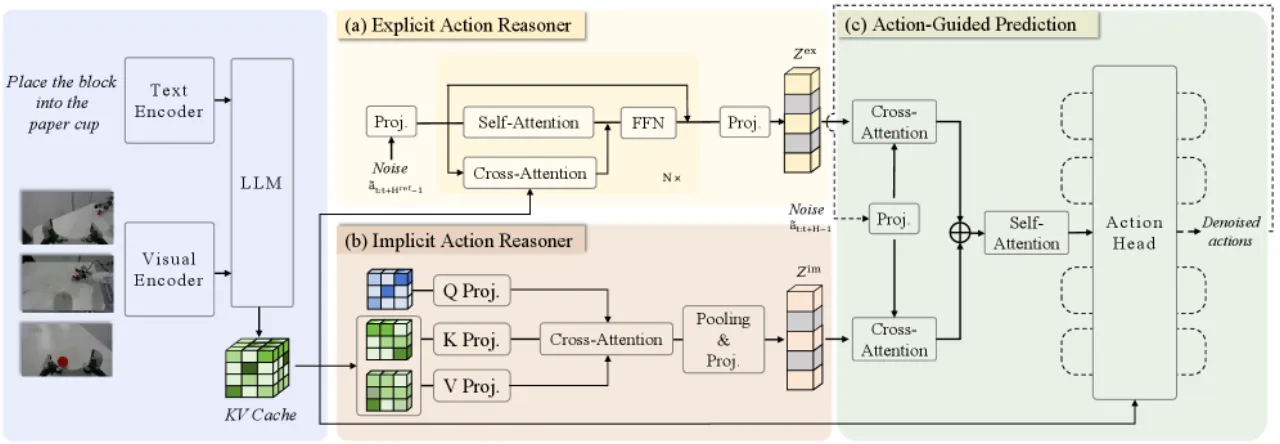
01 动机
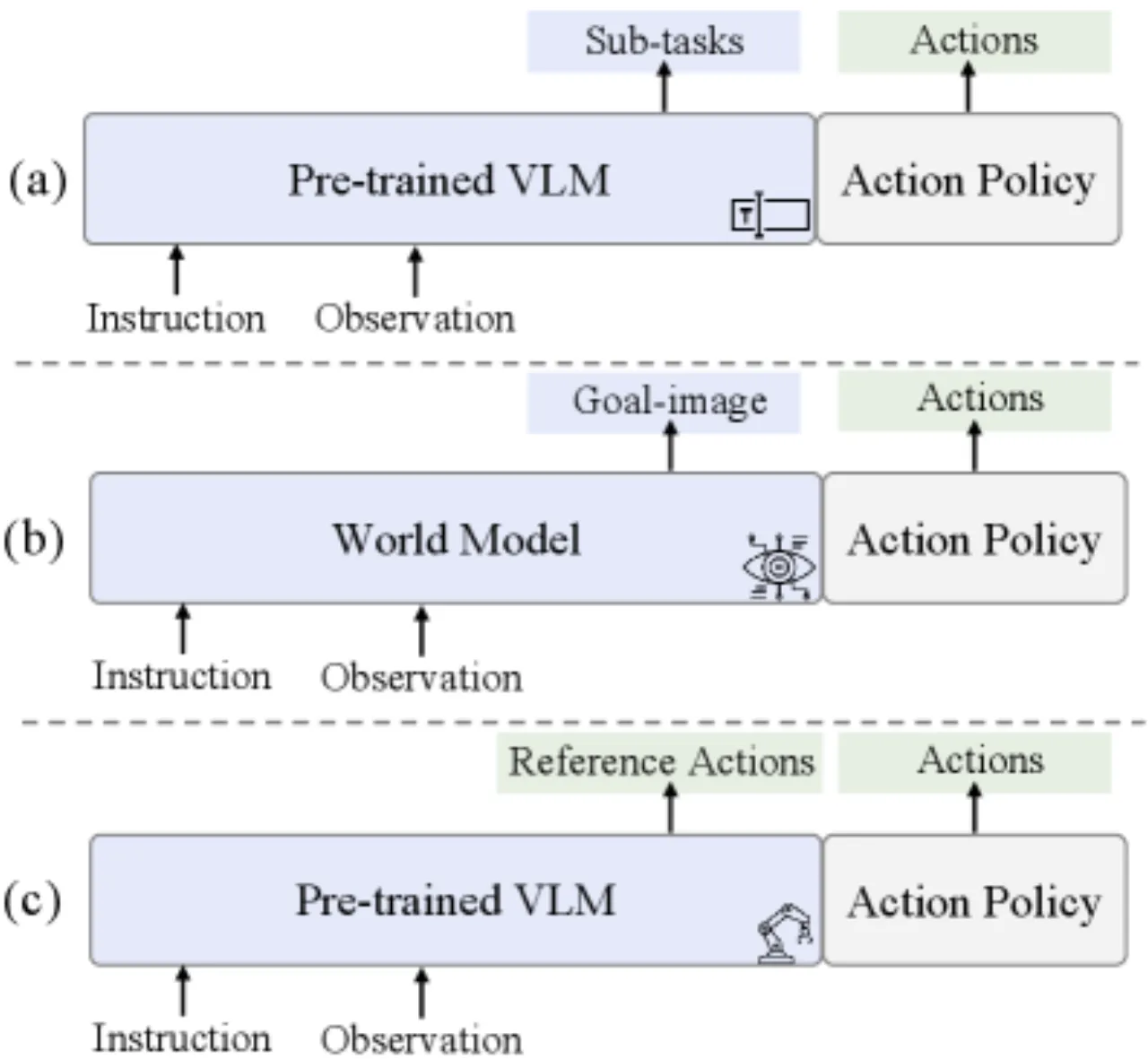
现有 VLA 模型从互联网规模的语义数据中获取了丰富知识,但缺乏对物理动力学的理解。语言 CoT 和视觉 CoT 两种主流中间推理范式,均因"语义-运动异质性(semantic-kinematic gap)"而难以为精确执行提供有效引导。
"Language CoT predicts sub-tasks as intermediate reasoning. Visual CoT synthesizes