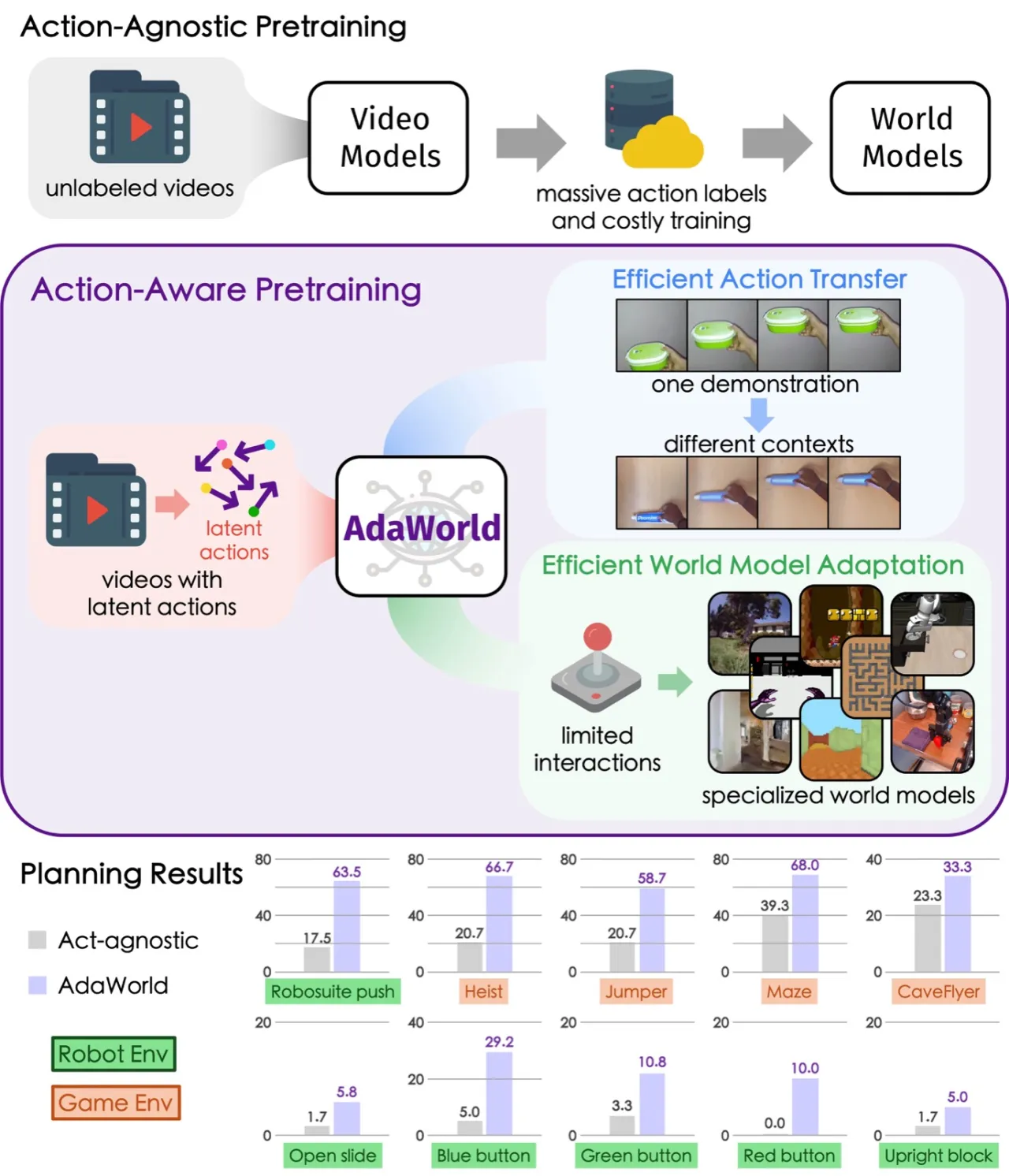
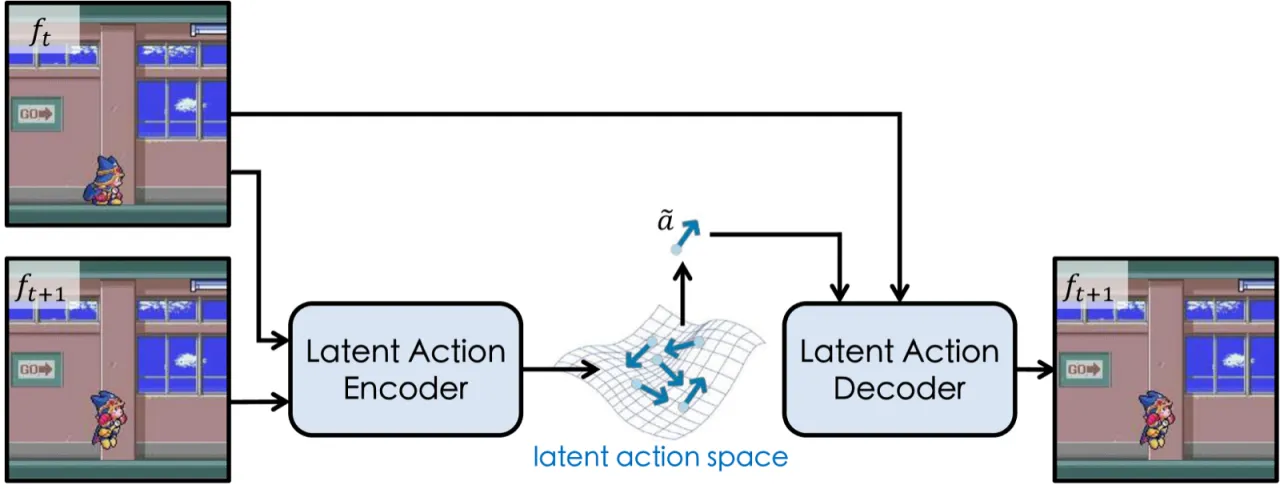
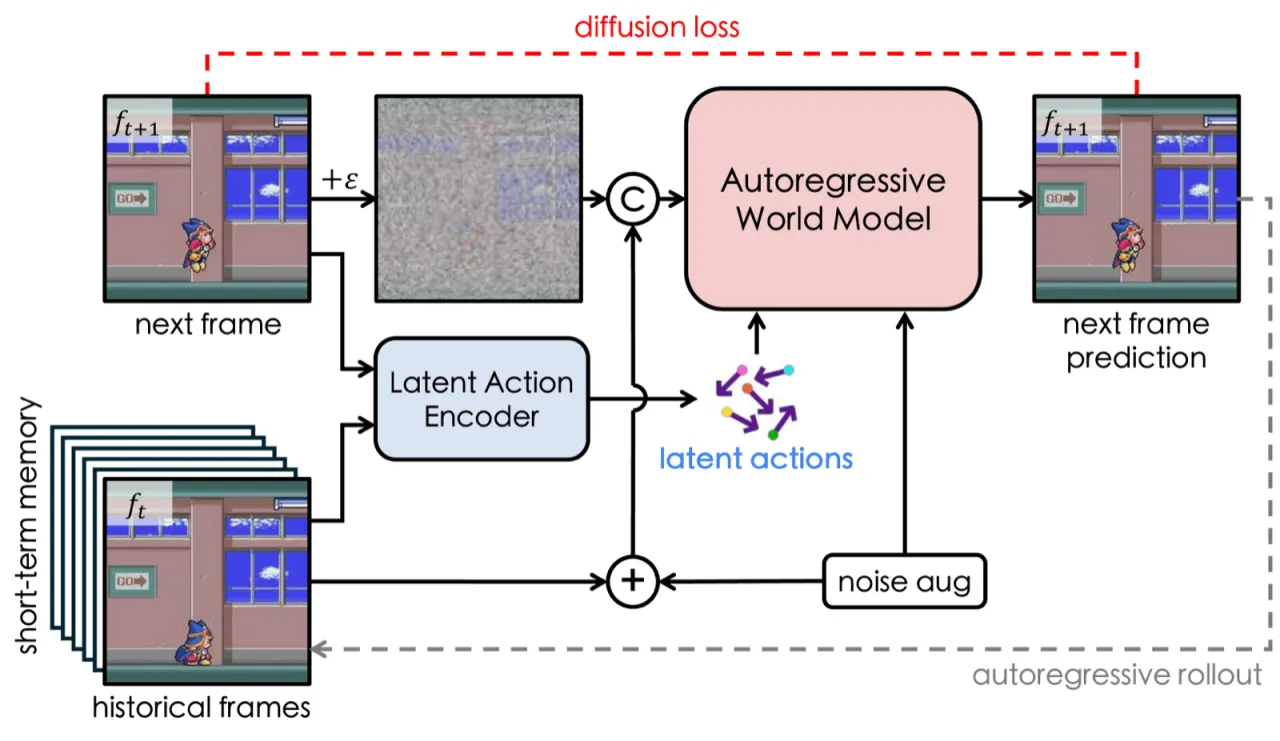
"most existing world models rely heavily on substantial action-labeled data and costly training, making it challenging to adapt to novel environments with heterogeneous actions through limited interactions."
Figure 4:动作迁移与组合。左:AdaWorld 可准确识别演示动作并将其迁移到不同场景,而 baseline 方法失败。右:通过在 latent space 中对两个 latent action 做平均,可组合出语义上融合二者功能的新动作,表明 latent action 空间在动作语义上是连续的("our latent action space is semantically continuous in the meanings of actions")。