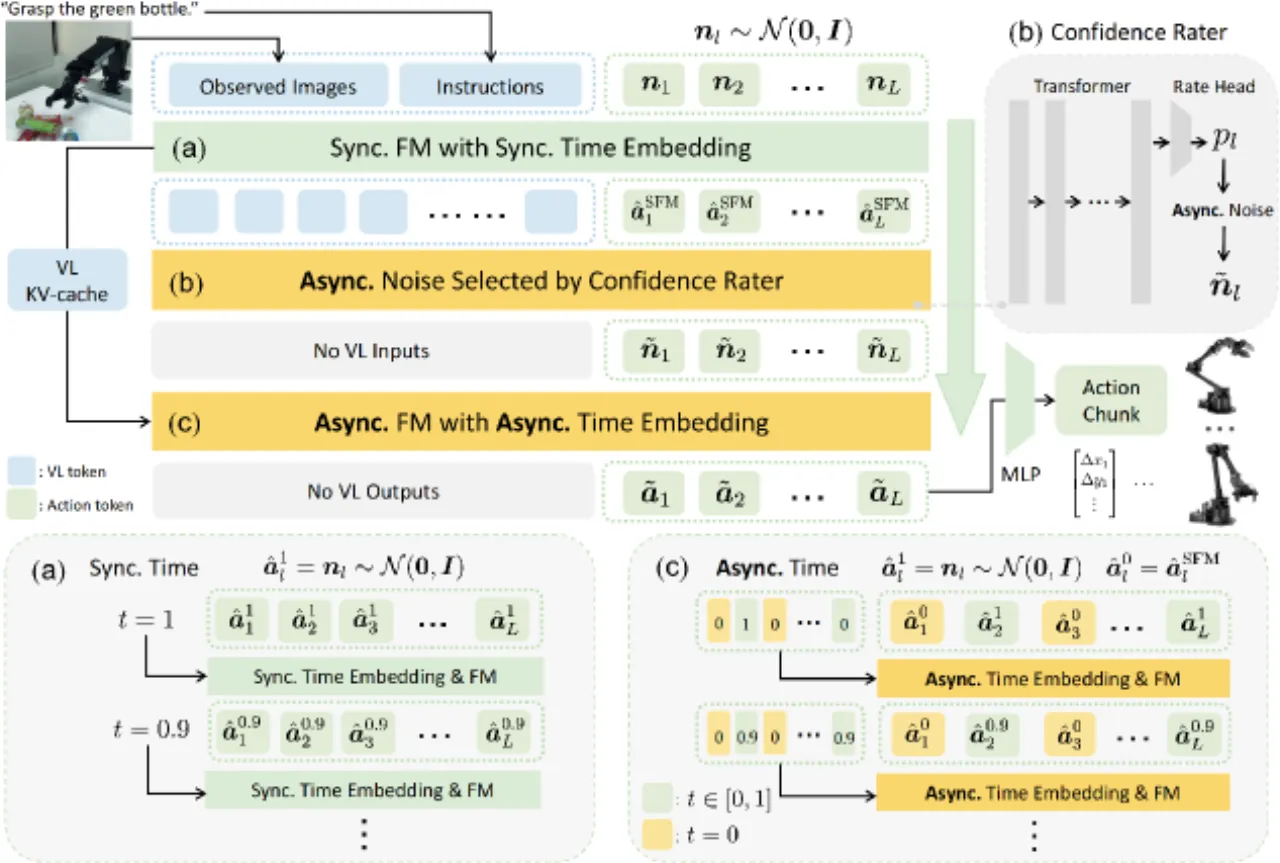
02 方法AsyncVLA 采用两阶段推理:第一阶段,同步流匹配(SFM)从纯高斯噪声出发,经 10 步 Euler 积分生成初步动作序列;第二阶段,置信度评估器(Confidence Rater)对每个 token 打分,将低置信 token 重置为高斯噪声后,异步流匹配(AFM)仅对这部分 token 再次去噪,高置信 token 保持不变以提供上下文约束。整个框架使用单个统一模型,SFM 与 AFM 共享参数。
图 2:AsyncVLA 在 LIBERO-Long 任务上的自校正能力展示。上排为 SFM 第一轮生成的动作轨迹,下排为 AFM 重新生成后的修正轨迹——低置信度的偏差动作被识别并纠正。
Confidence Rater(置信度评估器)
Confidence Rater 由 4 层 Transformer 加线性输出头组成(308M 参数,占总参数量 4.08B 的 7.56%),以视觉语言隐状态与 SFM 生成的动作为输入,输出每个 token 的置信度分数 q∈[0,1]。训练时使用基于相对 MSE 的伪标签:
"qt:t+L = 1 − α − β × (et:t+L − min{el }) / (max{el } − min{el } + ε)"
参数 α=0.01,β=0.98,确保标签范围始终在 [0.01, 0.99] 之内。置信度低于阈值 T=0.5 的 token 被掩码,交由 AFM 重新生成。
Asynchronous Flow Matching(异步流匹配)
AFM 推理时,未掩码 token(ml =0)直接保留 SFM 输出,掩码 token(ml =1)重新采样高斯噪声并执行 10 步 Euler 更新。为让 Transformer 同时处理混合去噪状态,引入异步时间嵌入 :对 τ⊙m 进行 sinusoidal 编码,区分已完成去噪与仍需去噪的 token。通过复用 SFM 阶段的 vision-language KV-cache,AFM 阶段仅需 10.1 ms(vs. SFM 的 83.2 ms),效率极高。
统一训练策略
以 SFM 为"全掩码 AFM 的特殊情况"进行统一训练:随机 Bernoulli 采样动作掩码,将 SFM 与 AFM 纳入同一训练过程,实现隐式数据增强。未掩码的上下文 token 加入小幅噪声扰动(σc =0.05),缩小训练与测试分布的差距;FM 时间步从 Beta(1.5, 1) 分布采样,重点覆盖噪声较多的步骤。