01 动机
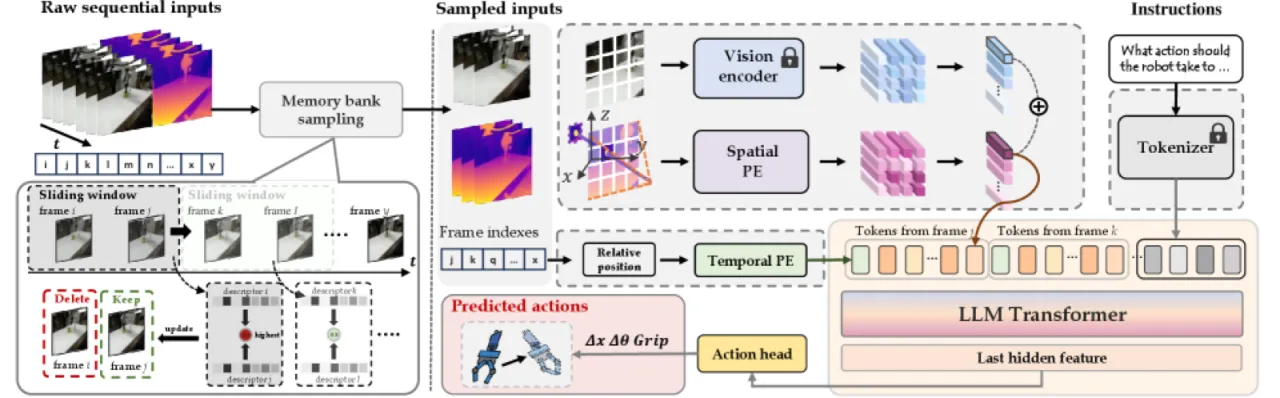
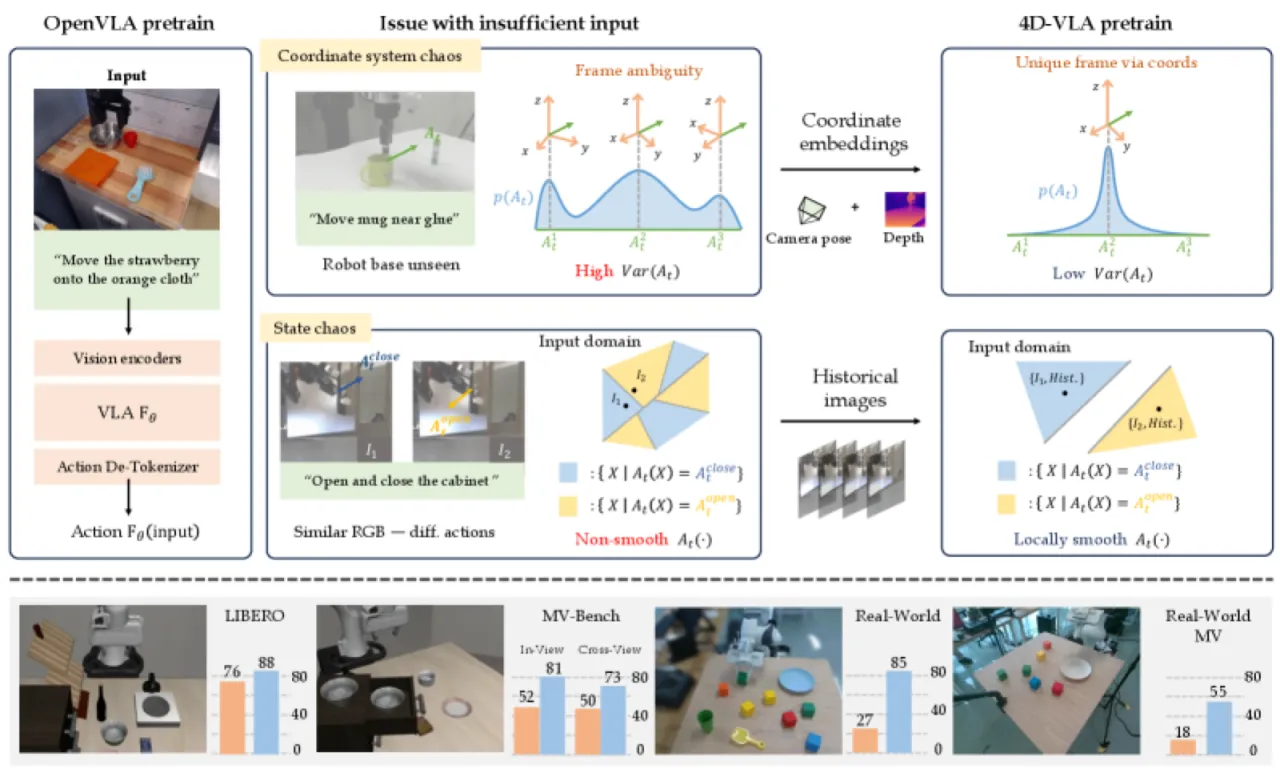
大规模机器人预训练的关键障碍:当把多个异构机器人数据集混合训练时,单帧 RGB 图像缺乏充足的空间与时序上下文,导致 action 分布极度分散,模型难以收敛。
坐标系混乱(Coordinate System Chaos)
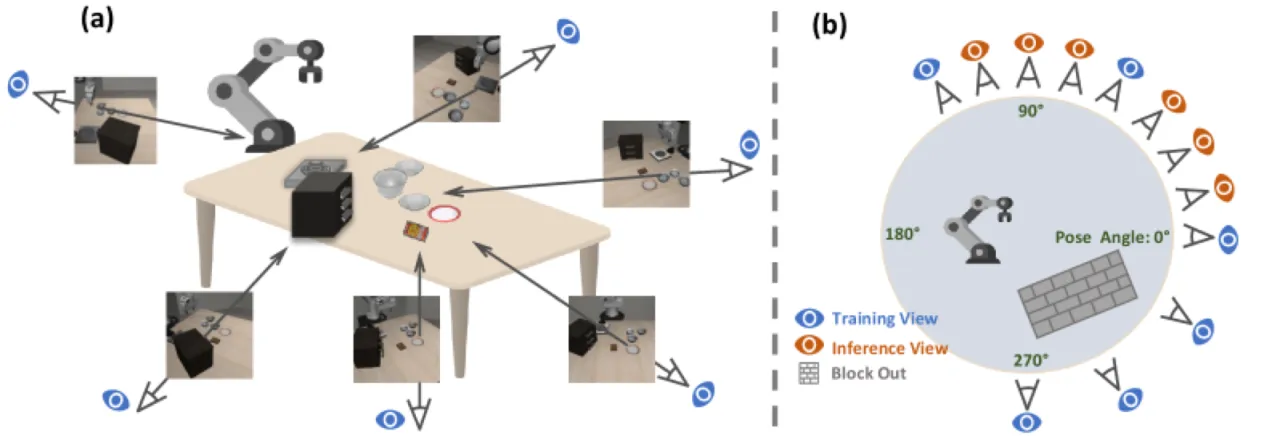
动作定义在机器人坐标系中,而视觉输入缺乏足够的空间上下文。论文指出:"if the image does not fully capture the robot's body, it becomes challenging to infer the robot's exact position and orientation." 不同相机外参与内参使得同一动作在不同数据集中的视觉表征截然不同。
状态混乱(State Chaos)
