01 动机
通用机器人操作的核心挑战在于:模型能否将学到的技能迁移到从未见过的任务上?现有 VLA 模型(包括 π0、OpenVLA、RDT 等)的跨任务泛化能力几乎未被系统研究,缺乏统一的评估框架。
"The cross-task generalization capabilities of existing VLA models remain significantly underexplored."
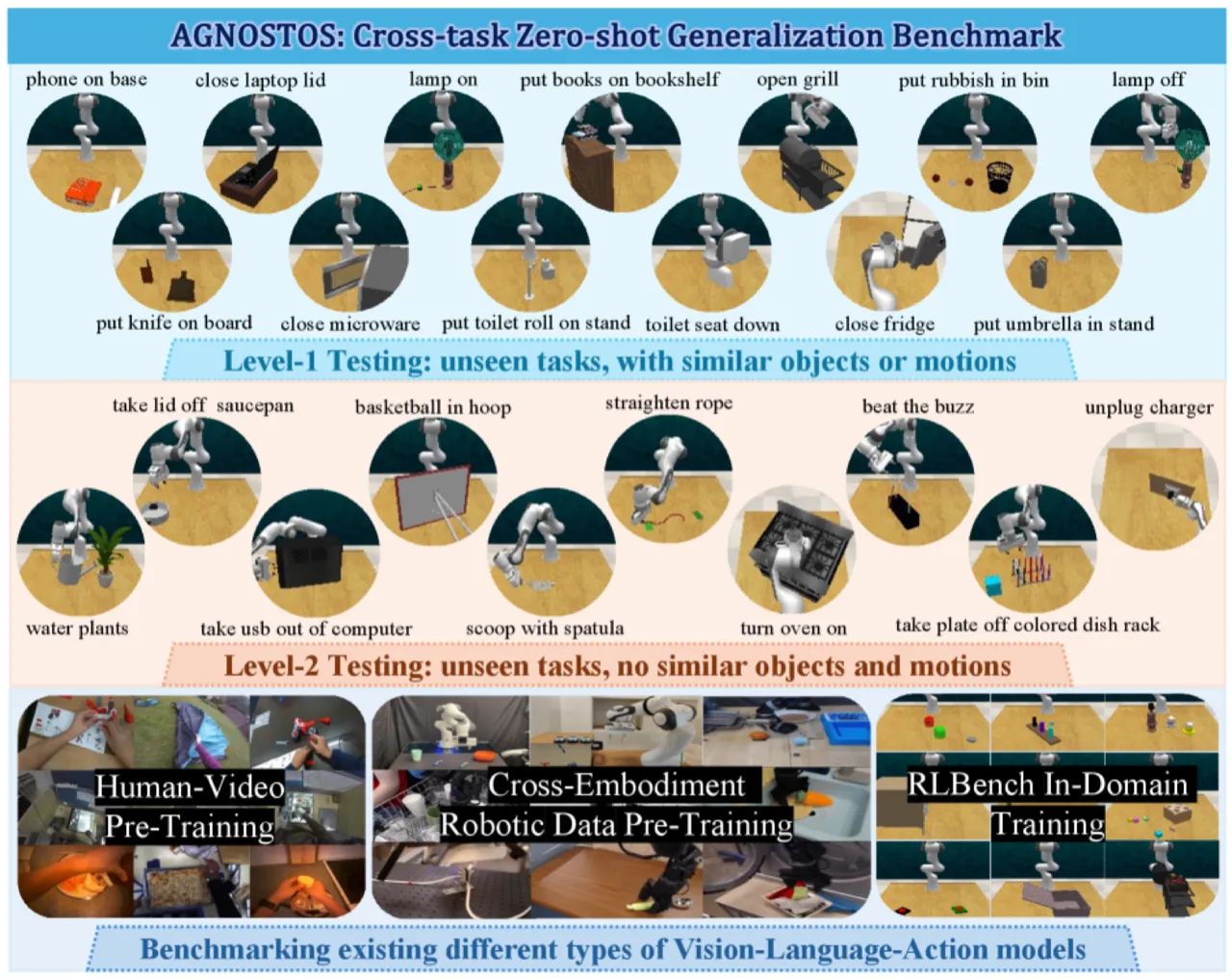
23未见测试任务总数
13 + 10Level-1 + Level-2
18已见训练任务数(RLBench)
12+评测的 VLA 模型类别
现有跨任务评估基准(如 Colosseum、GemBench)缺乏对 foundation model 与人类视频预训练模型的系统比较,且未区分难度级别。AGNOSTOS 通过双难度设计和多类别 VLA 评测,首次全面揭示了当前模型的跨任务能力边界。
已评测 VLA 模型类别
- 域内模型:PerAct, RVT, RVT2, Sigma-Agent, InstantPolicy
- 人类视频预训练:R3M, D4R 系列
- Foundation model:OpenVLA, RDT, π0, VoxPoser, SAM2Act, 3D-LOTUS++
核心发现
- 所有现有 VLA 基线在 23 个未见任务中均表现欠佳
- 多个模型在 ≥8 个任务上完全失败(成功率 0%)
- Level-2 难度对所有模型均构成显著挑战
- X-ICM 是唯一在全部 23 个任务中均有成功的方法