01 动机
机器人学习在大规模基础模型建设上远落后于 NLP 与计算机视觉,根本原因在于高质量数据采集的困难。 现有数据集往往受限于实验室受控环境、短时序任务和异构硬件,导致策略难以迁移至真实世界的多样场景。
"existing robot learning datasets remain constrained by their reliance on short-horizon tasks in highly controlled laboratory environments"
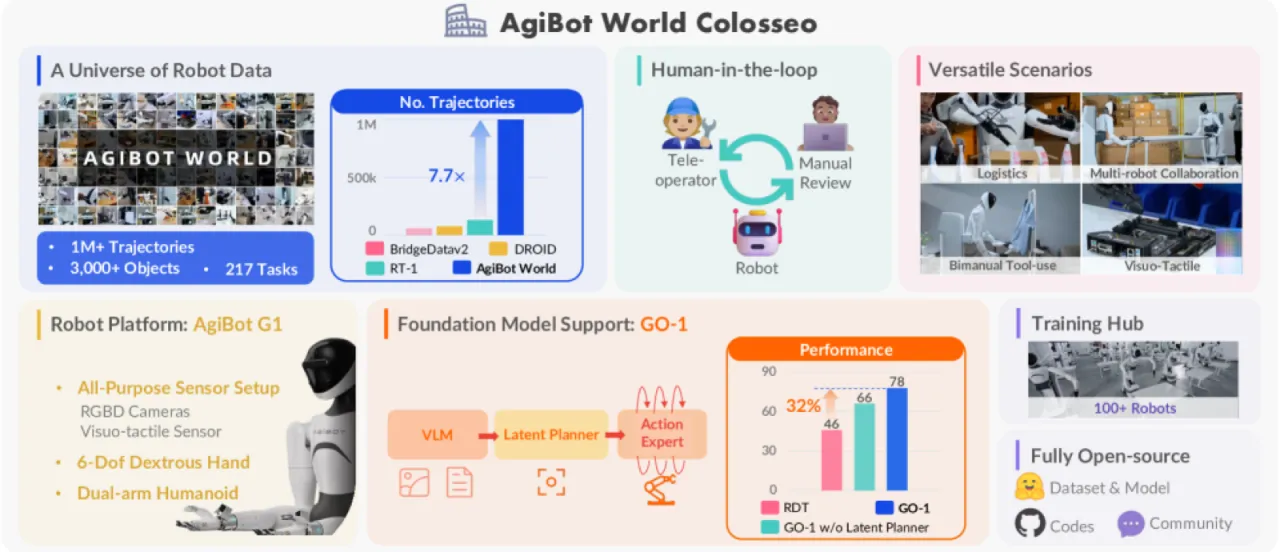
1M+操作轨迹总量
217覆盖任务数量
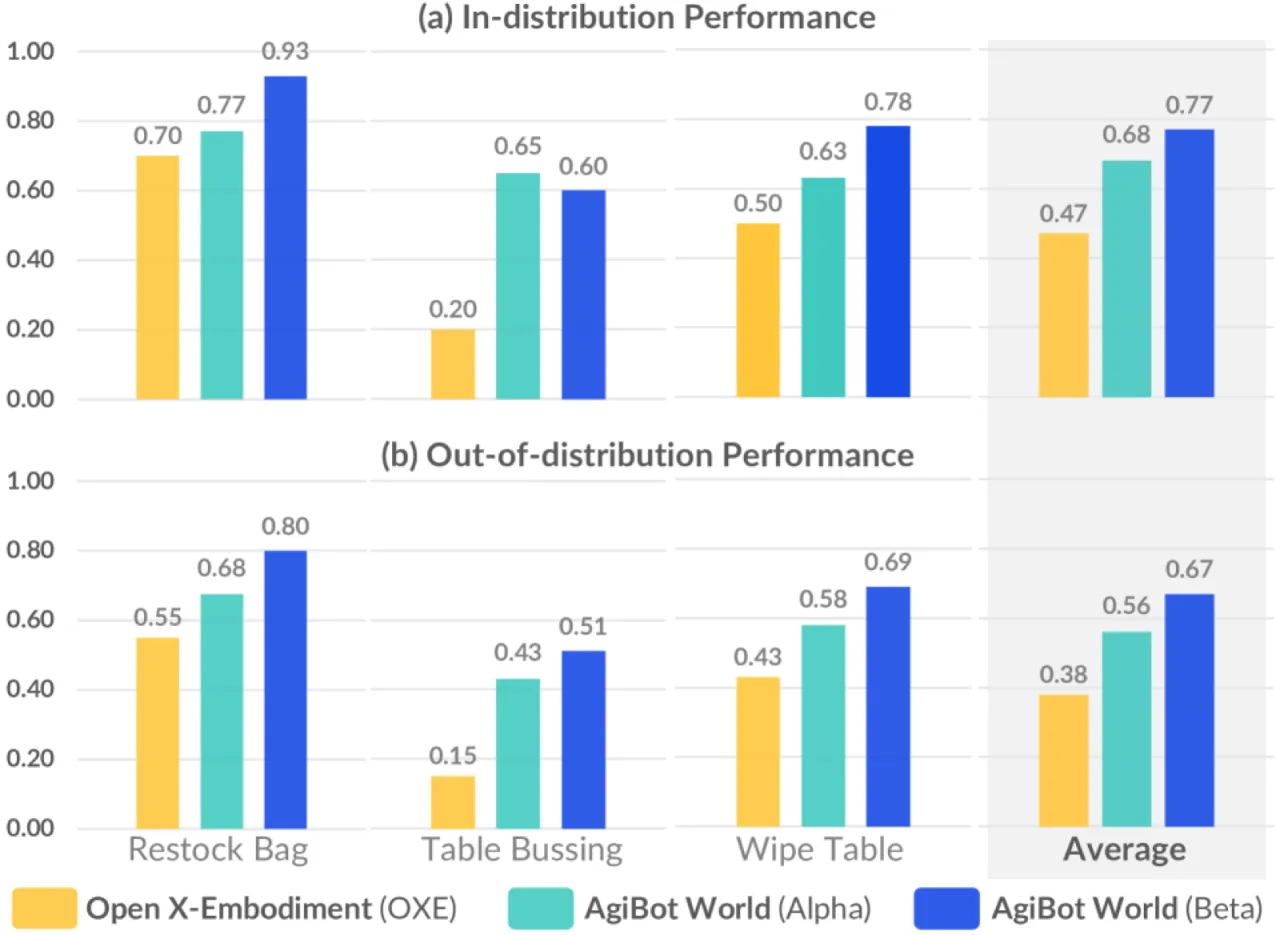
+30%vs. Open X-Embodiment 平均提升
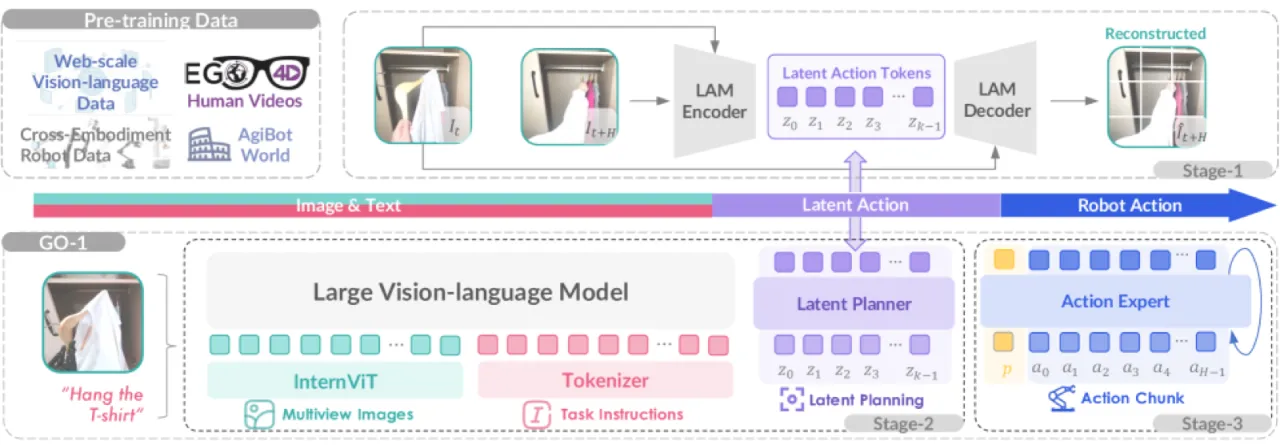
+32%GO-1 vs. RDT 提升
现有数据集的三大瓶颈
