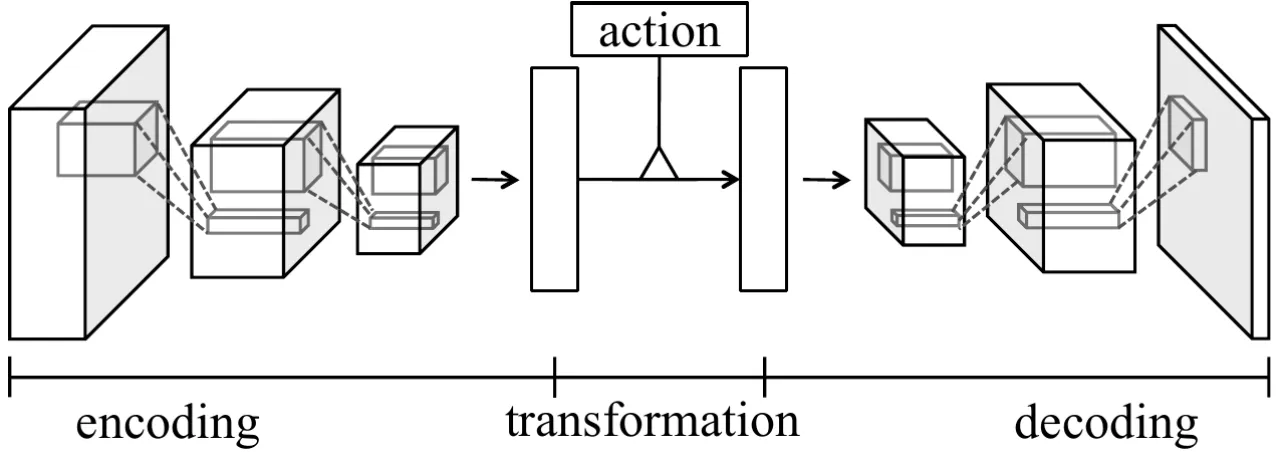
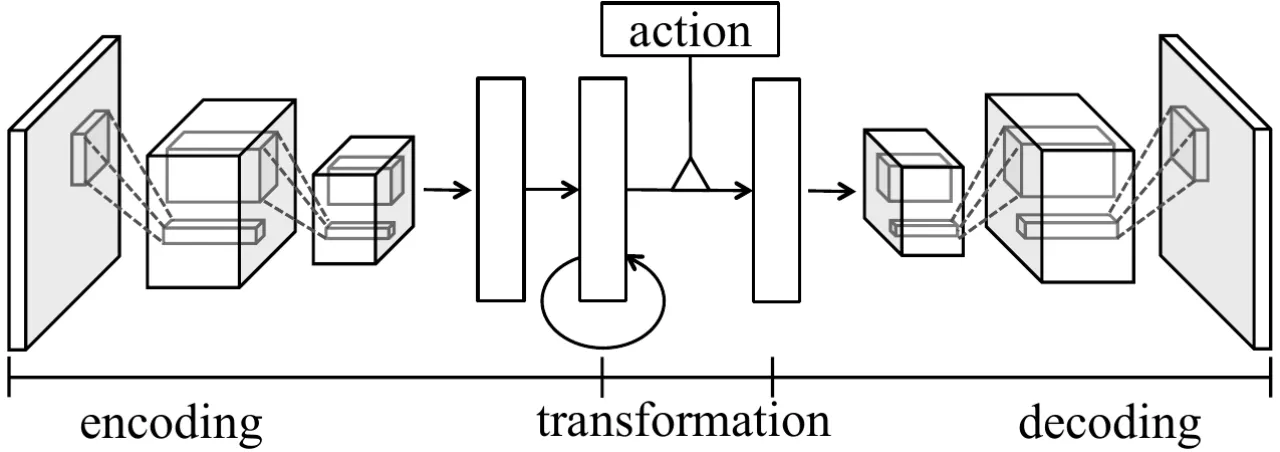
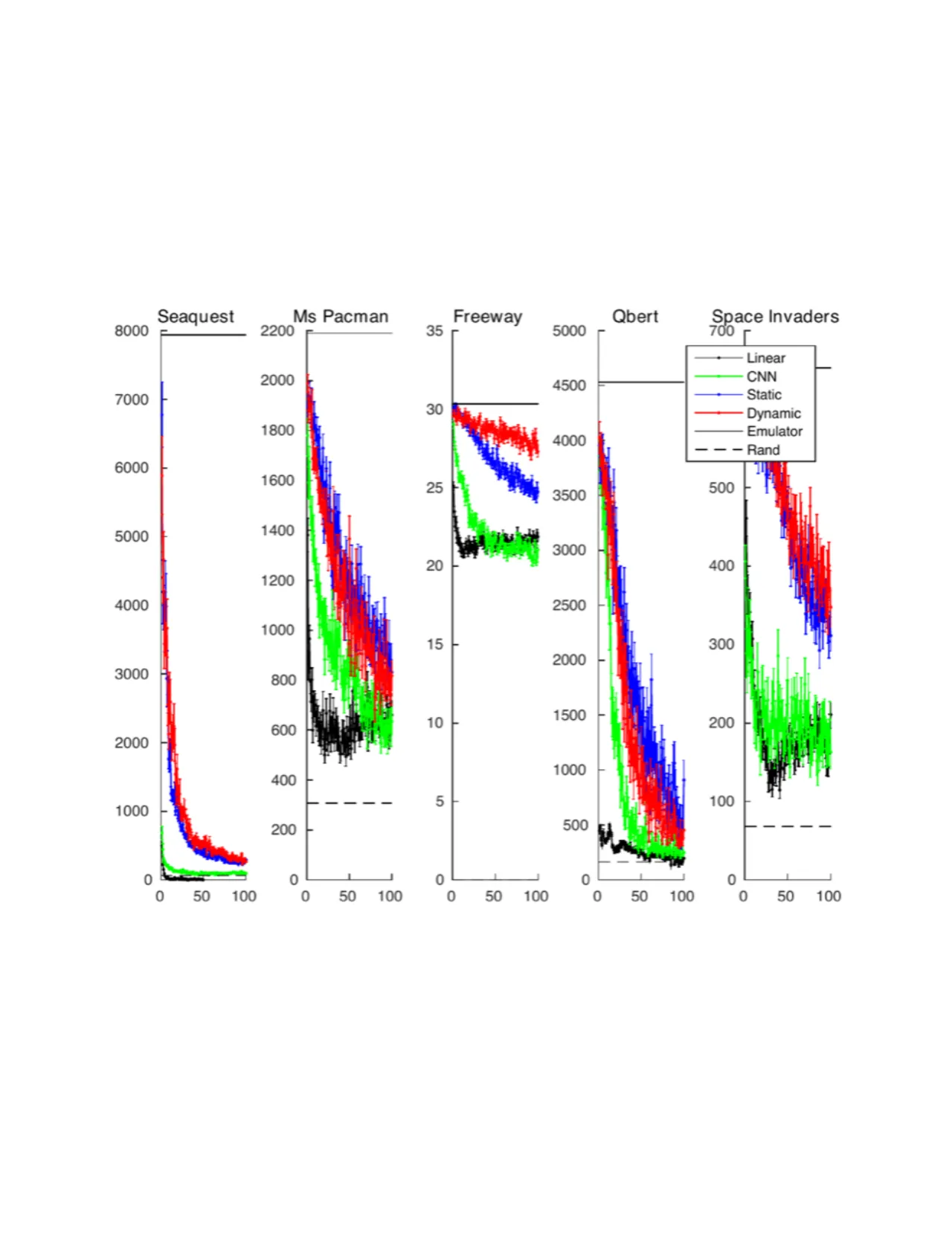
"To the best of our knowledge, this paper is the first to make and evaluate long-term predictions on high-dimensional video conditioned by control inputs."
