01 动机
VLA 模型通过端到端训练将视觉感知、语言理解和动作生成统一起来,在分布内任务上表现优秀,但面对新场景时泛化能力不足。现有方法主要依赖二维 RGB 感知,缺乏三维空间理解,导致机器人在复杂操作任务中难以推广到未见过的任务组合。
"Integrating reasoning within VLA training objectives can improve out-of-domain performance." — 论文核心主张
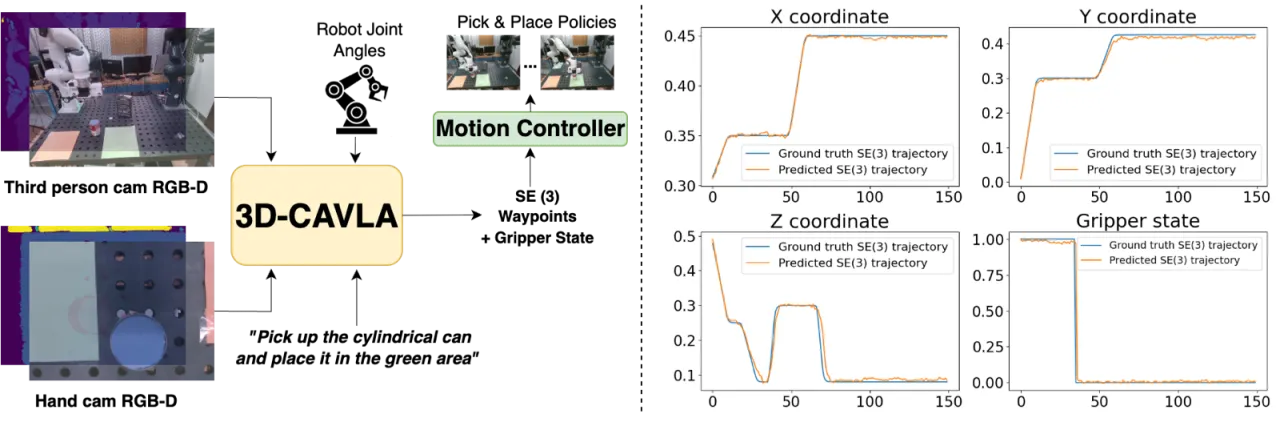
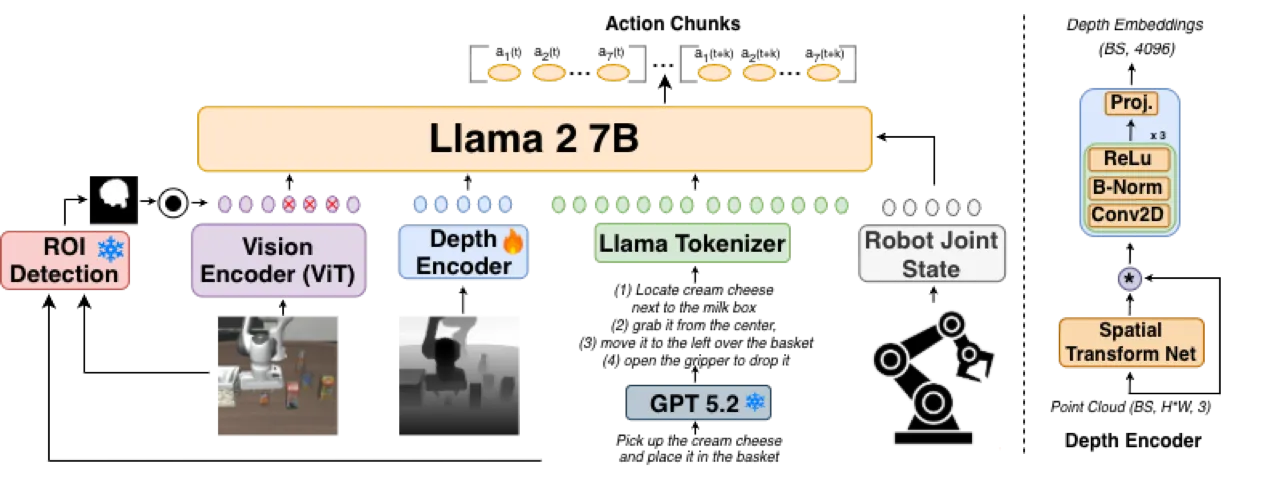
作者提出三个核心问题:(1)如何将结构化推理引入 VLA 训练目标?(2)如何利用深度信息增强三维空间感知?(3)如何让模型聚焦于任务相关的视觉区域?3D CAVLA 通过 chain-of-thought 推理分解、深度点云嵌入和 TA-ROI 池化三管齐下,系统性地解决上述挑战,且无需重设计基础架构,以 LoRA 微调方式即可叠加到现有 VLA 模型上。
98.1%LIBERO 分布内任务平均成功率(双摄像头 + 深度)
+8.8%未见任务绝对成功率提升(vs. OpenVLA-OFT)
+25%真实机器人未见任务成功率提升
3×训练收敛速度提升(3K vs. 10K epochs)