单帧图像缺少必要的时序与上下文线索以消除动作歧义。论文指出这包括"symmetric trajectories——where it is difficult to infer the direction of motion",以及"visually similar observations correspond to entirely different actions"的情形,使得模型对当前运动方向无法判断。
"We identify two primary factors contributing to incomplete input: coordinate system chaos and state chaos, both of which severely limit the training efficiency achievable with diverse robotic datasets."
88.6%LIBERO Avg(±0.3)
+12.1ppvs OpenVLA (76.5%)
85.63%真实操作 Full Model
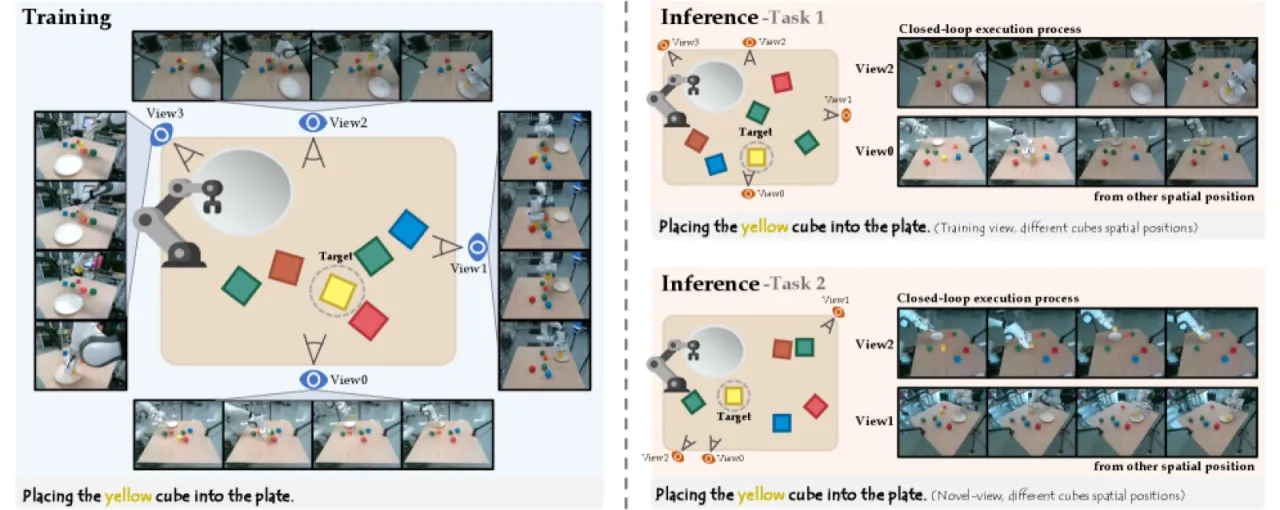
81.0%MV-Bench In-View Avg