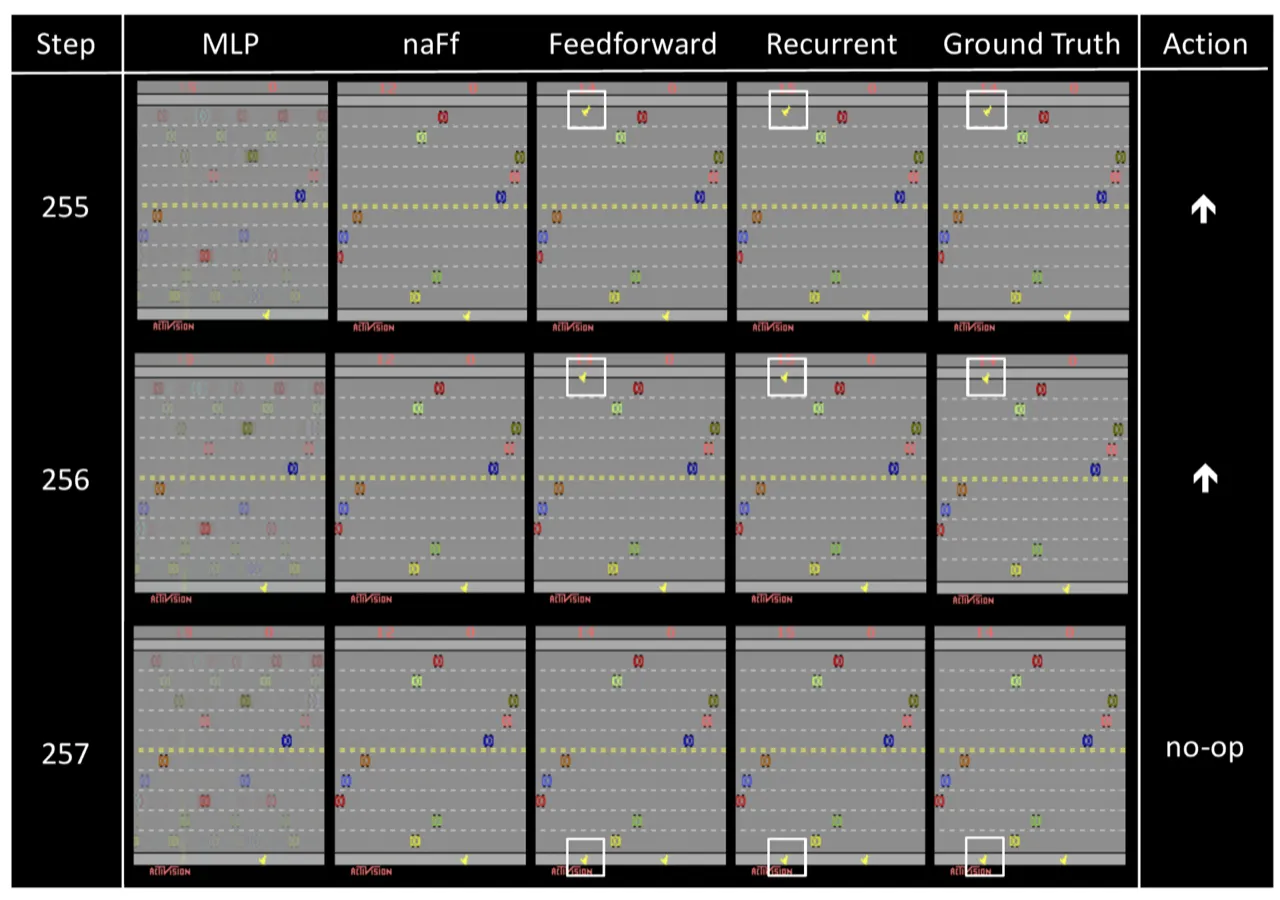
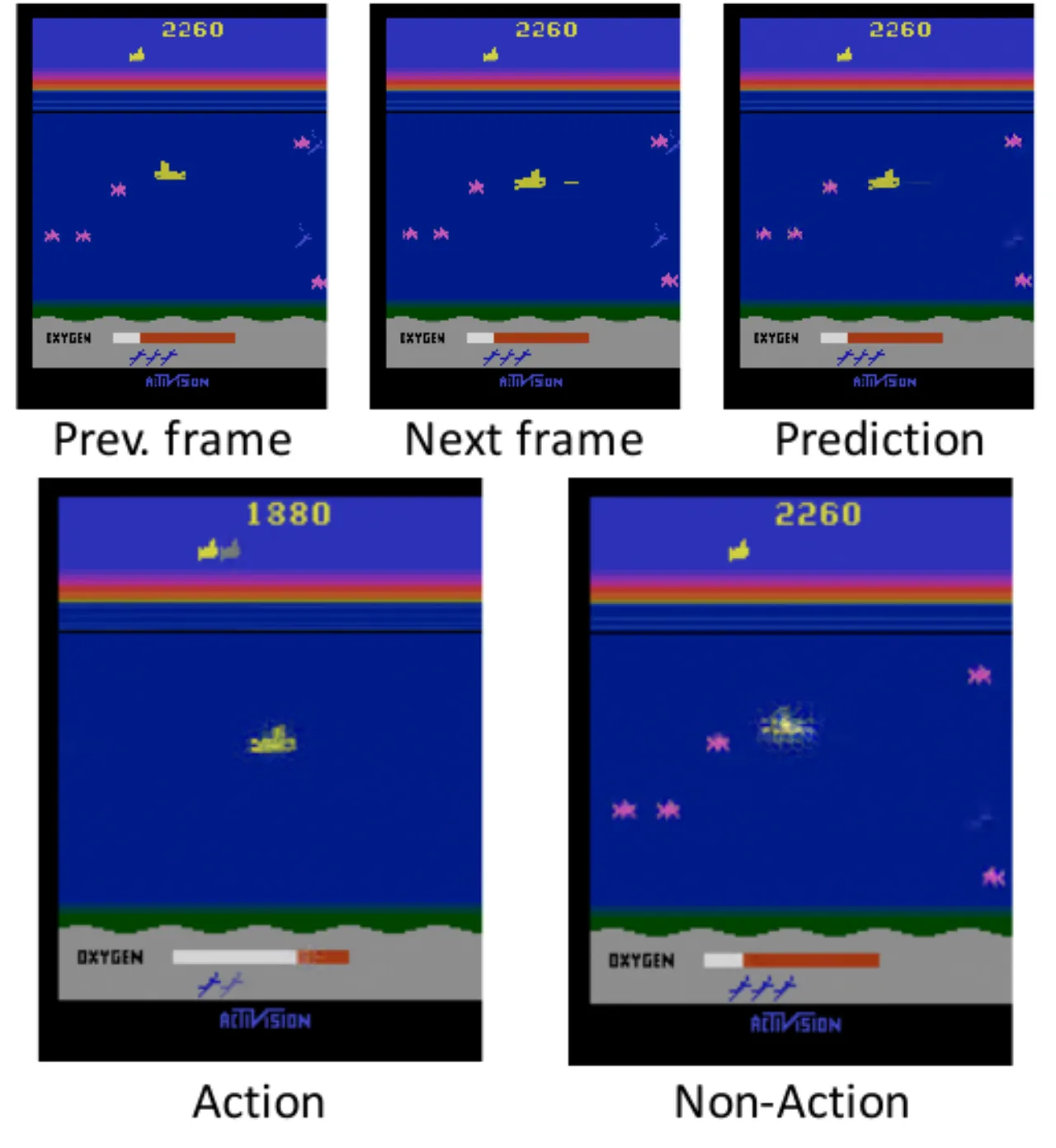
"Both of our models have difficulty in accurately predicting small objects, such as bullets in Space Invaders. The reason is that the squared error signal is small when the model fails to predict small objects during training."——以 MSE 为损失函数时,小对象的像素误差对总损失贡献极小,导致模型缺乏充足的学习信号。
随机性处理困难(stated)
"In Seaquest, e.g., new objects appear from the left side or right side randomly, and so are hard to predict. Although our models do generate new objects with reasonable shapes and movements…the generated frames do not necessarily match the ground-truth."——随机出现的对象(如敌方潜水艇)无法被确定性模型精确预测,生成结果在形状和运动方向合理,但位置不一定与真实帧吻合。
Feedforward 编码无法捕获长期依赖(stated)
"[Feedforward architecture] is not suitable for long-term dependencies because it requires more memory and parameters as more frames are concatenated into the input."——在 Freeway 等游戏中,当智能体进入新阶段后动作被忽略 9 步,前馈架构因输入窗口仅为最近 4 帧而无法建模这一长期状态,导致在该场景下发生错误预测(diverge)。
尚未延伸至 reward 预测与完整 model-based RL(stated)
论文结论中指出:"In future work we will learn models that predict future reward in addition to predicting future frames and evaluate the performance of our architectures in model-based RL."——当前架构仅预测像素帧,尚未整合奖励信号预测,因此不能直接支撑完整的 model-based RL 规划。