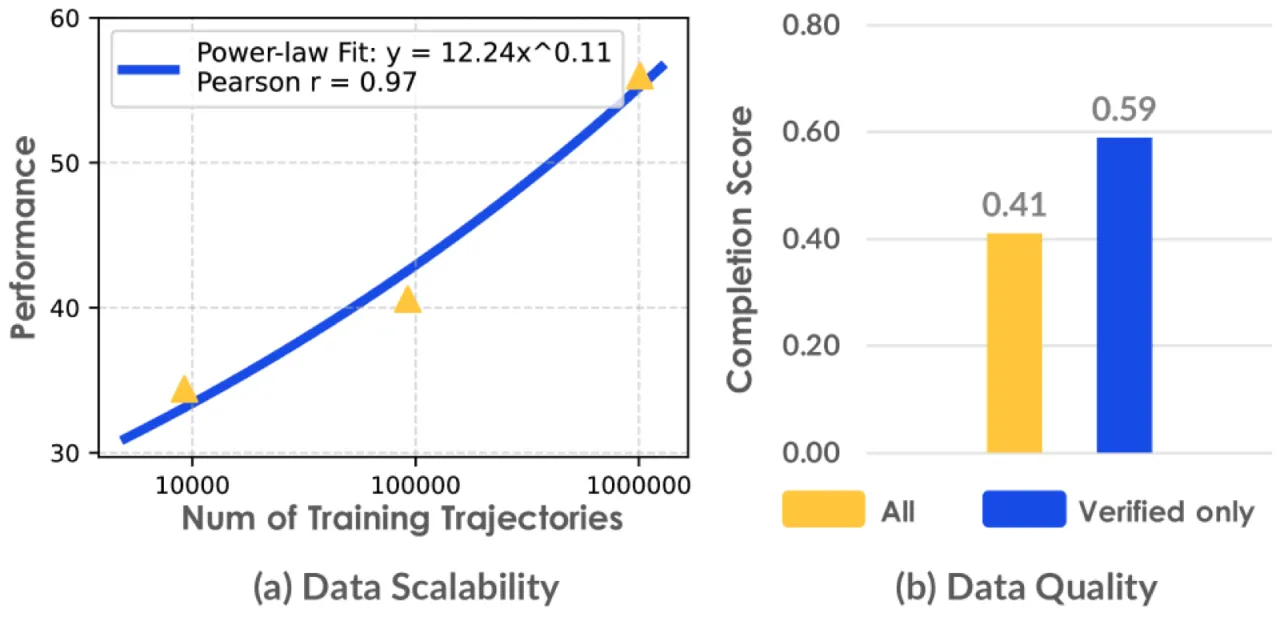
- 规模不足:已有数据集(如 Open X-Embodiment)在轨迹量和任务多样性上均大幅落后,难以支撑 scaling law 研究。
- 任务简单:现有基准多为 5–20 秒的短时序抓取任务,无法覆盖现实中需要 30–60+ 秒的长时序操作需求。
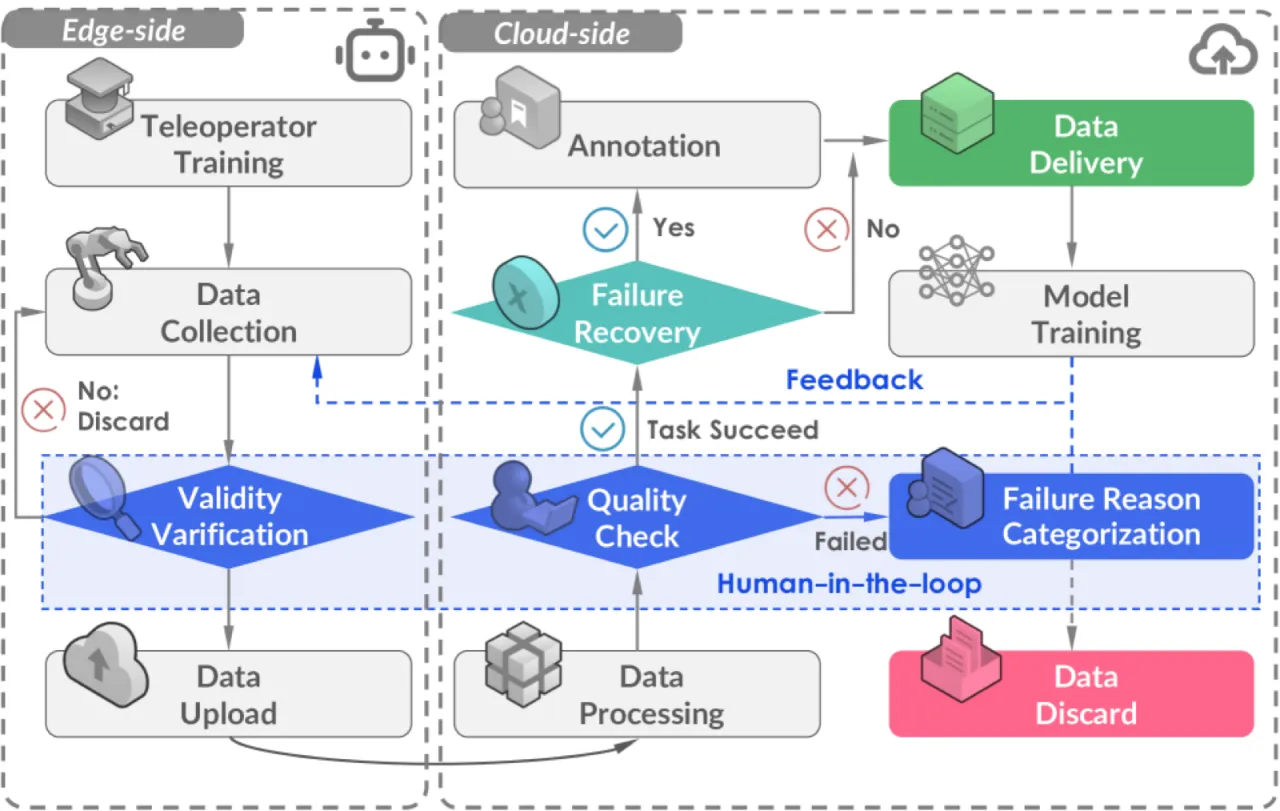
- 质量参差:采集流程缺乏系统性质量控制,数据标注不一致,限制了下游策略的泛化能力。