a goal image to provide guidance for action policy. Our proposed Action CoT directly operates in action space and provides homogeneous action guidance."
98.5%LIBERO 平均成功率(4个任务集)
+1.6%超越前 SOTA π0.5 的绝对提升
86.6%LIBERO-Plus 零样本迁移成功率
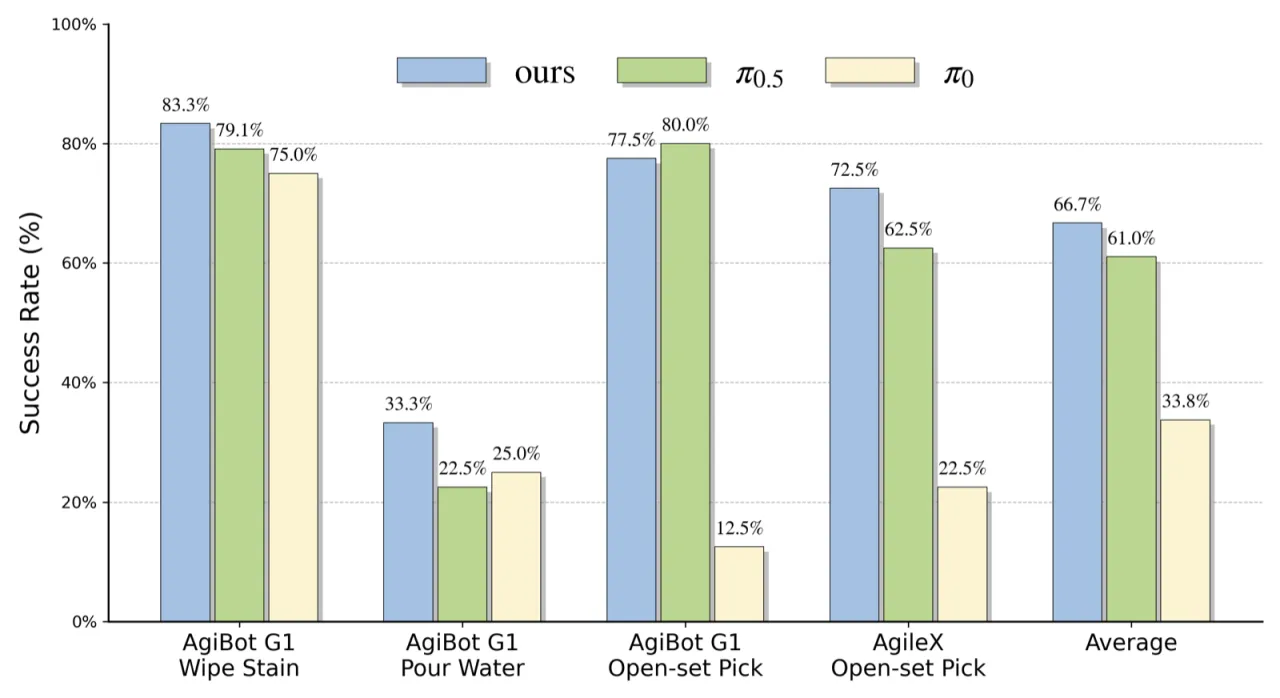
66.7%AgiBot G1 真实机器人成功率