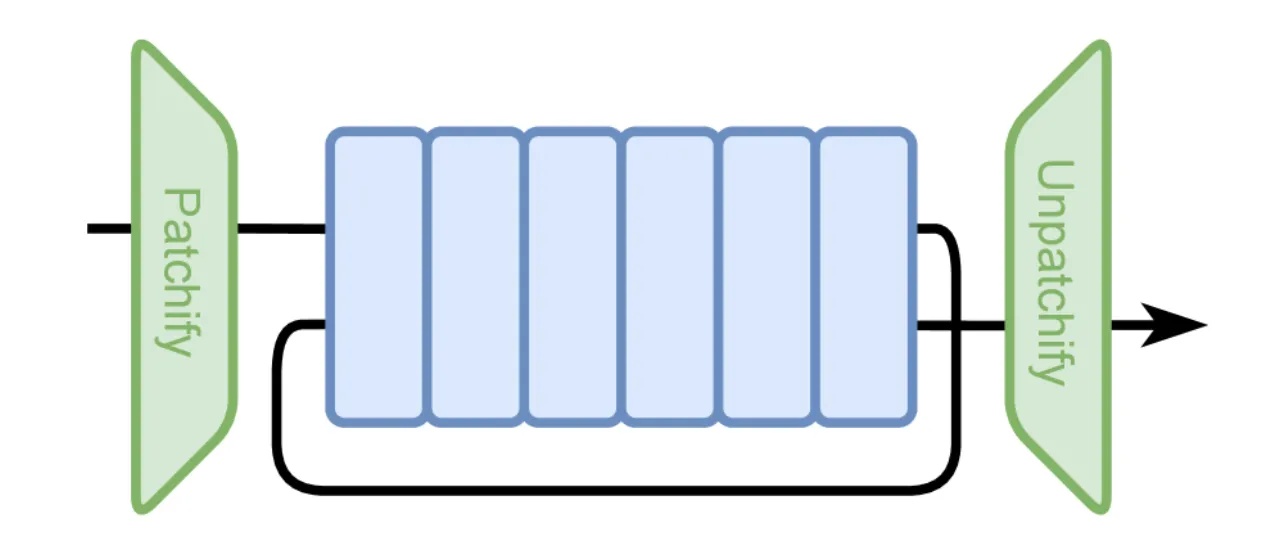
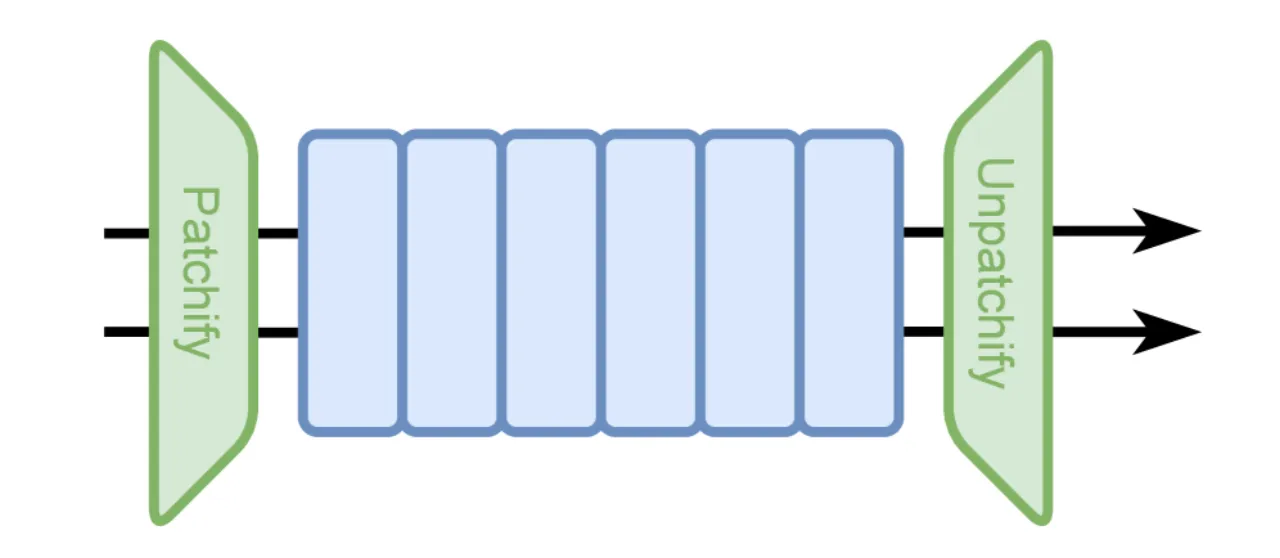
01 动机
现有单步生成方法面临两类核心问题:GAN 训练不稳定,一致性模型(Consistency Models)引入中间时间步监督导致模型容量受限。 作者指出,对抗目标本身无法确定唯一的优化目标,噪声到数据之间存在无穷多条合法的传输路径,导致 GAN 学到任意映射而非确定性最优传输。
"The adversarial objective alone does not define a single optimization target, leaving infinitely many valid transport maps between noise and data distributions."
2.38AFM-XL/2 单步 FID
(ImageNet 256px,带引导)
(ImageNet 256px,带引导)
1.94112 层深度架构
单步 FID 最优
单步 FID 最优
2.02AFM-XL/2 4 步 FID
(超过 MeanFlow/AlphaFlow)
(超过 MeanFlow/AlphaFlow)
3.98AFM-XL/2 单步 FID
(无引导,仍大幅优于 FM 250步 9.62)
(无引导,仍大幅优于 FM 250步 9.62)
先前工作的不足
GAN 的问题
- 对抗目标无法唯一确定传输映射
- 生成器学到随机/任意的噪声到数据映射
- 训练在大型 Transformer 架构上不稳定
- 判别器损失在 ImageNet 等复杂数据上容易发散
一致性模型的问题
- 需要对每个中间时间步 t 进行监督(distillation 或 consistency training)
- 单步生成时模型容量被中间步骤占用,质量受限
- 无法像单纯的 GAN 那样直接利用判别器的感知能力