01 动机 · Motivation
视频生成模型在机器人领域展现出两种应用路径:作为 visual planner(视觉规划器)或 policy supervisor(策略监督器)。 然而,互联网预训练视频模型与机器人领域数据之间存在根本矛盾:前者拥有强大的语言对齐能力,却缺乏对特定机器人环境的感知;后者则受限于数据规模,难以支持跨任务的自然语言泛化。
"Video generative models demonstrate great promise in robotics by serving as visual planners or as policy supervisors. When pretrained on internet-scale data, such video models intimately understand alignment with natural language, and can thus facilitate generalization to novel downstream behavior through text-conditioning. However, they may not be sensitive to the specificities of the particular environment the agent inhabits."

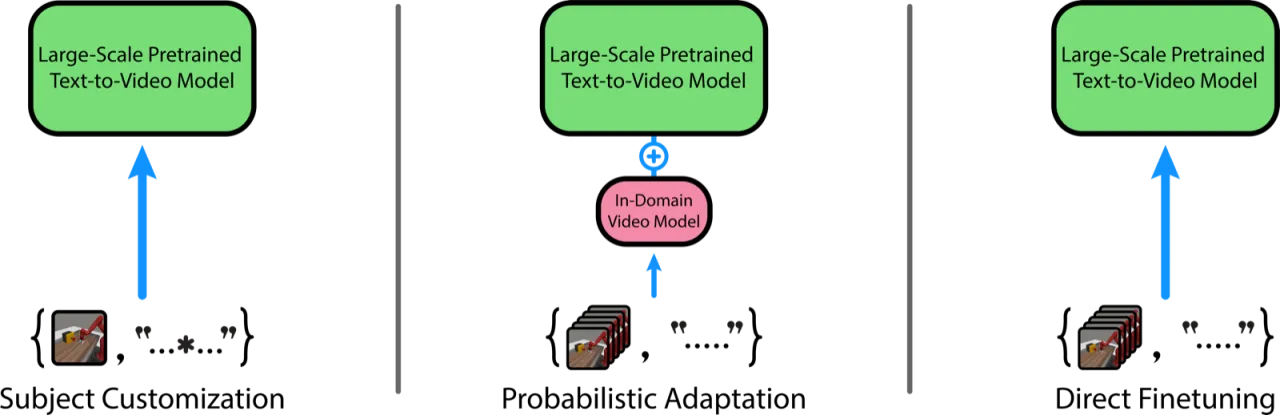
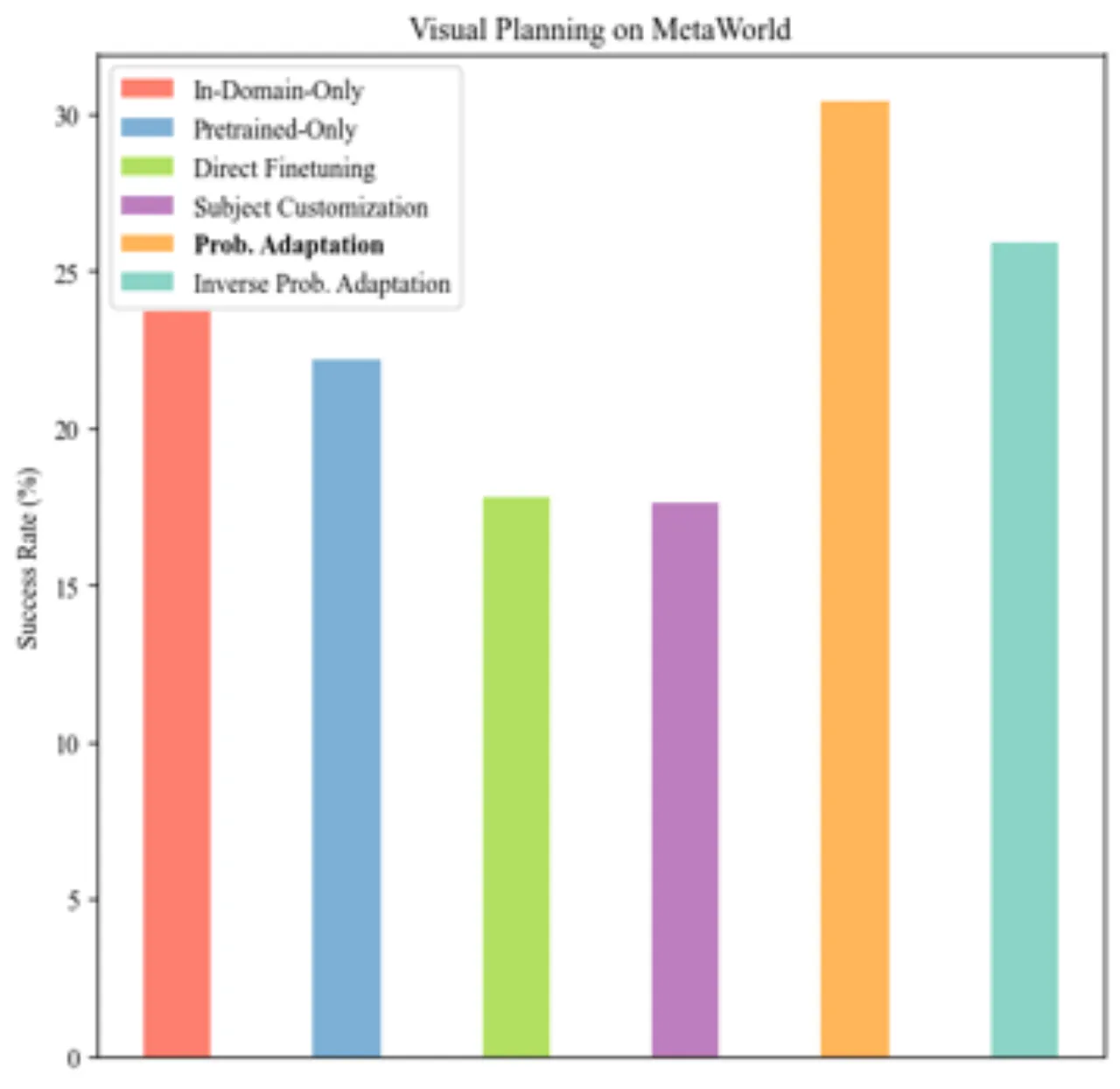
4种 adaptation 技术对比
9MetaWorld 机器人任务
2应用路径(Visual Planning / Policy Supervision)
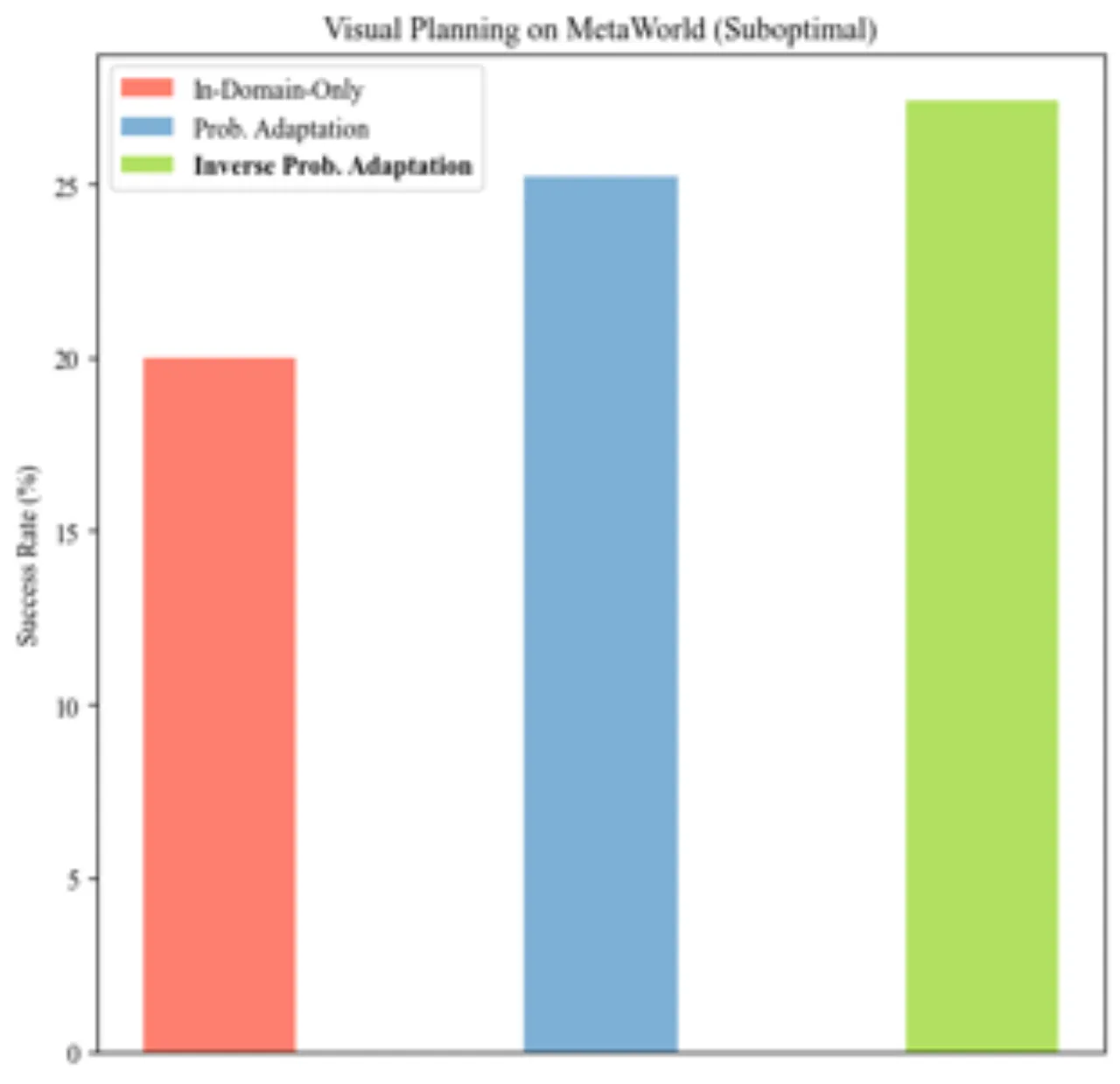
✓次优数据下仍稳健泛化