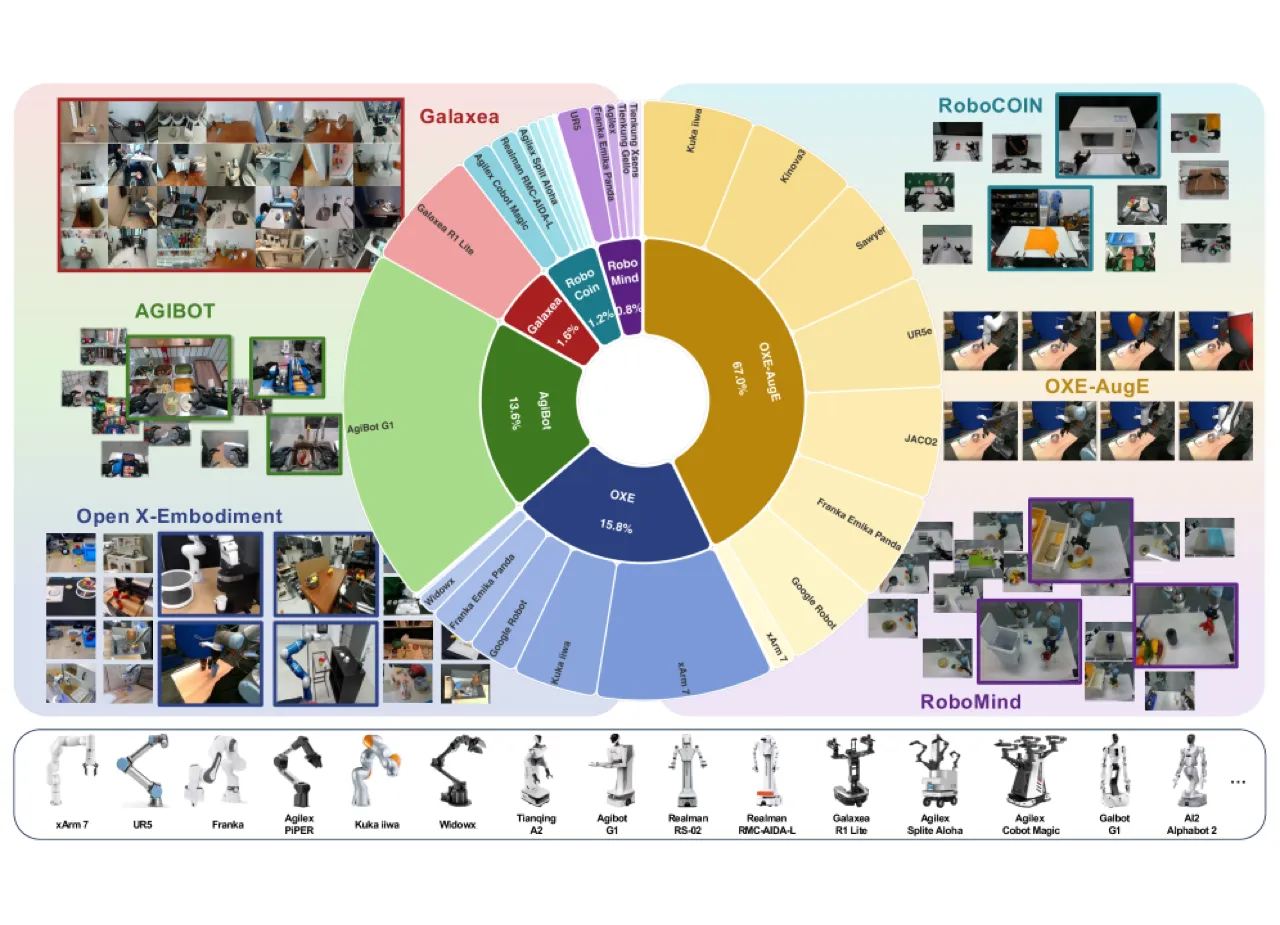
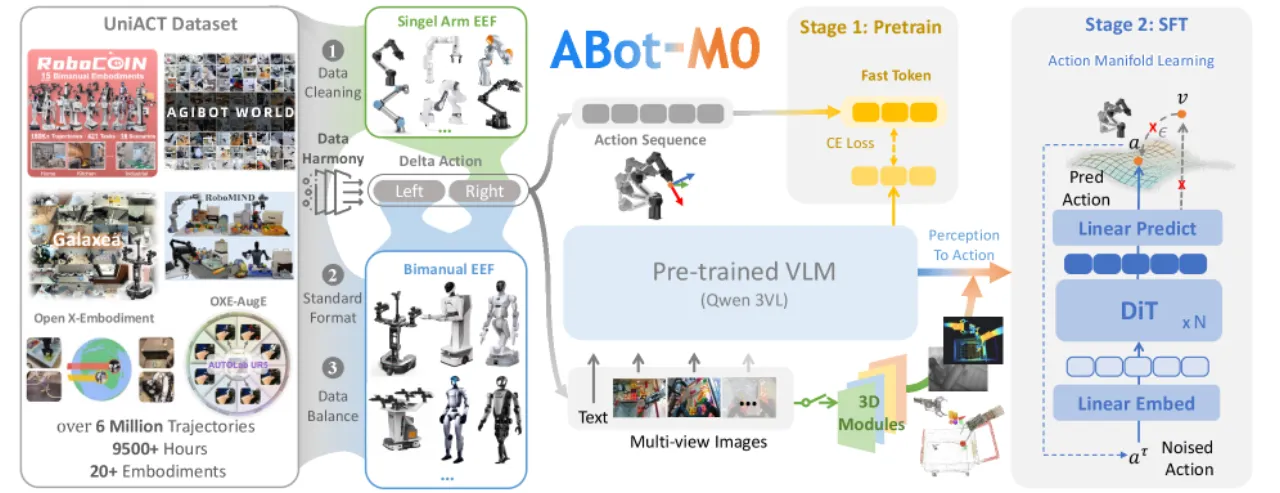
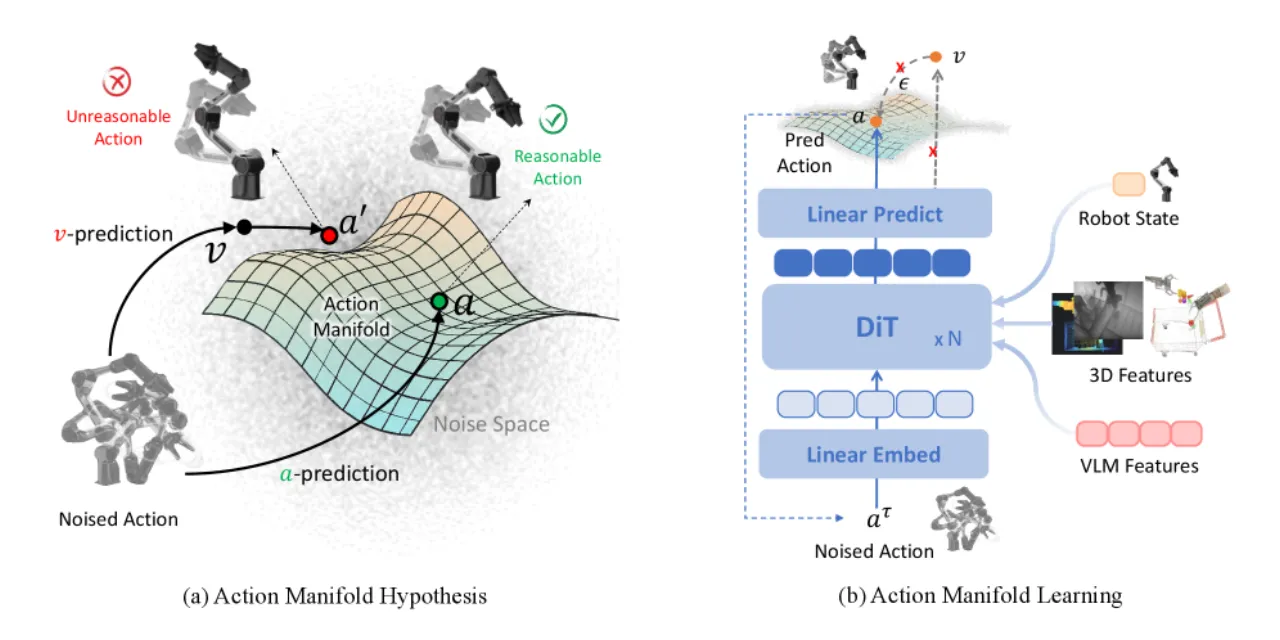
01 动机
构建真正通用的机器人智能体面临两大核心挑战:数据稀缺