01 动机
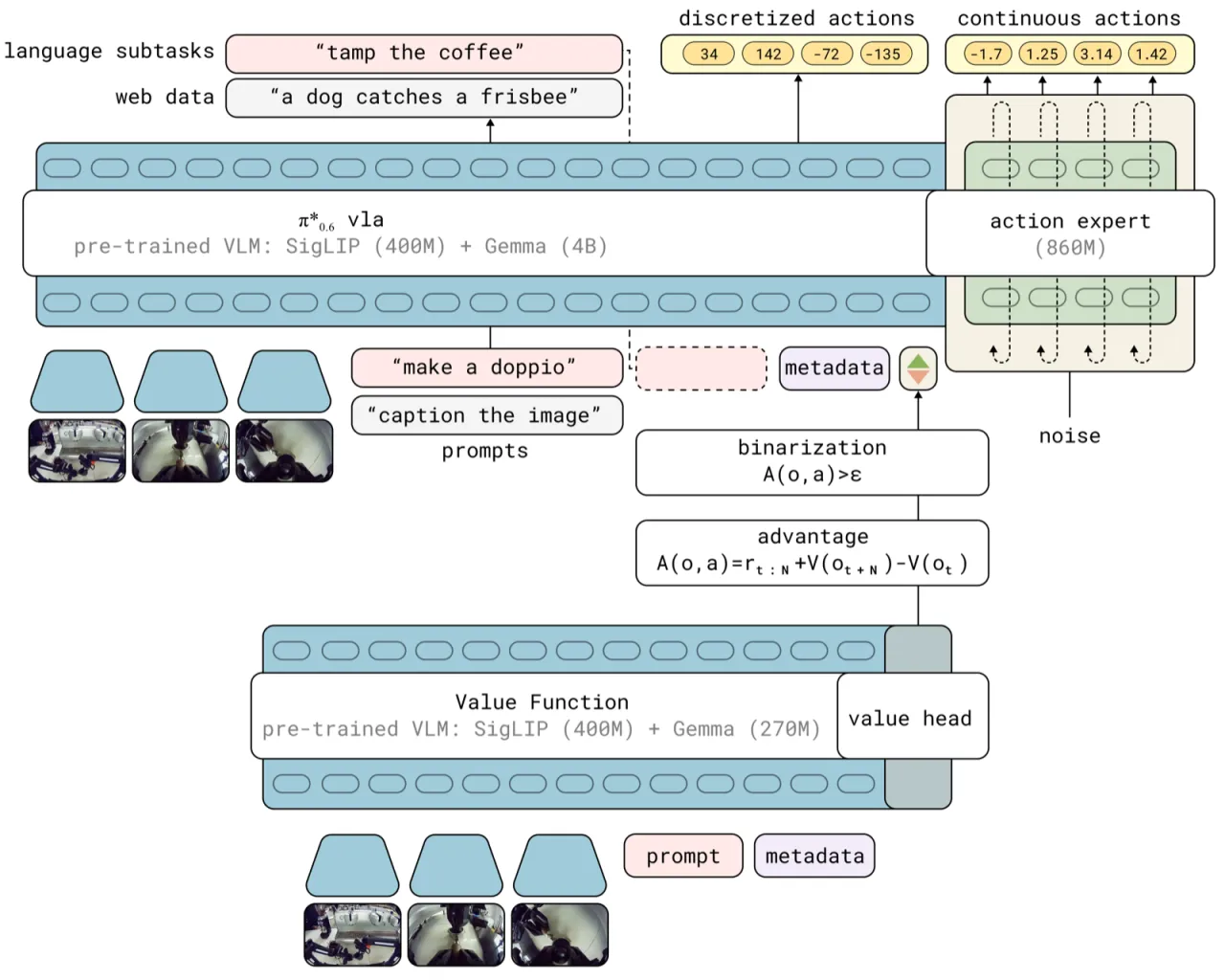
机器人基础模型能否像人类一样"熟能生巧"——通过实际操作积累经验来持续提升技能? 现有 VLA 模型依赖大量人工示范进行模仿学习,但"示范数据永远无法覆盖真实环境的所有变化", 导致模型在部署时仍会遭遇大量失败。如何高效地利用机器人自主采集的轨迹数据(包括失败、成功和人工干预), 是迈向实用级机器人自主性的关键障碍。
"Practice makes perfect — humans need many attempts at complex tasks to achieve mastery… We need methods that can learn from autonomous experience, can correct actual deployment mistakes, and can improve speed beyond human teleoperation."

