01 动机
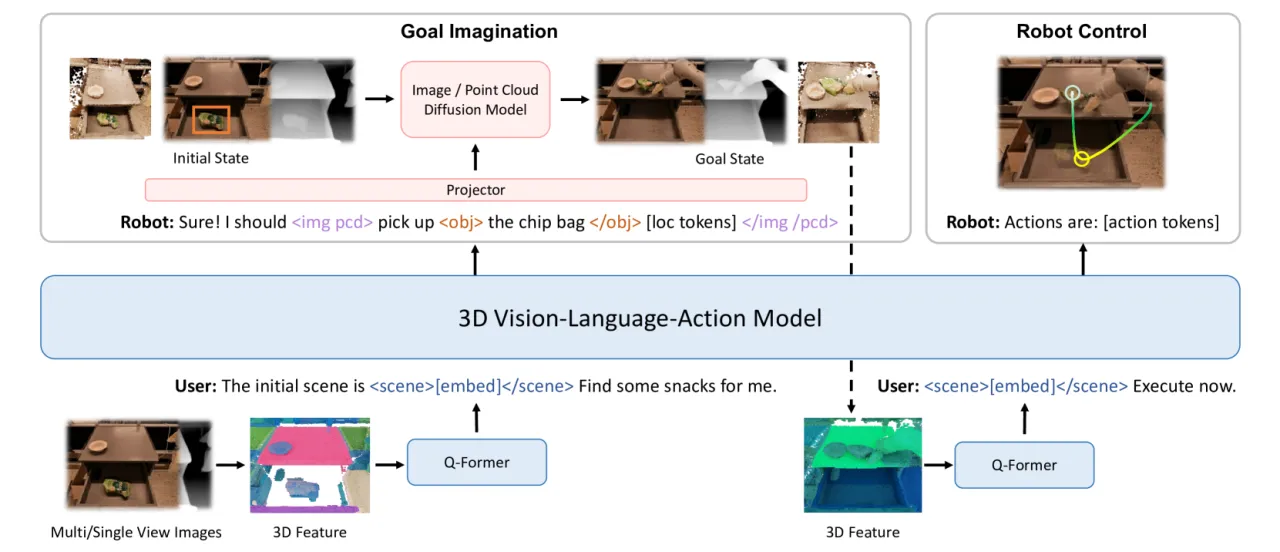
现有视觉-语言-动作(VLA)模型依赖二维输入,无法充分理解物理世界的三维结构;同时,它们直接从感知映射到动作,缺乏对世界动态的更广泛理解——即世界模型能力的缺失。
"Current embodied models learn a direct mapping from perception to action, devoid of a broader understanding of the dynamics of the world."
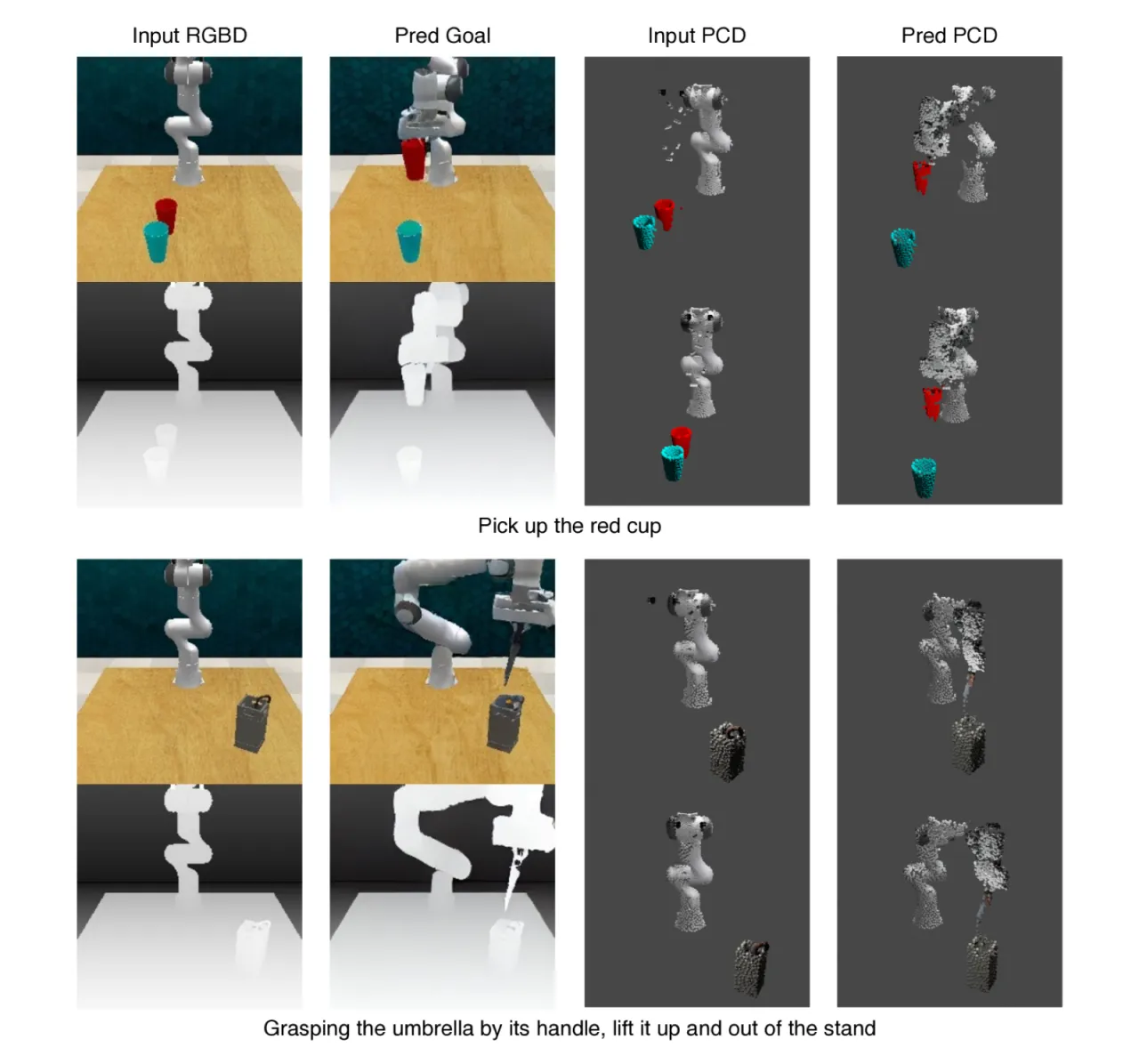
人类在行动前会在脑海中想象执行结果:拿起一杯水后,杯子的位置会如何变化?3D-VLA 正是赋予模型这种想象力——通过生成目标图像和目标点云来显式建模操作后的场景变化,进而指导机器人规划。

2M3D-language-action 数据对
316k总 episode 数
12Open-X Embodiment 子数据集
68%RLBench Put Knife 成功率