(跨形态、跨任务的高质量轨迹匮乏)与动作表示低效(高维噪声预测在速度和稳定性方面均有瓶颈)。现有 VLA 模型往往依赖单一数据源或特定硬件平台,泛化能力有限。
"effective robot actions lie not in the full high-dimensional space but on a low-dimensional, smooth manifold"
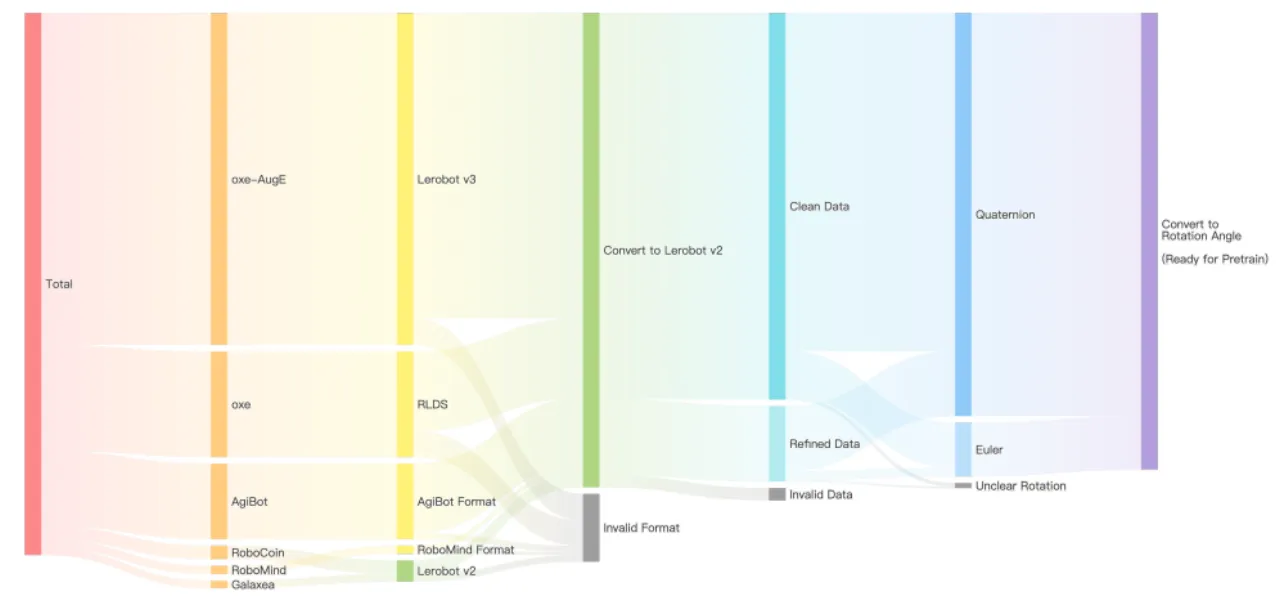
6M+UniACT 轨迹数
98.6%LIBERO 平均成功率
86.06%RoboTwin 2.0 成功率
80.5%LIBERO-Plus 零样本泛化