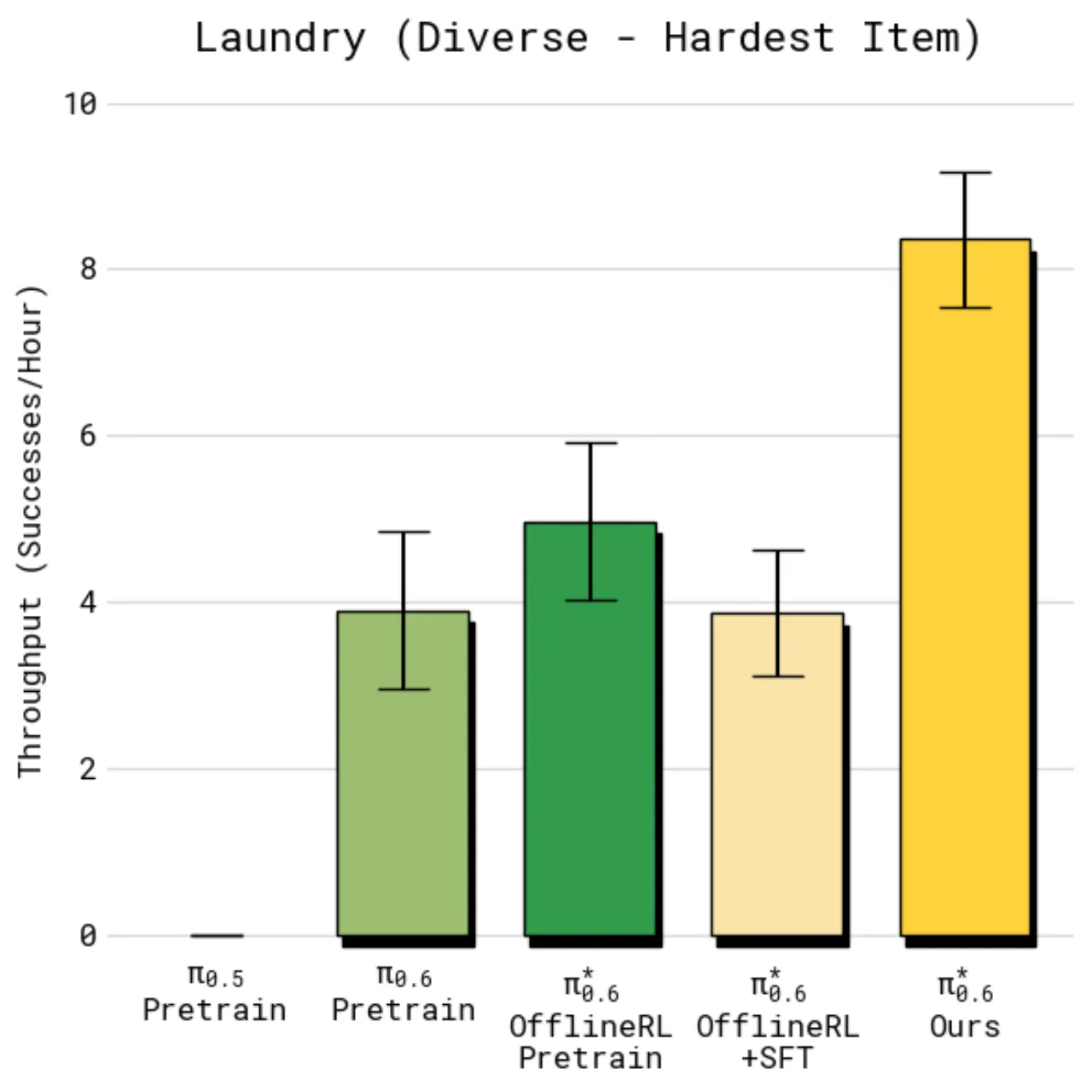
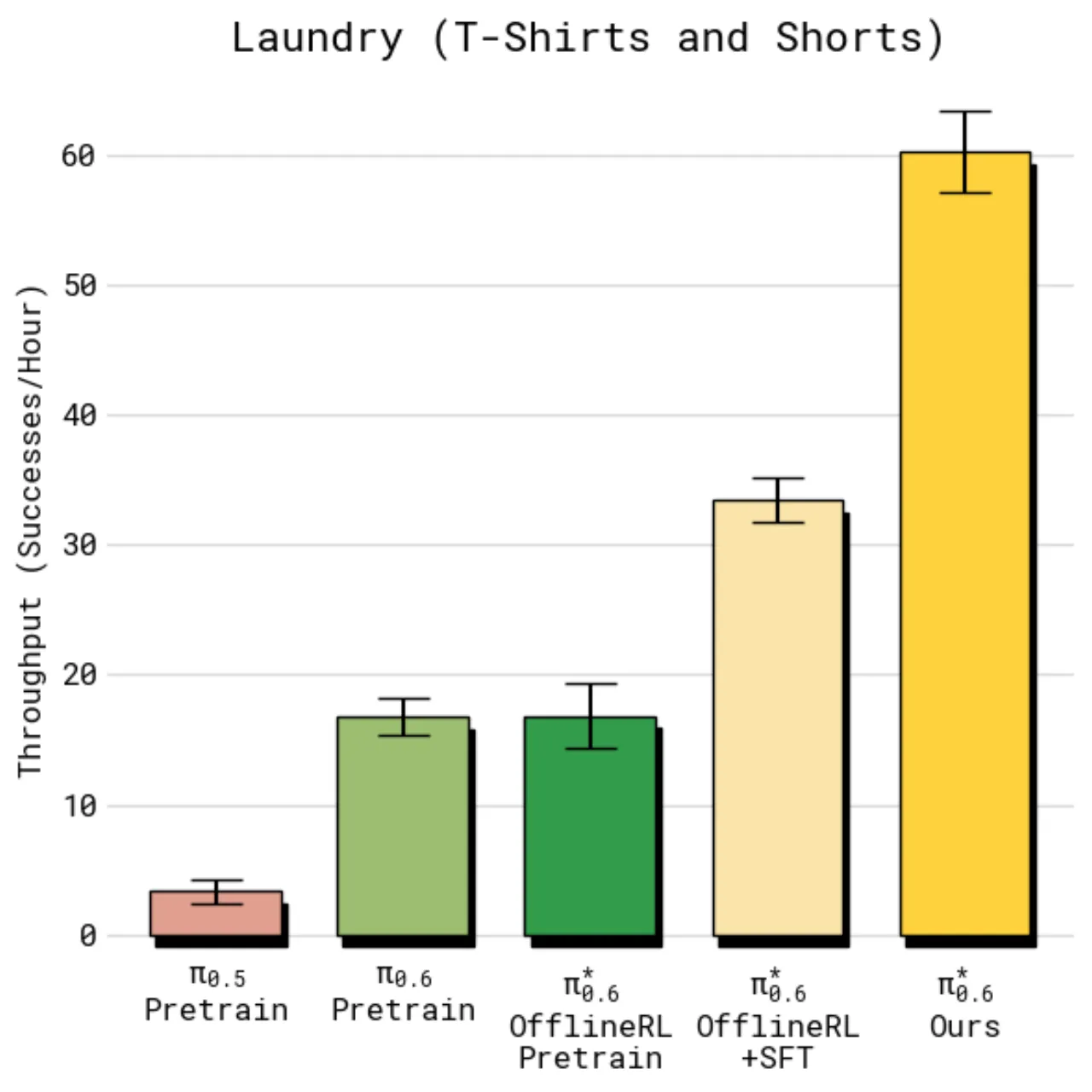
