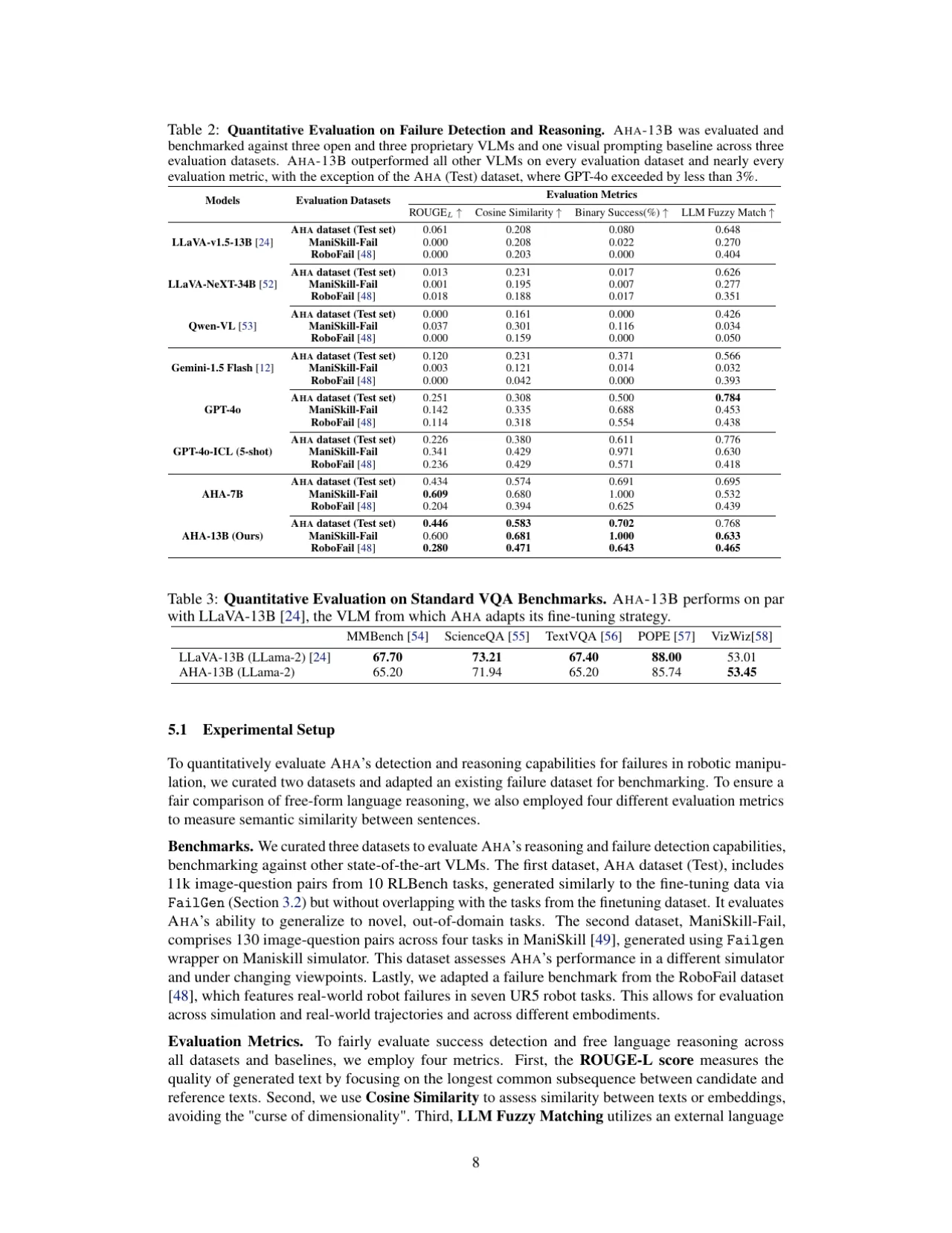
01 动机 Motivation
机器人在开放世界环境中执行操作任务时,不仅需要完成任务本身,还需要能够检测并学习自身失败。现有 VLM 和 LLM 虽然提升了机器人的空间推理与问题求解能力,但在失败识别上依然薄弱,限制了其实际应用价值。
"How can we enable these models to autonomously detect and reason about their own failures, particularly in robotics, where interactions and environments are stochastic and unpredictable?"
现有方法将失败检测视为二元分类问题(成功 / 失败),无法解释为何失败。AHA 将其重新定义为自由形式推理任务:先判断子任务是否成功,若失败则生成简洁的自然语言解释,说明失败的原因与发生方式。这使得 AHA 能够跨越不同机器人形态、相机视角、任务和环境进行泛化,并无缝集成到利用 VLM/LLM 的下游机器人应用中。
+10.3%超越 GPT-4o ICL
(第二佳模型)
(第二佳模型)
+35.3%超越六模型平均
(含五个 SOTA VLM)
(含五个 SOTA VLM)
+21.4%下游三任务
平均成功率提升
平均成功率提升
49K+AHA 数据集
失败轨迹图文对
失败轨迹图文对