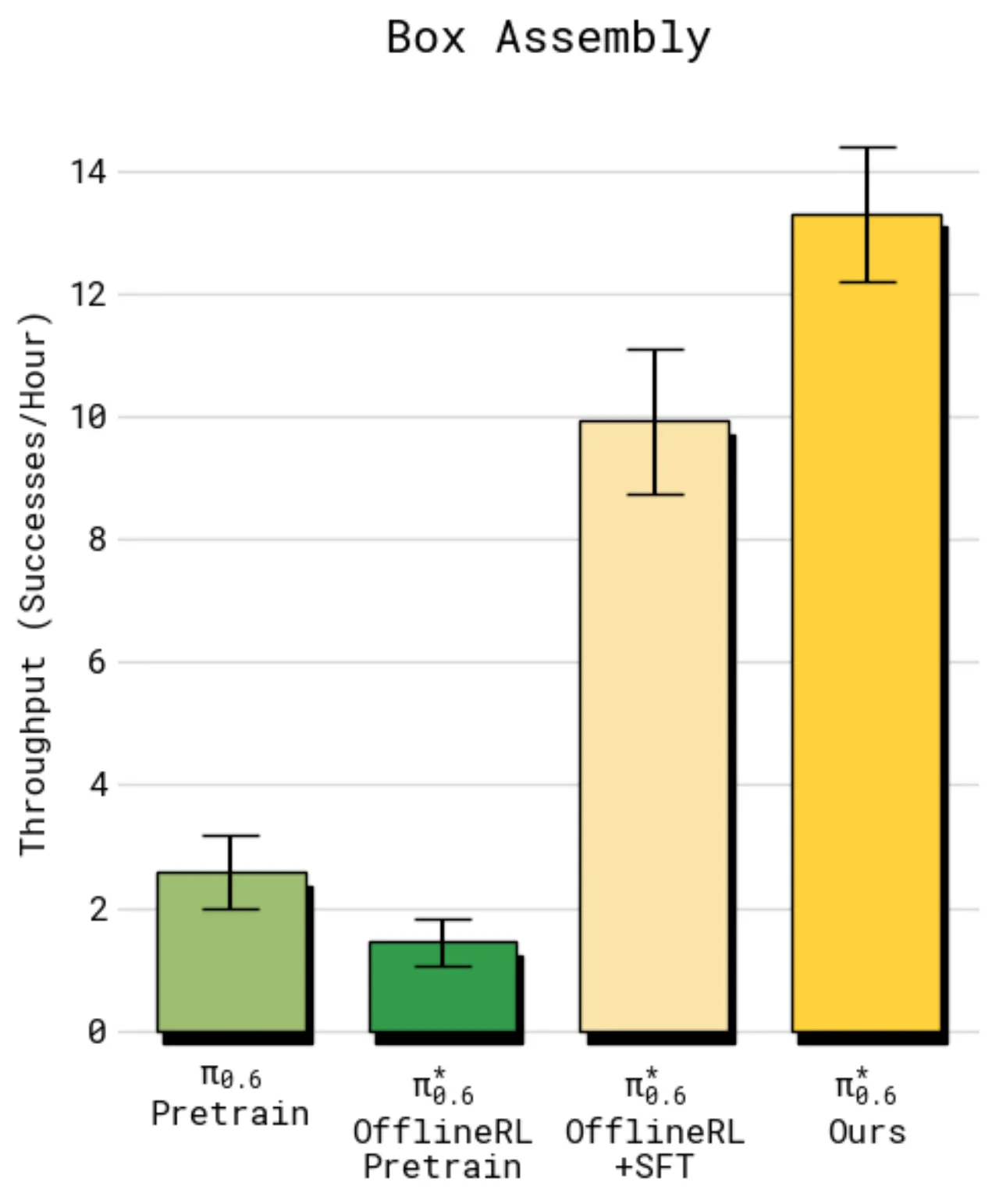
>2×多样化洗衣与咖啡任务
吞吐量提升倍数
吞吐量提升倍数
~50%失败率下降幅度
(最难任务)
(最难任务)
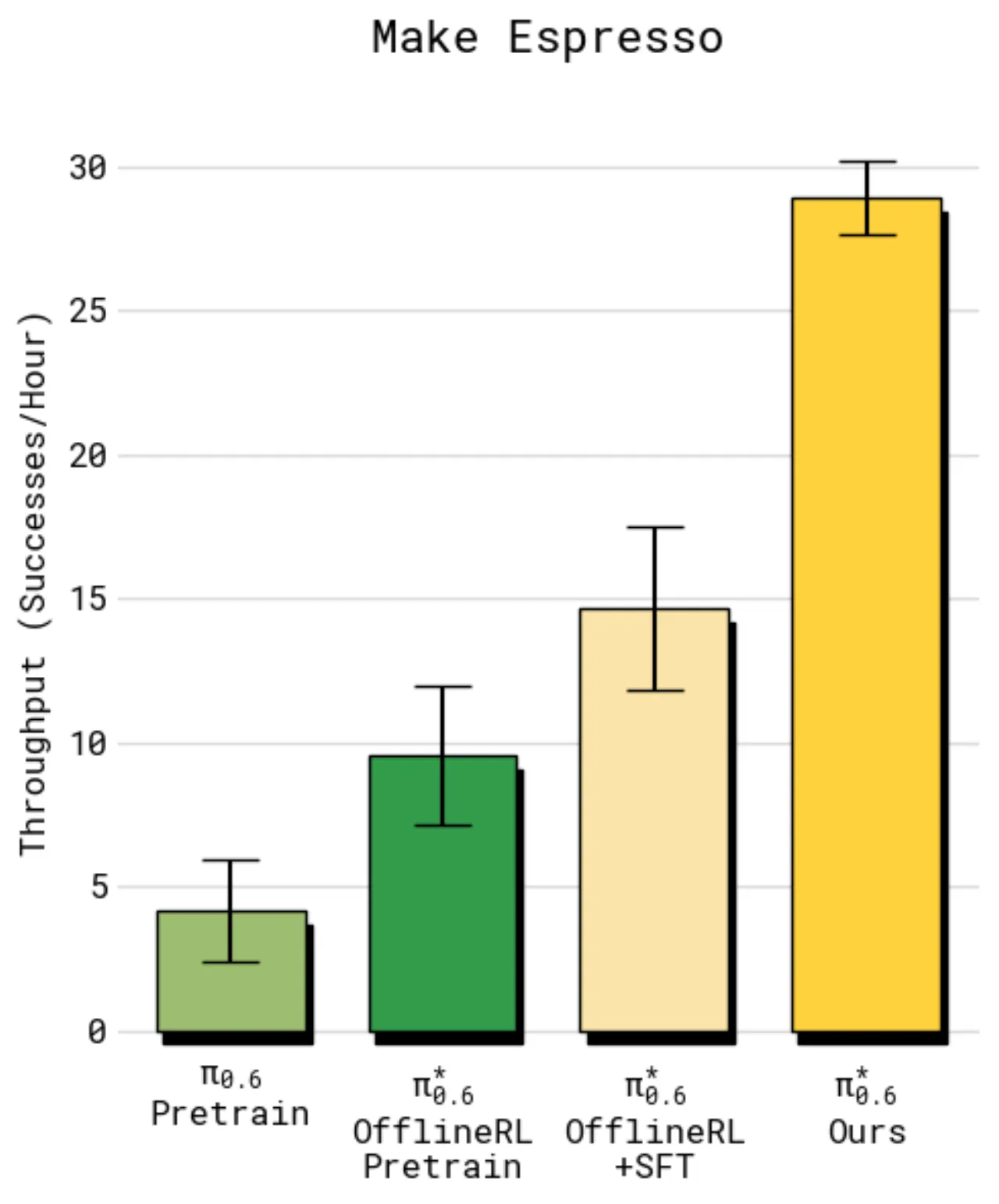
13 小时咖啡制作连续无间断
实际部署记录
实际部署记录
97%领口朝向校正子任务
严格标准下成功率
严格标准下成功率